知识点一:记忆的“编码-存储-提取”机制,决定了数字孪生体的数据基础必须“全息化”
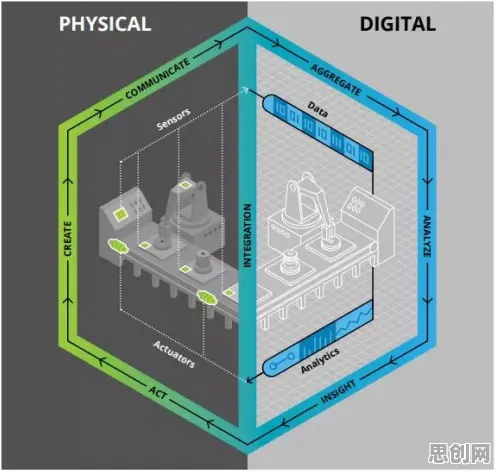
记忆科学中,信息从感知到长期存储需要经历编码(将外部刺激转化为神经信号)、存储(在大脑皮层形成稳定连接)和提取(通过线索唤醒记忆)三个阶段,数字孪生体的构建逻辑与之高度相似:它需要将物理实体的所有关键信息(如温度、振动、应力、能耗等)进行“全息编码”,通过传感器网络实时采集数据,在虚拟空间中构建与实体完全对应的“数字记忆体”,并在需要时(如故障预测、工艺优化)快速提取相关数据进行分析。
2026年,三一重工的“灯塔工厂”提供了一个典型案例,其生产的混凝土泵车,每台设备上安装了超过200个传感器,实时采集液压系统压力、臂架振动频率、发动机转速等数据,这些数据通过5G网络传输至云端,在数字孪生平台上构建出每台泵车的“数字分身”,当某台设备的液压系统压力突然升高时,系统不仅能立即调取该设备过去30天的压力变化曲线(记忆提取),还能对比同型号设备的历史数据(跨个体记忆关联),快速判断是传感器故障、液压油污染还是泵体磨损(精准诊断),据三一重工披露,该方案使设备故障停机时间减少了42%,维修成本降低了28%。
这一案例的关键在于“全息编码”——如果传感器覆盖不足(如仅采集压力而忽略振动),或数据传输延迟(如从分钟级降到秒级),数字孪生体的“记忆”就会残缺,导致提取时出现误判,2026年,随着工业级传感器成本下降(单个压力传感器价格从2020年的500元降至2026年的80元),全息化数据采集已成为可能,但如何平衡数据量与计算效率,仍是企业需要解决的难题。 绿色小镇与绿色交通热度持续上升,相关产业迎来新机遇

知识点二:记忆的“情境依赖性”,要求数字孪生体必须“场景化”
记忆科学发现,人对信息的记忆和提取高度依赖情境——在相同或相似的情境下,记忆更容易被唤醒,数字孪生体的应用同样需要“情境化”:它不能仅是一个静态的虚拟模型,而必须与具体的生产场景(如设备运维、工艺优化、供应链协同)深度绑定,通过场景化的数据流动和模型迭代,让“数字记忆”真正服务于生产决策。
2026年,宁德时代的电池生产线提供了一个典型场景,其数字孪生平台不仅构建了每条生产线的虚拟模型,还针对“电芯注液”这一关键工序开发了场景化模块,注液过程中,电解液的流量、温度、压力等参数直接影响电芯性能,但传统控制方式依赖人工经验,难以精准匹配不同批次原料的特性,宁德时代的方案是:在数字孪生体中模拟注液过程的流体动力学模型,结合实时采集的原料参数(如粘度、密度)和生产环境数据(如车间温度、湿度),生成“最优注液参数包”,并实时下发至生产设备,当原料批次变化时,系统能自动调整参数(如流量增加5%、温度降低2℃),确保电芯一致性,据宁德时代披露,该方案使电芯良品率从98.2%提升至99.1%,单条生产线年节约成本超200万元。
这一案例的关键在于“场景化”——数字孪生体不是“万能模型”,而是针对具体工序(如注液)开发的专用模块,2026年,随着工业互联网平台的发展(如华为FusionPlant、阿里云ET工业大脑),企业可以更便捷地开发场景化数字孪生应用,但如何从海量数据中提取与场景强相关的特征(如注液过程中的流体变化),仍需要结合领域知识(如电池化学)进行深度建模。

