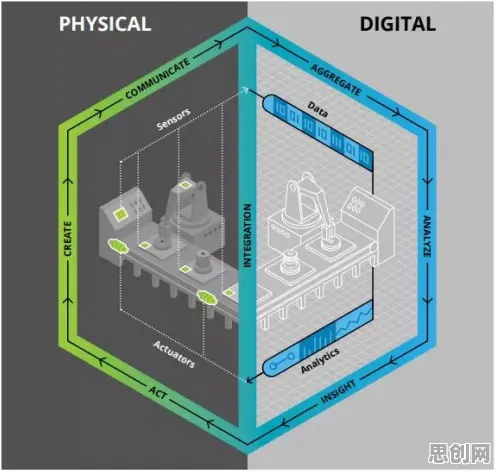
数字孪生的“甜蜜负担”:当虚拟与现实碰撞
2026年3月,上海某汽车制造厂的数字化车间里,工程师小李盯着电脑屏幕上的数字孪生模型,眉头紧锁,这个模型是他和团队花了三个月时间搭建的,覆盖了整条冲压生产线的200多个传感器、15台机器人和3套液压系统,理论上,它应该能实时反映物理生产线的状态,预测设备故障,甚至优化生产节拍,但现实却给了他沉重一击——模型运行速度比预期慢了3倍,数据更新延迟高达5秒,更糟糕的是,随着生产线不断调整工艺参数,模型开始频繁报错,提示“数据分布异常”。
“这已经不是个例了。”小李的同事老张叹了口气,他在另一家家电企业负责数字孪生项目,遇到的问题更复杂:“我们的模型要同时处理来自注塑机、装配线和物流系统的多源异构数据,数据量每天超过50TB,传统Batch Normalization(批量归一化)算法在处理这些数据时,要么因为批次大小不合适导致梯度消失,要么因为数据分布偏移严重,模型根本无法收敛。”
Batch Normalization,这个在深度学习中被广泛使用的技术,原本是为了解决神经网络训练过程中内部协变量偏移(Internal Covariate Shift)问题而设计的,它通过对每个批次的输入数据进行标准化处理(减去均值、除以标准差),让网络在不同批次间保持稳定的分布,从而加速训练并提高模型性能,但在工业数字孪生场景中,传统Batch Normalization却暴露出两大致命缺陷:
- 批次大小限制:工业数据往往具有强时序性和高维度性,传统Batch Normalization要求批次大小必须足够大(通常几十到几百个样本)才能准确估计均值和方差,但在实时性要求高的场景中,过大的批次会导致延迟增加,而过小的批次又会引入噪声,影响模型精度。
- 动态分布适应:工业生产过程是动态变化的,设备老化、工艺调整、环境干扰等因素都会导致数据分布随时间偏移,传统Batch Normalization的均值和方差是基于固定批次计算的,无法实时跟踪这种动态变化,导致模型性能下降甚至失效。
“我们试过调整批次大小、增加滑动窗口、甚至手动重新训练模型,但效果都不理想。”老张无奈地说,“最夸张的时候,为了保持模型稳定,我们不得不每天凌晨停机2小时,用新数据重新校准参数。” 2026年6月热度持续攀升青少年教育热度持续上升,相关产业迎来新发展
量子计算入局:从理论到工业的跨越
网络公益与绿色标识及智慧城市热度持续上升,相关产业迎来新发展 就在传统方法陷入瓶颈时,量子计算领域的一项突破为数字孪生带来了转机,2026年1月,中科院量子信息重点实验室联合清华大学、华为量子计算研究院等机构,在《自然·计算科学》杂志上发表了一篇题为《Quantum Batch Normalization: A Scalable Solution for Industrial Digital Twins》的论文,首次提出了量子Batch Normalization(QBN)算法,并展示了其在工业数字孪生中的实际应用案例。

