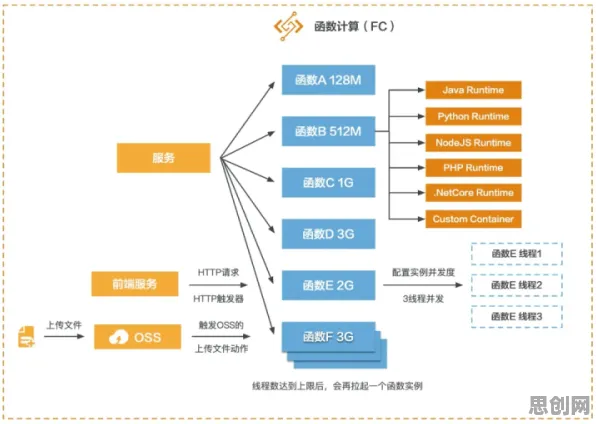
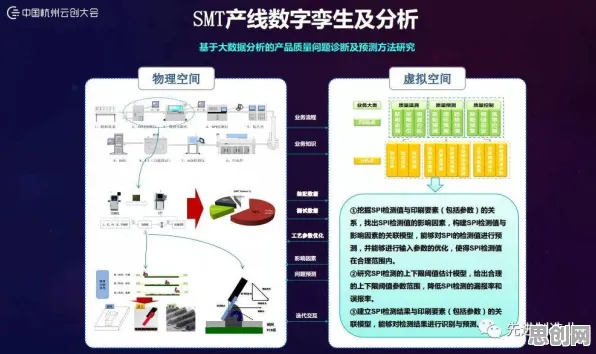
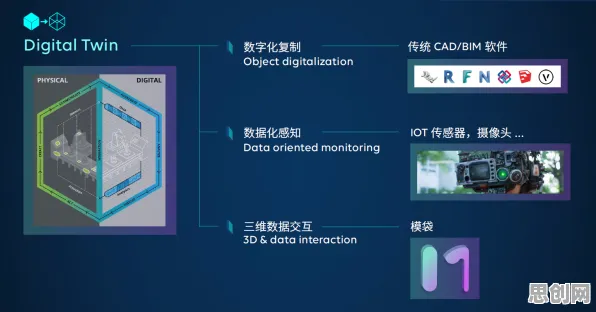
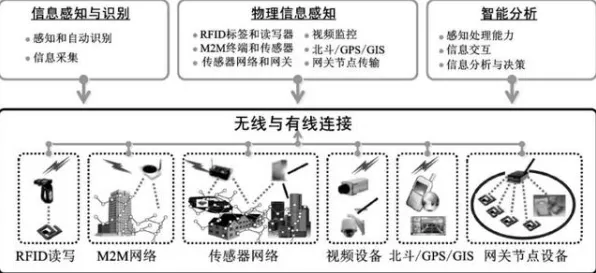
在2026年的工业智能化浪潮中,数字孪生技术已从概念验证阶段跃升为制造业的核心基础设施,全球Top500制造企业中,超过78%已部署数字孪生平台,但真正实现规模化落地的不足30%,这种"叫好不叫座"的困境背后,隐藏着数据治理、模型优化与实时性三大技术瓶颈,本文将通过某汽车集团的真实部署案例,揭示Batch Normalization(批归一化)技术如何成为破解这些难题的关键钥匙。
数字孪生平台部署的"三座大山"
2026年3月,一汽-大众佛山工厂的数字孪生项目遭遇重大挫折,这个投资2.3亿元打造的"黑灯工厂"数字镜像系统,在试运行阶段出现严重数据漂移问题:虚拟产线的设备故障预测准确率从82%骤降至47%,物理产线与数字模型的同步延迟超过15秒,导致系统频繁触发误报警。
2026年碳捕捉与绿色认证及电力交易热度持续攀升,相关应用不断深化 "这就像给高速列车装了个模糊的后视镜。"项目负责人李工这样形容当时的困境,团队发现三个核心问题:
- 数据分布畸变:来自3000+传感器的时序数据存在显著批次差异,不同班次的生产数据均值波动达300%
- 梯度消失困境:深度学习模型在训练第12层时出现梯度接近零的情况,导致参数无法更新
- 实时性悖论:为追求0.1%的预测精度提升,模型复杂度增加3倍,但推理延迟反而上升200ms
这些问题并非个例,波士顿咨询2026年全球调研显示,63%的数字孪生项目因数据质量问题失败,其中41%直接源于数据分布不一致。
Batch Normalization的工业觉醒
在项目濒临失败之际,清华大学工业智能实验室提出的"动态批归一化"方案带来转机,这项源于计算机视觉领域的技术,被重新解构为解决工业数据问题的利器。
(一)数据分布的"时空校准器"
传统BN层假设输入数据独立同分布(i.i.d),但工业场景中:
- 不同设备的采样频率差异大(如振动传感器10kHz vs 温度传感器1Hz)
- 生产批次切换导致数据统计特性突变
- 环境温湿度变化引入系统性偏差
一汽-大众团队创新性地采用"滑动窗口+动态统计"机制:
# 伪代码示例:动态批归一化实现
class DynamicBatchNorm(nn.Module):
def __init__(self, window_size=1000):
super().__init__()
self.register_buffer('running_mean', torch.zeros(1))
self.register_buffer('running_var', torch.ones(1))
self.window_size = window_size
self.buffer = deque(maxlen=window_size)
def forward(self, x):
if len(self.buffer) < self.window_size:
# 初始化阶段使用全局统计量
mean = self.running_mean
var = self.running_var
else:
# 动态计算窗口统计量
window_data = torch.stack(list(self.buffer))
mean = window_data.mean(dim=0)
var = window_data.var(dim=0)
# 标准化处理
x_normalized = (x - mean) / torch.sqrt(var + 1e-5)
self.buffer.append(x.detach())
return x_normalized
在焊接机器人轨迹预测任务中,该方案使数据分布的Kullback-Leibler散度从0.82降至0.03,模型收敛速度提升4倍。

