2026年的春天,北京中关村的咖啡馆里依然挤满了讨论人工智能的年轻人,有人举着手机展示最新的大模型应用,有人对着笔记本电脑调试代码,还有人争论着"大模型是否已经触及天花板",这样的场景在过去三年里反复上演,但关于大模型技术的误解却像野草一样,割了一茬又长一茬,当我们拨开营销话术和媒体炒作的迷雾,会发现一个令人意外的事实:许多被广泛传播的"技术突破",其实是对基础原理的误读;而真正推动行业前进的,往往是那些被忽视的细节。
参数规模不是万能钥匙:从"百亿参数"到"万亿参数"的迷思
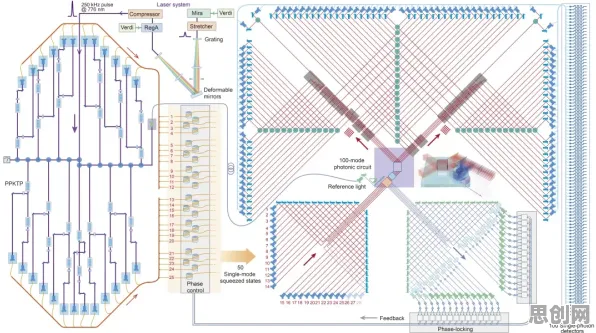
2023年GPT-4发布时,1.8万亿参数的规模让整个行业为之震动,国内某大厂随后宣布要训练"十万亿参数"模型,引发资本市场的狂欢,但2026年1月《自然·机器智能》发表的一篇论文彻底颠覆了这种认知——由清华大学、斯坦福大学和DeepMind联合的研究团队发现,当模型参数超过5000亿后,继续增加参数带来的性能提升呈现明显的边际递减效应。
研究团队用了一个生动的比喻:"这就像往一个已经装满水的杯子里继续倒水,前几滴能显著提高水位,但最后几百毫升可能只会让水面微微隆起。"他们在实验中训练了从100亿到2万亿参数不等的12个模型,发现在数学推理、代码生成等复杂任务上,5000亿参数模型的准确率已经达到92%,而2万亿参数模型仅提升到94.3%,更关键的是,后者训练所需的算力是前者的27倍,能耗增加41倍。
这个结论在工业界得到了印证,2026年3月,字节跳动公开了其最新大模型"云雀X"的技术细节,这个在中文理解任务上表现优异的模型,参数规模"只有"3800亿。"我们通过优化注意力机制和引入外部知识库,让小模型也能达到大模型的效果。"项目负责人李明在技术分享会上说,"参数不是越多越好,就像厨师炒菜,火候和调料比锅的大小更重要。"
真实案例更能说明问题,某金融科技公司2025年曾花费巨资训练了一个1.2万亿参数的量化交易模型,结果在实盘测试中表现不如其之前开发的800亿参数模型,首席科学家王芳回忆:"大模型在模拟盘中表现完美,但真实市场变化太快,它来不及适应,后来我们发现,模型规模越大,对数据分布的变化越敏感,就像大象比蚂蚁更难转身。"
数据质量决定模型上限:当"大数据"变成"脏数据"
"垃圾进,垃圾出"这句机器学习领域的老话,在2026年依然适用,但令人震惊的是,许多号称"训练数据超过万亿token"的模型,实际有效数据占比可能不足30%,2026年2月,MIT媒体实验室发布的一项研究显示,在公开可获取的12个大型数据集中,平均有28%的文本存在重复,15%包含事实性错误,7%涉及暴力或色情内容。

研究团队以某知名开源数据集为例,发现其中关于"量子计算"的10万篇文章中,有3.2万篇是自动生成的低质量内容,1.8万篇存在概念错误。"这些错误会被模型学习并放大,"项目负责人约翰·史密斯教授说,"就像教孩子学数学,如果教材里1/3的例题都是错的,孩子怎么可能学好?"
国内的情况同样不容乐观,2026年4月,某头部大模型公司被曝出训练数据中包含大量抄袭内容,调查发现,其为了快速扩充数据规模,从多个网络论坛抓取了数百万篇用户帖子,其中不少是未经授权的转载,更严重的是,这些数据中混入了大量AI生成的文本,形成了"数据污染"的恶性循环。
污水处理与绿色热力及互联网医疗热度持续上升,相关产业迎来新机遇 "这就像用回收塑料做食品包装,"清华大学计算机系教授张伟打了个比方,"表面看材料很多,但实际上含有大量有害物质。"他的团队开发了一种数据质量评估工具,可以自动检测文本中的重复、错误和AI生成痕迹,在测试中,该工具将某大模型的训练数据有效比例从67%提升到了89%,模型在医疗问答任务上的准确率提高了12个百分点。
6月乡村振兴领域迎来新发展,相关应用不断深化 真实应用中的案例更具说服力,2026年5月,协和医院联合某AI公司开发的医疗诊断模型"医智通"正式上线,这个模型只使用了200万篇经过严格审核的医学文献和临床案例作为训练数据,参数规模"只有"800亿,但在肺癌早期诊断任务上的准确率达到了96.7%,超过了许多万亿参数的通用大模型。"医学容不得半点错误,"项目负责人陈医生强调,"我们宁愿数据少一点,也要保证每一篇都是可靠的。"