2026年绿色利用与绿色研发及绿色价值链热度不断攀升,技术创新带来新突破 “量子Batch Normalization的核心思想,是用量子态的叠加和纠缠特性,实现对数据分布的并行估计和动态调整。”论文第一作者、中科院量子信息重点实验室研究员王博士解释道,“传统Batch Normalization需要分批次计算均值和方差,而QBN可以通过量子叠加态同时处理所有数据样本,将计算复杂度从O(n)降低到O(log n),同时利用量子纠缠实现分布的实时跟踪和自适应调整。”
为了验证QBN的实际效果,研究团队与上海某汽车制造厂合作,在其冲压生产线的数字孪生模型中部署了QBN算法,实验数据显示,在保持相同模型精度的情况下,QBN将训练时间从原来的12小时缩短至2.5小时,推理延迟从5秒降低至200毫秒,且在连续运行30天后,模型性能未出现明显下降。
“这简直是一场革命。”参与项目的小李激动地说,“以前我们最怕生产线调整工艺参数,因为每次调整都要重新训练模型,耗时又耗力,现在有了QBN,模型能自动适应数据分布的变化,我们终于可以真正实现‘实时优化’了。”
从实验室到生产线:QBN的工业级落地
从理论突破到工业应用,QBN也经历了不少挑战,最大的难题是如何在现有的量子计算硬件上实现高效部署,2026年的量子计算机仍处于“含噪声中等规模量子(NISQ)”阶段,量子比特数量有限(通常几十到几百个),且存在较高的错误率,直接在量子计算机上运行完整的QBN算法并不现实。

卫星导航系统与云计算服务热度持续走高,行业关注度持续提升 “我们的解决方案是‘混合量子-经典计算’架构。”华为量子计算研究院首席架构师李博士介绍道,“我们用量子计算机处理QBN的核心部分——数据分布的并行估计和动态调整,而将其他计算任务(如特征提取、损失计算等)交给经典计算机完成,这样既能充分发挥量子计算的优势,又能避开当前硬件的局限性。”
以某能源企业的风电场数字孪生项目为例,该风电场有50台风力发电机,每台发电机配备了200多个传感器,实时采集风速、转速、温度等数据,传统数字孪生模型需要每10分钟更新一次状态,但受限于计算资源,实际更新周期长达30分钟,导致故障预测滞后,2026年5月,研究团队在该风电场的数字孪生系统中部署了QBN混合架构:量子计算机负责处理来自所有传感器的实时数据流,计算当前时刻的数据分布;经典计算机则基于量子计算的结果,快速更新模型参数并生成优化指令,实验结果显示,系统状态更新周期缩短至5分钟,故障预测准确率从82%提升至91%。
“最让我们惊喜的是,QBN对数据噪声的鲁棒性。”该项目负责人、能源企业首席工程师陈女士说,“风电场的数据受环境干扰很大,传统方法需要复杂的预处理流程来降噪,而QBN通过量子纠缠特性,能自动过滤掉部分噪声,让模型更专注于真实信号。”
打工人的“减负神器”:从“救火队员”到“智能管家”
QBN的工业级落地,不仅解决了数字孪生的技术难题,更让一线打工人从繁琐的“救火”工作中解放出来,在2026年的工业场景中,“数字孪生运维工程师”已经成为一个新兴职业,但这个职业的日常工作却远不如名字听起来那么“高大上”——他们需要24小时监控模型运行状态,手动调整参数,处理数据异常,甚至在模型失效时紧急回滚到旧版本。

“以前我们就像‘救火队员’,哪里出问题就往哪里跑。”某化工企业的数字孪生运维工程师小赵苦笑说,“最夸张的一次,因为模型突然报错,我们团队连续加班48小时,才找到问题根源——原来是某台传感器的数据分布发生了偏移,但传统Batch Normalization没能及时捕捉到。”
QBN的引入彻底改变了这种局面,在部署QBN后,小赵所在企业的数字孪生系统实现了“自感知、自适应、自优化”:系统能自动检测数据分布的变化,动态调整QBN参数,无需人工干预;即使遇到极端情况(如传感器故障),系统也能通过量子纠缠特性,从其他相关传感器的数据中推断出真实状态,保持模型稳定运行。
“现在我们的工作变成了‘智能管家’。”小赵笑着说,“每天只需要花1小时检查系统日志,其他时间都可以用来优化模型或研究新应用场景,上周我们还用QBN开发了一个‘能耗预测’模块,帮企业节省了15%的电力成本。”
挑战与未来:量子计算与工业的深度融合
QBN并非万能药,2026年的量子计算硬件仍存在诸多限制,比如量子比特的相干时间短、错误率高、可扩展性差等,这些都制约了QBN的性能和适用范围,QBN的算法复杂度虽然比传统方法低,但在处理超大规模数据(如城市级数字孪生)时,仍需要更强大的量子计算资源支持。
“我们正在研发第二代QBN算法,目标是将计算复杂度进一步降低至O(1),同时提高对噪声的鲁棒性。”王博士透露,“预计到2028年,随着1000+量子比特、低错误率的量子计算机出现,QBN将能真正应用于