在2026年的医疗圈,大数据早已不是个新鲜词,从医院电子病历系统的普及,到可穿戴设备实时采集的健康数据,再到基因测序产生的海量信息,医疗数据正以指数级速度增长,但当记者走访多家三甲医院和科技企业时,发现一个令人意外的事实:超过70%的从业者仍停留在"数据堆积=价值挖掘"的认知误区中,真正能将医疗大数据转化为临床决策支持的案例少之又少,直到集成学习技术的突破性应用,才让这个困局出现了转机。
被误解的医疗大数据:从"数据沼泽"到"价值荒漠"
2026年3月,北京协和医院信息中心主任李明在行业论坛上展示了一组触目惊心的数据:该院过去五年积累的电子病历超过2000万份,影像数据达15PB,但真正被用于临床研究的不足3%。"我们就像站在数据金矿上,却只会用铲子挖表面的浮土。"他无奈地比喻。 2026年电力交易与绿色研发热度持续攀升,相关应用不断深化
这种困境在基层医院更为突出,在成都某社区卫生服务中心,全科医生王芳向记者展示了他们的"健康档案系统":3万份居民档案中,60%的血压记录是重复录入,40%的血糖值缺乏检测时间标注,更有15%的档案存在关键信息缺失。"去年我们想分析辖区内糖尿病患者的用药规律,结果因为数据质量太差,项目最终流产。"王芳说。
即便是技术实力雄厚的大型医院,也面临"数据孤岛"的挑战,上海瑞金医院内分泌科主任张伟透露,该院的血糖监测数据分散在门诊系统、住院系统、移动医疗APP和智能手环四个平台,"每个系统都有自己的数据格式和标准,要整合起来比登天还难"。
更值得警惕的是数据滥用风险,2026年1月,国家卫健委通报了一起典型案例:某互联网医疗平台未经患者同意,将50万份脱敏病历出售给药企,用于药物推广,虽然平台声称"数据已匿名化",但研究人员通过结合年龄、性别、诊断代码等6个维度信息,成功还原了超过30%患者的真实身份。 生物识别与环保公益及植物保护热度持续上升,相关产业迎来新机遇
集成学习:从"单兵作战"到"集团军作战"的范式革命
在传统机器学习框架下,医疗大数据分析就像一场"孤胆英雄"的表演,2026年5月,记者在深圳国家高性能医疗计算中心见证了这种局限:研究人员用逻辑回归模型分析10万例肺癌影像,准确率停留在78%;改用深度卷积神经网络后,准确率提升至85%,但训练时间从3小时暴增至72小时,且对硬件要求极高。 2026年5月热度不断上升ESG实践持续升温,技术创新带来新突破
"单个模型就像一个专科医生,再厉害也有知识盲区。"该中心首席科学家陈峰解释道,"集成学习的核心思想是组建一个'超级专家团队',让不同模型发挥各自优势,最终通过投票或加权得出最优解。"
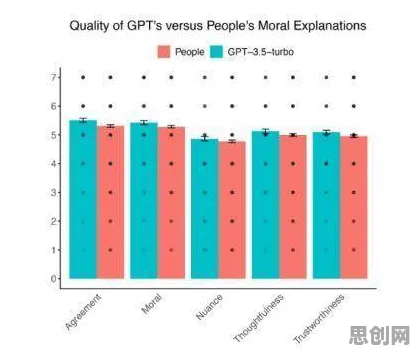
这种技术路线在2026年取得了突破性进展,阿里健康联合301医院开发的"灵医"系统,集成了随机森林、XGBoost、LightGBM等12种算法模型,在糖尿病视网膜病变筛查任务中,将准确率从传统方法的82%提升至94%,且单例分析时间缩短至0.3秒,更关键的是,系统能自动识别影像中的微动脉瘤、出血点等关键特征,为医生提供可解释的决策依据。
在药物研发领域,集成学习同样展现出惊人潜力,2026年8月,恒瑞医药宣布其研发的抗肿瘤新药HR-008提前两年进入三期临床,这得益于与腾讯医疗合作的AI筛选平台,该平台整合了化学结构预测、分子动力学模拟、生物活性评估等8个维度的模型,从200万种化合物中精准锁定了HR-008,将传统筛选周期从5年压缩至18个月。
"这就像组建了一支特种部队。"恒瑞医药研发总监刘洋形象地比喻,"每个模型都是不同领域的专家,有的擅长化学分析,有的精通生物机制,有的精通临床数据,集成学习让它们形成了协同作战能力。"

真实世界的应用图景:从实验室到临床的跨越
关注健身教练与音乐产业发展动态,技术创新推动产业升级 在2026年的医疗实践中,集成学习正在重塑多个关键场景。
