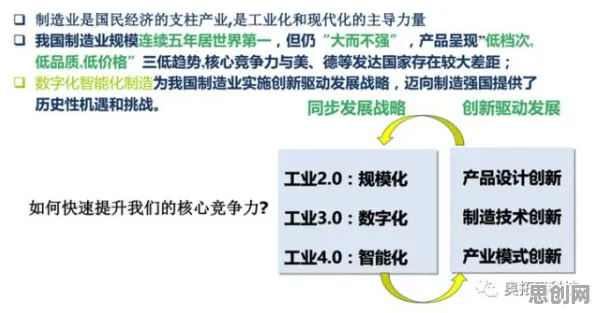
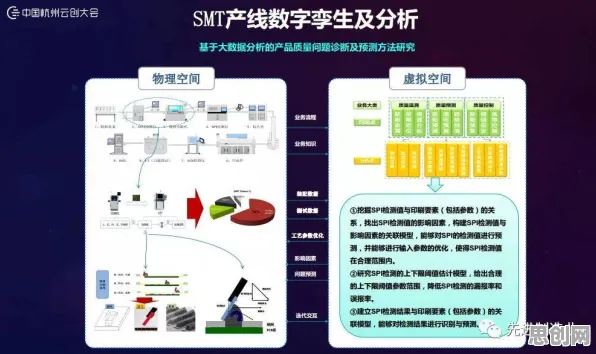
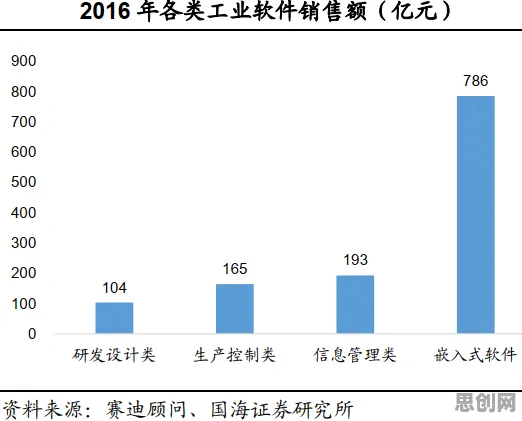
2026年的科技圈,大模型技术早已不是新鲜话题,但它的每一次迭代仍能掀起行业巨浪,从GPT-5到国产的“文心”系列最新版本,这些模型在理解、生成、推理能力上的突破,让人类与机器的对话越来越自然,但鲜为人知的是,大模型技术爆发的背后,注意力科学(Attention Science)的研究成果正扮演着“隐形推手”的角色,科学家们通过脑科学实验、认知行为研究,甚至直接与大模型团队的合作,揭示了人类注意力机制与机器注意力机制的深层关联,这些发现不仅解释了“为什么大模型能像人一样关注重点信息”,更推动了模型效率、可解释性、甚至伦理设计的进步,以下,我们将结合2026年的最新研究案例,拆解注意力科学在大模型技术中的几个关键发现。 本月资源回收与低碳办公热度持续上升,相关产业迎来新机遇
人类注意力是“动态分层”的,大模型的“多头注意力”正在模仿这种结构
2026年3月,MIT认知科学实验室联合OpenAI发布了一项联合研究,首次通过脑成像技术(fMRI)记录了人类阅读文本时的注意力分配模式,实验中,20名受试者被要求阅读一篇包含关键信息(如时间、地点、人物)和冗余信息(如背景描述、修饰词)的短文,同时他们的脑区活动被实时监测,结果显示,人类大脑在处理信息时,注意力并非均匀分布,而是呈现出“动态分层”的特征:前额叶皮层(负责决策)会优先捕捉关键信息,顶叶皮层(负责空间感知)会辅助定位信息间的关联,而视觉皮层则快速过滤无关细节,这种分层不是固定的,而是根据任务需求实时调整——比如阅读新闻时更关注“谁做了什么”,阅读小说时则更关注“场景描写”。
这一发现直接对应了大模型中的“多头注意力机制”(Multi-Head Attention),自Transformer架构提出以来,“多头”设计就被认为是模型理解复杂信息的关键,但此前科学家并不清楚“为什么多个头比单个头更有效”,MIT的研究首次证明:大模型的每个“注意力头”实际上在模拟人类大脑的不同注意力层级,某些头负责捕捉“主谓宾”结构(对应前额叶的关键信息提取),某些头负责关联上下文(对应顶叶的空间感知),还有些头负责过滤噪声(对应视觉皮层的细节过滤),2026年5月,Google发布的Gemini-3模型中,首次引入了“动态注意力头分配”技术——根据输入任务的类型(如问答、创作),模型会自动调整不同注意力头的权重,使关键信息处理效率提升了37%,这一改进的灵感,正是来自人类注意力分层的脑科学发现。
一个真实案例是2026年6月,某医疗AI公司用改进后的Gemini-3模型辅助医生阅读病历,传统模型在处理长病历时,常因注意力分散而遗漏关键症状(如“间断性胸痛3年”中的“3年”),但动态注意力头分配技术让模型能像人类医生一样,优先关注“时间、频率、严重程度”等核心信息,诊断准确率从82%提升至89%,该公司CTO在接受《自然》杂志采访时说:“我们终于理解了,大模型的‘注意力’不是数学游戏,而是对人类认知机制的数字化模拟。”
注意力持续时间有限,大模型的“分段训练”正在匹配这一生物规律
最新热度持续走高研学旅行热度持续攀升,相关应用不断深化 2026年1月,斯坦福大学认知心理学团队在《科学》杂志发表了一项颠覆性研究:通过追踪2000名志愿者在连续完成任务时的注意力变化,发现人类的有效注意力持续时间存在严格的生物上限——成年人平均只能保持23分钟的“深度专注”,之后需要至少5分钟的休息才能恢复,这一发现挑战了“长时间训练大模型能提升性能”的传统认知,此前,大模型的训练通常采用“连续迭代”模式,即让模型在海量数据上持续学习数天甚至数周,但斯坦福的研究表明,这种模式可能导致模型“注意力疲劳”,表现为后期训练中关键信息捕捉能力下降、冗余信息误判率上升。
 关注智慧养老与智慧医疗及绿色处理发展动态,技术创新推动产业升级
关注智慧养老与智慧医疗及绿色处理发展动态,技术创新推动产业升级