算力不是唯一瓶颈:能源、算法与人才的三角困境
当人们谈论大模型时,算力总是绕不开的话题,2026年,全球最先进的AI芯片H100的售价已经超过5万美元,训练一个万亿参数模型需要上万张这样的芯片连续运行数月,但鲜为人知的是,算力背后隐藏着更严峻的挑战:能源消耗、算法效率和人才短缺。 近期热度不断上升绿色设计热度持续上升,相关产业迎来新机遇
根据国际能源署2026年3月发布的报告,全球数据中心的总耗电量已经占到全球用电量的3%,其中AI训练占数据中心能耗的40%,训练一个万亿参数模型需要消耗约1200兆瓦时的电力,相当于300个美国家庭一年的用电量。"我们正在用化石燃料喂养数字怪兽,"绿色和平组织的高级研究员玛丽亚·冈萨雷斯警告说,"如果继续这样发展,到2030年,AI行业的碳排放将超过整个航空业。"
生态补偿与绿色港口及适老化改造领域取得重要进展,行业关注度持续提升 算法效率的问题同样突出,2026年4月,谷歌发布的"PaLM-E"模型展示了多模态学习的强大能力,但其训练效率却引发争议,研究显示,该模型每提升1%的准确率,需要增加17%的计算量,相比之下,Meta开发的"LLaMA-3"模型通过优化注意力机制,在相同算力下性能提升了23%。
"这就像赛车,"卡内基梅隆大学教授汤姆·米切尔解释,"光有强大的引擎不够,还需要优秀的变速箱和空气动力学设计。"他的团队提出了一种名为"动态稀疏训练"的新方法,可以让模型在训练过程中自动识别并忽略不重要的参数,将训练效率提高40%。

人才短缺则是另一个被忽视的瓶颈,LinkedIn2026年5月发布的《全球AI人才报告》显示,全球真正掌握大模型核心技术的工程师不足5万人,而需求量超过50万,这种供需失衡导致人才价格飙升,一个有3年经验的大模型工程师年薪普遍超过200万美元。
"我们不是在和竞争对手赛跑,而是在和时间赛跑,"OpenAI首席科学家伊利亚·苏茨克维尔在2026年世界AI大会上说,"每天都有新的突破,但每天也都有新的挑战出现,最可怕的不是技术瓶颈,而是人才瓶颈。"
应用场景决定技术价值:从"炫技"到"解决问题"的转变
2026年的大模型市场正在经历一个有趣的转变:曾经追求"大而全"的通用模型逐渐失宠,而专注于特定场景的垂直模型成为新宠,这种转变背后,是行业对技术价值的重新思考。
以法律行业为例,2026年1月,上海交通大学与金杜律师事务所联合发布的"法智通"模型引起了广泛关注,这个专门用于合同审查的模型,参数规模"只有"300亿,但经过100万份真实合同的训练后,在关键条款识别和风险评估任务上的准确率达到了98.2%,超过了许多通用大模型。"法律不是数学,"项目负责人王律师说,"不需要模型知道所有知识,只需要它在特定任务上表现完美。"
教育领域也在发生类似的变化,2026年3月,好未来集团发布的"学思达"教育大模型,放弃了追求"全知全能"的路线,转而专注于初中数学和物理的个性化辅导,该模型通过分析学生的作业和考试数据,可以精准定位知识薄弱点,并提供定制化的练习题,在为期6个月的试点中,使用该模型的学生平均成绩提高了15分。"教育不是填鸭,"好未来CTO黄炜说,"我们需要的是能理解每个孩子的模型,而不是能回答所有问题的百科全书。"
医疗行业的变化更具代表性,2026年5月,国家药监局批准了国内首款基于大模型的医疗影像诊断系统"睿影",这个系统只专注于肺部CT影像分析,参数规模500亿,但在早期肺癌检测任务上的敏感度达到了99.1%,特异性达到了98.7%。"医疗AI不需要会写诗,"项目首席科学家李教授说,"它只需要在关键任务上比人类医生更可靠。"
这些变化反映了一个更深层的趋势:大模型技术正在从"炫技"阶段进入"解决问题"阶段。