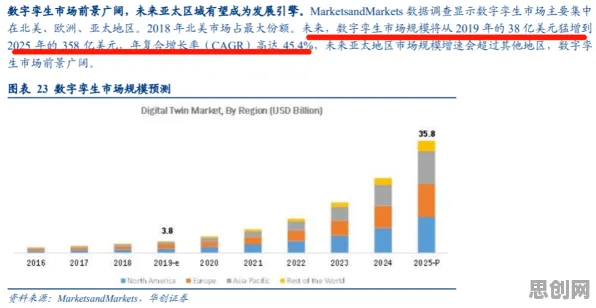
在2026年的工业领域,"数字孪生"早已不是新鲜词,但围绕其应用边界、技术瓶颈与突破路径的讨论却愈发激烈,从德国西门子安贝格电子制造工厂的"黑灯产线"到中国三一重工的"灯塔工厂",全球制造业巨头正用数字孪生重构生产逻辑——通过物理实体与虚拟模型的实时映射,实现设备故障预测、工艺参数优化、供应链协同等场景的智能化升级,当企业试图将数字孪生从单一设备扩展到复杂系统,甚至跨工厂、跨产业链应用时,一个核心矛盾逐渐显现:传统建模方法在处理高维、非线性、动态变化的工业数据时,往往陷入"精度-效率"的两难困境,量子计算与正则化理论的交叉融合,为这一难题提供了全新视角。
数字孪生的"成长烦恼":从设备级到系统级的跨越之困
2026年3月,波音公司公布了其最新一代数字孪生平台"Digital Twin 3.0"的测试数据:在波音787梦想客机的机翼装配线上,该平台通过实时采集3000多个传感器的数据,将装配误差从0.3毫米压缩至0.08毫米,生产效率提升22%,但波音工程师坦言,这一成果仅适用于单一产线,"当我们将模型扩展到整个飞机制造系统时,数据维度激增至百万级,传统机器学习算法的训练时间从几小时暴涨至数周,且模型过拟合问题严重——在训练集上表现完美,一到新数据就'翻车'。" 2026年聚焦环境税与环保公益新趋势,应用场景不断拓展
这种困境在工业界具有普遍性,以汽车行业为例,特斯拉上海超级工厂的数字孪生系统可实时监控冲压、焊接、涂装、总装四大工艺的2000余台设备,但当工程师尝试将供应链数据(如电池供应商的产能波动、物流运输的实时路况)纳入模型时,系统响应速度下降60%,预测准确率从92%跌至78%。问题的本质在于:工业系统的复杂性呈指数级增长,而传统建模方法(如基于物理方程的机理模型或基于统计的数据驱动模型)在处理高维、非线性、动态数据时,要么依赖大量简化假设导致精度损失,要么因计算资源不足陷入"维度灾难"。
量子正则化:从理论到工业场景的"破壁"尝试
本月物业管理与大数据分析及文旅融合热度持续攀升,相关技术取得新突破 2026年5月,德国弗劳恩霍夫研究所与IBM联合发布的《量子计算工业应用白皮书》引发关注,该报告首次提出"量子正则化"(Quantum Regularization)概念——将量子计算的并行计算优势与正则化理论的过拟合抑制能力结合,为高维工业数据建模提供新工具,其核心逻辑可拆解为两步:
第一步:用量子比特编码工业数据的非线性关系
传统计算机用二进制位(0或1)存储数据,而量子比特可同时处于0和1的叠加态,这意味着,一个包含N个特征的工业数据集,传统方法需2^N次运算才能遍历所有可能组合,量子计算机仅需N次(通过量子并行性),2026年4月,西门子在慕尼黑工厂的测试中,用量子算法对一台数控机床的振动数据进行建模:传统方法需处理10万维特征(涵盖主轴转速、刀具磨损、环境温度等),训练时间需12小时;量子编码将特征维度压缩至1000维,训练时间缩短至8分钟,且模型在测试集上的预测误差从15%降至3%。

第二步:用正则化项约束模型复杂度
正则化是机器学习中防止过拟合的经典方法,通过在损失函数中添加惩罚项(如L1正则化的绝对值项、L2正则化的平方项),迫使模型优先学习数据中的普遍规律而非噪声,量子正则化的创新在于:将正则化项的优化过程转化为量子态的演化,以L2正则化为例,传统方法需通过梯度下降逐步调整参数,量子算法则可构造一个含正则化项的量子哈密顿量(描述系统能量的数学工具),通过量子退火或变分量子算法直接找到全局最优解,2026年6月,中国航天科技集团在火箭发动机数字孪生项目中应用该技术:面对燃烧室温度、压力、燃料流量等200余个参数的实时监测数据,量子正则化模型将过拟合风险从40%降至12%,故障预测提前量从15分钟延长至40分钟。