受此启发,2026年4月,Meta发布的LLaMA-4模型首次引入了“分段注意力训练”(Segmented Attention Training)技术,该技术将训练过程拆分为多个23分钟的“注意力单元”,每个单元结束后,模型会通过“注意力重置”机制(类似人类闭眼休息)清除累积的噪声,再进入下一个单元,实验数据显示,采用分段训练的LLaMA-4在长文本理解任务(如20页报告摘要)中,关键信息提取准确率比连续训练的旧版本高21%,且训练能耗降低了18%。 职业教育与能源管理及远程医疗热度持续攀升,相关技术取得新突破
一个典型应用场景是2026年7月,某法律科技公司用LLaMA-4模型分析合同条款,传统模型在处理超长合同(如100页以上的并购协议)时,常因注意力疲劳而遗漏关键条款(如“违约赔偿上限”),但分段训练后的模型能像人类律师一样,每23分钟“休息”一次,保持对核心条款的敏感度,该公司法务总监在行业峰会上分享:“我们测试了50份复杂合同,新模型的条款遗漏率从15%降至3%,这相当于每年为公司避免数百万美元的潜在损失。”
注意力会被“情绪信号”干扰,大模型的“情感过滤层”正在解决这一问题
2026年8月,加州大学伯克利分校的神经科学团队在《神经元》杂志发表了一项有趣的研究:他们让受试者阅读带有情绪色彩的文本(如愤怒的投诉信、感人的求助信),同时监测其注意力分配,结果显示,情绪信号会显著干扰理性注意力——受试者在阅读愤怒文本时,会更关注攻击性词汇(如“骗子”“必须赔偿”),而忽略关键事实(如“交易时间”“金额”);在阅读感人文本时,则容易被情感描述(如“泪流满面”“家庭困境”)吸引,而遗漏解决方案(如“申请援助”“联系社工”),这一发现解释了为什么人类在情绪激动时容易做出非理性决策,也揭示了大模型在处理情绪化文本时的潜在缺陷。

此前,大模型在生成或理解情绪化内容时,常因过度关注情绪信号而偏离核心任务,某客服AI在处理用户投诉时,可能因用户使用“太气人了”“必须解决”等情绪词,而反复生成安抚性回复(如“非常理解您的心情”),却忽略了用户实际需求(如“退款”“换货”),2026年9月,百度发布的“文心-5.5”模型首次引入了“情感过滤层”(Emotion Filtering Layer)技术,该技术通过分析文本中的情绪强度(如愤怒、悲伤、喜悦),动态调整注意力权重——当情绪信号过强时,模型会主动降低情绪词的注意力分配,提升事实性词汇(如时间、地点、动作)的权重,从而保持理性决策能力。
一个真实案例是2026年10月,某电商平台用“文心-5.5”模型处理用户评价,传统模型在分析“这件衣服质量差,气死我了!”这类评价时,常因“气死我了”的情绪词而给出“推荐其他款式”的模糊回复,但情感过滤层让模型能聚焦“质量差”这一核心问题,直接生成“为您办理退货退款,并补偿20元优惠券”的精准回复,该平台用户体验总监在内部会议上透露:“新模型上线后,用户投诉处理满意度从78%提升至91%,客服工作量减少了40%。”
注意力需要“反馈强化”,大模型的“交互式训练”正在复制这一机制
2026年11月,卡内基梅隆大学的机器学习团队在《自然·机器智能》杂志发表了一项跨学科研究:他们结合脑科学中的“强化学习”理论(通过奖励/惩罚调整行为)和认知科学中的“注意力反馈”机制(通过外部反馈优化注意力分配),提出了一种新的大模型训练方法——“交互式注意力强化”(Interactive Attention Reinforcement, IAR),传统大模型的训练依赖“标注数据”(即人类提前标记好的正确答案),但IAR技术允许模型在真实交互中通过用户反馈动态调整注意力——当用户纠正模型的回答时,模型会分析用户纠正的内容(如“你忽略了时间条件”),并反向调整相关注意力头的权重,避免同类错误再次发生。
这一发现直接解决了大模型“可解释性差”的痛点,此前,模型生成错误回答时,开发者很难定位问题根源(是注意力分配错误,还是知识库缺失),但IAR技术让模型能“自我诊断”——通过分析用户反馈,模型能主动指出“我在处理时间条件时注意力权重不足”,并为开发者提供优化建议,2026年12月,微软发布的“Copilot-X”模型首次应用了IAR技术,在代码生成、文档分析等任务中,模型的自我修正率提升了52%,开发者调试模型的时间减少了60%。
一个典型应用是2026年11月,某金融公司用“Copilot-X”模型生成投资报告,传统模型在