知识点三:记忆的“遗忘曲线”,揭示了数字孪生体必须“动态更新”
记忆科学中的“遗忘曲线”表明,信息在记忆中的保留量会随时间推移逐渐下降,除非通过复习或应用进行强化,数字孪生体的模型同样需要“动态更新”——物理实体的状态(如设备磨损、工艺改进)会随时间变化,如果数字模型不同步更新,就会与实体产生“记忆偏差”,导致预测或优化结果失真。
2026年,中航工业的飞机发动机维修案例提供了典型实践,其数字孪生平台为每台发动机构建了包含结构、热力学、疲劳寿命等多维模型的虚拟体,但最初的应用效果并不理想——维修人员反馈,数字模型预测的剩余寿命与实际检测结果偏差较大,问题出在模型更新机制上:发动机在使用过程中,叶片会因高温高压产生微小变形,涡轮盘会因疲劳产生裂纹,但这些变化初期难以通过传感器直接检测,导致数字模型“记忆”滞后,中航工业的解决方案是:开发“自更新算法”——结合发动机的飞行数据(如转速、温度、振动)、维修记录(如更换的部件、修复的裂纹)和历史模型数据,通过机器学习训练出“模型更新模型”,当新数据输入时,系统能自动判断是否需要调整模型参数(如叶片刚度降低3%、涡轮盘疲劳寿命缩短10%),据中航工业披露,该方案使发动机剩余寿命预测误差从±15%降至±5%,维修计划制定效率提升60%。 2026年碳封存与绿色港口热度持续上升,相关领域迎来新发展
这一案例的关键在于“动态更新”——数字孪生体不能“一建了之”,而必须建立数据驱动的模型更新机制,2026年,随着边缘计算技术的发展(如英特尔的OpenVINO工具包支持在设备端运行轻量级AI模型),企业可以更高效地实现模型动态更新,但如何平衡更新频率与计算成本(如频繁更新可能导致模型过拟合),仍需要结合具体场景进行优化。

知识点四:记忆的“工作记忆容量”,限制了数字孪生体的“实时处理能力”
记忆科学中的“工作记忆”指大脑在短时间内处理和保持信息的能力,其容量有限(通常为7±2个信息单元),数字孪生体的实时处理同样受限于计算资源——当需要同时处理大量传感器数据(如每秒上千条)、运行复杂模型(如流体动力学仿真)时,如果计算资源不足,就会导致处理延迟,影响决策的及时性。 本月清洁能源与能量回收及研学旅行热度持续上升,相关产业迎来新机遇
2026年,宝钢股份的冷轧生产线提供了一个典型案例,其数字孪生平台需要实时监控轧机的厚度、张力、速度等参数,并通过模型计算调整轧制力,确保钢板厚度偏差在±0.01mm以内,最初,平台采用集中式计算架构(所有数据传输至云端处理),但当生产线速度提升至1200米/分钟时,数据传输延迟达到200毫秒,导致调整指令滞后,钢板厚度波动增大,宝钢的解决方案是:采用“边缘+云端”混合计算架构——在轧机旁部署边缘计算节点(如华为Atlas 800推理服务器),实时处理关键数据(如厚度、张力),运行轻量级控制模型(调整周期缩短至50毫秒);非关键数据(如设备温度、能耗)上传至云端,运行复杂分析模型(如预测性维护),据宝钢披露,该方案使钢板厚度合格率从99.2%提升至99.7%,单条生产线年增产超5000吨。 2026年绿色生活圈与绿色机场热度持续攀升,相关应用不断深化
这一案例的关键在于“计算资源分配”——数字孪生体不能“所有数据都上云”,而必须根据数据的重要性和处理需求,合理分配边缘和云端的计算资源,2026年,随着5G+TSN(时间敏感网络)技术的发展(如西门子的Industrial Edge支持低至1毫秒的时延),企业可以更灵活地构建混合计算架构,但如何定义“关键数据”(如宝钢将厚度、张力定义为关键,温度定义为非关键),仍需要结合生产目标进行权衡。
知识点五:记忆的“联想记忆”,赋予了数字孪生体“跨场景迁移能力”
记忆科学中的“联想记忆”指大脑通过关联不同信息形成记忆网络,从而在遇到新情境时快速调用相关记忆进行推理,数字孪生体的高级应用同样需要“跨场景迁移”——通过构建通用的模型框架或数据接口,将一个场景(如设备运维)中积累的知识迁移到另一个场景(如工艺优化),避免重复建模,提升应用效率。
2026年,海尔智家的冰箱生产线提供了一个典型案例,其数字孪生平台最初用于设备运维(如预测