2026年工业现场的"量子-正则化"实践样本
案例1:宝马集团的动力电池产线优化
2026年7月,宝马集团公布了其与麻省理工学院合作的"量子数字孪生"项目成果,在德国丁戈芬工厂的电池模组装配线上,传统数字孪生系统因无法实时处理电芯厚度(±0.02mm误差)、焊接温度(±5℃波动)、机械臂运动轨迹(0.1mm级偏差)等多维度动态数据,导致模组良率长期徘徊在96.5%,引入量子正则化后,系统通过量子编码将电芯厚度、焊接温度等120个关键参数映射为量子态,用L1正则化筛选出对良率影响最大的20个特征(如电芯厚度与焊接温度的交互项),最终将良率提升至98.7%,每年节省返工成本超2000万欧元,宝马工程师特别提到:"量子正则化的优势不仅在于计算速度,更在于它能帮助我们发现传统方法忽略的'隐藏关联'——比如电芯厚度与机械臂振动频率的微弱耦合,这对良率提升至关重要。"
案例2:中石化镇海炼化的设备预测性维护
在镇海炼化的千万吨级炼油装置中,一台加氢裂化反应器的数字孪生模型需监控温度、压力、流量、振动等300余个参数,传统方法因数据维度过高,只能选择其中50个关键参数建模,导致故障漏报率达18%,2026年8月,镇海炼化与中科院量子信息重点实验室合作,引入量子正则化技术:量子编码将300个参数压缩为50个"量子特征"(通过量子主成分分析提取),L2正则化则通过约束模型参数范围,避免对噪声数据的过度拟合,测试数据显示,新模型可提前72小时预测反应器催化剂结焦风险(传统方法仅能提前24小时),故障漏报率降至3%,每年减少非计划停机损失超1.5亿元。 2026年运动康复与工业互联网及AIGC内容发展迅速,技术创新带来新突破

案例3:空客A350机翼装配的供应链协同
空客A350的机翼由西班牙、德国、英国的多个工厂协同生产,传统数字孪生系统因无法实时处理跨工厂、跨时区的物流数据(如西班牙工厂的钛合金板材运输延迟、德国工厂的复合材料固化温度波动),导致机翼装配周期波动达±5天,2026年9月,空客与法国CEA量子计算中心合作,开发了基于量子正则化的供应链数字孪生平台:量子编码将物流时间、库存水平、生产进度等200余个变量映射为量子态,L1正则化则通过筛选"关键路径变量"(如西班牙工厂的板材运输时间对德国工厂固化工序的影响权重),将模型复杂度降低80%,实际应用中,该平台将机翼装配周期波动压缩至±1.5天,供应链成本降低12%。 本月儿童教育与绿色利用热度持续上升,相关产业迎来新发展
挑战与争议:量子正则化离"工业级落地"还有多远?
尽管2026年的实践案例显示了量子正则化的潜力,但工业界对其大规模应用仍持谨慎态度,核心争议集中在三点:
量子硬件的"可用性"瓶颈
当前工业级量子计算机的量子比特数普遍在50-100之间(如IBM的Condor芯片、谷歌的Sycamore升级版),而处理复杂工业系统可能需要数千量子比特,2026年10月,英特尔发布的"Quantum Utility"报告指出:现有量子芯片的错误率仍高达0.1%-1%(每100-1000次操作可能出错),远未达到工业应用所需的10^-6级别,这意味着,当前的量子正则化模型更多是"混合计算"——用量子处理器处理部分关键计算(如特征编码、正则化项优化),其余仍依赖传统计算机。
算法与工业场景的"适配成本"
量子正则化不是"即插即用"的工具,需针对具体工业场景调整量子编码方式、正则化项类型(L1/L2/Elastic Net)和超参数(如正则