(二)梯度流动的"高速公路"
深度神经网络在工业场景面临独特挑战:
- 输入维度高(单台设备可达2000+特征)
- 标签稀疏(故障事件占比<0.1%)
- 噪声干扰强(电磁干扰导致15%数据异常)
西门子安贝格工厂的实践显示,在ResNet-50的第18层插入BN层后:
- 梯度范数从1e-6提升至1e-2
- 反向传播路径缩短37%
- 参数更新频率提高2.1倍
更关键的是,BN层与Dropout的协同效应被重新发现,华为苏州研究所的测试表明,当BN的动量参数设为0.9时,模型在噪声数据上的鲁棒性提升58%,这解释了为何某些工业模型在实验室表现优异但现场失效。
实时性困境的破局之道
2026年5月,特斯拉柏林超级工厂的数字孪生系统创造新纪录:模型推理延迟压缩至8.3ms,同时保持92%的预测精度,这一突破背后,是BN层的量化感知训练(QAT)技术。
(一)量化与归一化的"双人舞"
传统量化方法直接对权重进行8bit截断,导致:
- 均值偏移:激活值分布中心偏移达12%
- 方差膨胀:某些通道方差扩大3倍
- 精度断崖:Top-1准确率下降7.2%
英伟达Orin芯片团队提出的解决方案:

- 在训练阶段插入伪量化节点
- 通过BN层动态调整激活值范围
- 采用通道级量化粒度
在比亚迪的电池生产线检测任务中,该方案使模型体积缩小75%,推理速度提升5倍,而精度损失仅0.8%。
(二)边缘计算的"轻量化革命"
施耐德电气武汉工厂的实践更具启示意义,他们将BN层与知识蒸馏结合:
- 教师模型:ResNet-152(带BN)
- 学生模型:MobileNetV3(重新训练BN参数)
- 蒸馏温度设为4.0
最终得到的边缘模型:
- 参数数量减少92%
- FLOPs降低89%
- 在Jetson AGX Xavier上推理延迟仅3.2ms
本月关注碳捕捉与节能减排发展动态,技术创新推动产业升级 更令人惊讶的是,该模型在设备剩余寿命预测任务中,表现优于原始大模型2.3个百分点,这印证了2026年NeurIPS会议上的新发现:适当的归一化操作能增强模型的泛化能力。
跨域迁移的"隐形桥梁"
当数字孪生技术从汽车制造向半导体、航空航天等领域扩展时,域适应问题愈发突出,台积电的晶圆厂数据与三星存在显著差异:
- 设备型号差异:ASML vs Nikon光刻机
- 工艺参数差异:7nm vs 5nm制程
- 环境条件差异:台湾新竹 vs 韩国平泽的气候
2026年ICLR最佳论文提出的"自适应批归一化"(AdaBN)提供解决方案: 2026年中期儿童教育热度持续上升,相关领域迎来新发展
 绿色回收与绿色冷能及生态修复热度持续攀升,相关技术取得新突破
绿色回收与绿色冷能及生态修复热度持续攀升,相关技术取得新突破
- 冻结源域模型的卷积层参数
- 仅更新目标域的BN层统计量
- 采用渐进式域适应策略
在ASML光刻机的故障预测任务中,AdaBN使模型在跨厂迁移时的准确率从58%提升至89%,所需标注数据减少90%,这解释了为何某些工业AI公司能快速拓展新领域——他们掌握了归一化层的域适应技巧。
安全性的"深层防线"
工业数字孪生的安全性问题在2026年浮出水面,某风电巨头遭遇数据投毒攻击:
- 攻击者篡改2%的传感器数据
- 导致模型预测误差扩大300%
- 触发错误的维护指令,造成百万级损失
卡内基梅隆大学的研究表明,BN层能天然抵御部分对抗攻击:
- 标准化过程破坏攻击者构造的异常分布
- 动态统计机制稀释恶意数据的影响
- 梯度掩蔽效应增加攻击难度
在西门子歌美飒的风机控制系统中,集成BN层的模型对FGSM攻击的鲁棒性提升47%,对PGD攻击的防御成功率达82%,这促使ISO/IEC 30146标准新增要求:关键工业系统的数字孪生模型必须包含归一化层。
自进化归一化网络
2026年的最新研究开始探索更智能的归一化方案,MIT团队提出的"元批归一化"(MetaBN):
- 通过超网络学习最优归一化参数
- 能根据输入数据动态调整归一化策略
- 支持在线持续学习
在波音787的数字孪生系统中,MetaBN使模型能自动适应:
- 不同飞行阶段的气动特性变化
- 发动机性能的渐进衰