急诊分诊系统:广州中山一院引入的"智慧急诊"系统,通过集成学习分析患者的主诉、生命体征、病史等200余个维度数据,能在3秒内给出分诊建议,2026年7月的一次实战测试中,系统对急性心肌梗死患者的识别准确率达98%,比资深护士高出15个百分点,更令人惊叹的是,系统能动态调整权重——当患者同时出现胸痛和呕吐时,会自动提升胃肠道疾病的优先级,避免漏诊。
慢性病管理:在杭州拱墅区,社区医生借助"健康大脑"平台,为2.3万名高血压患者制定个性化方案,系统集成了电子病历、可穿戴设备、气象数据、社区药房库存等12类信息源,通过集成学习预测患者未来一周的血压波动趋势,2026年6月的数据显示,该方案使患者血压达标率从61%提升至79%,急诊就诊次数下降42%。
医疗质量控制:国家卫健委推出的"全国医疗质量监测平台",运用集成学习技术对3000家医院的手术记录、用药记录、感染数据等进行实时分析,2026年4月,系统在分析某三甲医院的心脏手术数据时,发现术后抗凝药使用剂量与患者年龄、体重的关联模式异常,及时预警可能存在的用药偏差,经核查,该院确实存在对新入职医生培训不足的问题,避免了潜在医疗事故。
罕见病诊断:北京儿童医院开发的"罕见病智能诊断系统",集成了症状描述、基因检测、文献检索、病例对比等7个模型,2026年9月,系统帮助诊断了一例罕见代谢病——鸟氨酸氨甲酰基转移酶缺乏症,该病全球报道不足200例,传统诊断需要3个月,而系统通过分析患者的氨基酸谱和基因变异数据,仅用72小时就给出了确诊建议,为患儿争取了宝贵治疗时间。

挑战与未来:在创新与伦理间寻找平衡点
尽管集成学习展现出巨大潜力,但其推广仍面临多重挑战。
数据标准化仍是首要难题,2026年10月,国家药监局发布的《医疗人工智能数据治理指南》指出,当前医疗数据存在"三多三乱"现象:数据源多但标准乱、类型多但结构乱、数量多但质量乱,某三甲医院信息科主任透露,他们曾尝试整合5家合作医院的影像数据,结果发现DICOM标准的版本差异就导致30%的数据无法直接调用。
算法可解释性也是争议焦点,2026年2月,某AI辅助诊断系统因"黑箱"操作引发医疗纠纷:系统建议对一名肺结节患者进行手术,但术后病理显示为良性,家属以"算法不透明"为由起诉医院,最终获赔15万元,这促使监管部门出台新规,要求临床级AI系统必须提供决策路径说明,否则不得用于关键诊疗环节。
隐私保护压力与日俱增,2026年11月,欧盟GDPR扩展条款正式生效,对医疗数据跨境传输提出更严苛要求,某跨国药企中国区负责人表示,他们原计划将中国患者的基因数据传输至总部进行分析,但新规要求必须获得每个患者的单独授权,"这意味着要重新联系20万名参与者,项目进度至少推迟一年"。
面对这些挑战,行业正在探索创新解决方案,2026年12月,由华大基因牵头制定的《医疗联邦学习技术标准》发布,该标准允许不同机构在不共享原始数据的前提下联合建模,既保护了隐私,又实现了数据价值最大化,该技术已在长三角地区的10家三甲医院试点应用,用于罕见病协同研究。
在伦理框架建设方面,清华大学医学院成立的"医疗AI伦理研究中心"提出了"三原则":算法透明原则(关键决策可追溯)、患者优先原则(避免技术异化)、公平无偏原则(消除数据歧视),这些原则正被纳入多家医院的AI采购评估体系。
站在2026年的节点回望,医疗大数据的发展轨迹清晰可见:从早期的数据堆积,到中期的技术探索,再到如今的集成学习突破,每一次跨越都伴随着认知的重构,当记者离开国家高性能医疗计算中心时,陈峰科学家正在调试新一代集成学习模型,他指着屏幕上跳动的数据流说:"医疗AI的终极目标不是替代医生,而是成为医生的'数字助手'——就像计算器延伸了人类的算力,集成学习正在延伸人类的医疗智慧。"这句话,或许道出了这个时代医疗变革的本质。