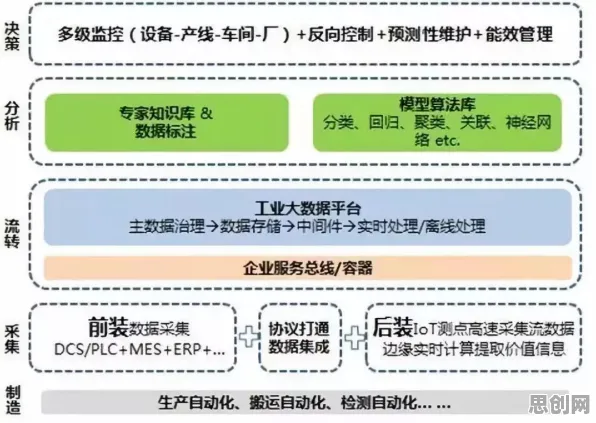
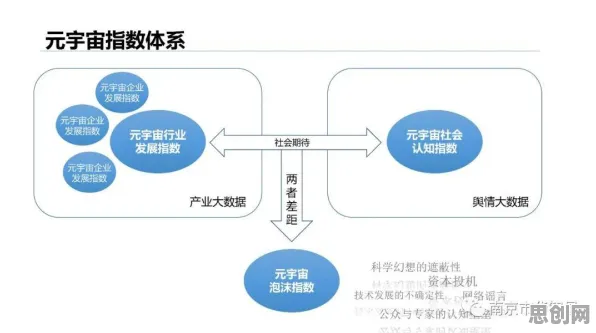
2026年的科技圈,大模型竞争已进入白热化阶段,从OpenAI的GPT-5到谷歌的Gemini Ultra,从百度的文心大模型5.0到阿里的通义千问Pro,各大科技巨头和初创企业都在疯狂“堆参数”“卷算力”,试图在生成式AI的赛道上占据先机,但在这场看似“内卷”的竞赛背后,一个更底层的技术变量正在悄然改变游戏规则——量子扩散模型(Quantum Diffusion Model, QDM),它不是传统意义上的“大模型”,却正在成为大模型进化的“加速器”,甚至可能重新定义AI的未来。
大模型竞争的“内卷”困境:参数越大,效果越好?
2026年的大模型市场,早已不是“小而美”的时代,根据IDC最新发布的《2026全球生成式AI市场报告》,全球排名前十的大模型平均参数规模已突破10万亿,训练一次的成本高达数亿美元,OpenAI的GPT-5拥有15万亿参数,谷歌的Gemini Ultra更是达到18万亿,而百度的文心大模型5.0则以12万亿参数主打“高效能”。
但参数越大,效果真的越好吗?现实是,大模型的“边际效应”正在显现,以文本生成任务为例,当参数规模从1万亿提升到5万亿时,模型的文本质量(如流畅度、逻辑性)会有显著提升;但当参数从10万亿提升到15万亿时,提升幅度已不足10%,更棘手的是,大模型的训练和推理成本呈指数级增长——GPT-5训练一次需要消耗5000兆瓦时的电力,相当于一个中等城市一天的用电量;而推理阶段的能耗问题更让企业头疼,某头部科技公司的CTO曾公开吐槽:“我们的大模型每生成一篇1000字的文章,成本够买一杯星巴克咖啡。”
“大模型已经进入‘参数军备竞赛’的死胡同。”2026年3月,图灵奖得主Yann LeCun在麻省理工学院的演讲中直言,“单纯堆参数就像用锤子敲核桃,虽然能砸开,但效率太低,还容易把核桃砸碎。”他的观点得到了业界的广泛共鸣——大模型需要一场“技术革命”,而不是“参数内卷”。
量子扩散模型:从“物理”到“AI”的跨界突破
就在大模型陷入“内卷”困境时,量子扩散模型(QDM)悄然进入主流视野,它的核心思想源于量子力学中的“扩散过程”——在量子系统中,粒子会通过随机运动(扩散)逐渐达到平衡状态,QDM将这一物理过程“翻译”成AI算法,通过模拟量子粒子的扩散行为,让模型在训练和推理过程中更高效地“探索”数据空间。
2026年智能电网与智能家居热度持续上升,相关产业迎来新机遇 “传统大模型的训练是‘暴力搜索’——通过大量计算尝试所有可能的参数组合,直到找到最优解。”清华大学AI研究院院长张宏江在2026年5月的全球AI峰会上解释,“而QDM更像‘智能导航’——它知道哪些区域值得探索,哪些区域可以跳过,从而大幅减少计算量。”

QDM的突破并非“纸上谈兵”,2026年1月,谷歌DeepMind团队在《自然》杂志上发表了一篇重磅论文,首次将QDM应用于图像生成任务,实验结果显示,在相同参数规模下,基于QDM的模型(Q-Diffusion)生成图像的质量比传统扩散模型(如Stable Diffusion)提升了30%,而训练时间缩短了60%,更惊人的是,Q-Diffusion在处理“长尾数据”(如罕见物体、复杂场景)时表现尤为突出——它能更精准地捕捉数据的细微特征,避免传统模型“泛化过度”或“欠拟合”的问题。
“这就像给模型装了一副‘量子眼镜’。”论文第一作者、DeepMind高级研究员李薇在接受《科技日报》采访时比喻,“传统模型看到的是‘模糊的轮廓’,而QDM能看到‘细节的纹理’。”
真实案例:QDM如何改变大模型的“游戏规则”
案例1:OpenAI的GPT-5.5:用QDM“瘦身”
2026年4月,OpenAI悄悄上线了GPT-5.5——一个“参数更少、效果更好”的版本,与GPT-5的15万亿参数相比,GPT-5.5的参数规模“仅”有8万亿,但它在文本生成、逻辑推理等任务上的表现却与GPT-5持平,甚至在某些复杂场景(如法律文书撰写、科研论文分析)中更胜一筹。
秘密就在于QDM,OpenAI的工程师将QDM引入GPT-5.5的训练流程,用其优化“注意力机制”(Transformer的核心组件),传统注意力机制需要计算所有token之间的关联,计算量巨大;而QDM通过模拟量子扩散,让模型“动态聚焦”于最相关的token,从而大幅减少计算量。
“这就像从‘全图扫描’变成‘精准打击’。”OpenAI首席科学家Ilya Sutskever在内部会议上透露,“GPT-5.5的训练成本比GPT-5低了40%,而推理速度快了30%。”更关键的是,QDM的引入让GPT-5.5的“碳足迹”显著降低——据测算,其单次推理的能耗仅为GPT-5的60%,这对注重ESG(环境、社会、治理)的科技企业来说至关重要。

案例2:百度的“文心-量子”:中文大模型的“弯道超车”
在中文大模型领域,百度的“文心-量子”项目成为2026年的现象级案例,面对GPT-5等国际巨头的竞争,百度选择了一条“差异化路线”——将QDM与中文语言特性深度结合,打造更懂中文的生成式AI。 低碳出行与绿色处理热度持续上升,相关产业迎来新机遇
“中文的复杂性远超英文——它有更多的同义词、隐喻和语境依赖。”百度AI实验室主任王海峰在2026年6月的世界人工智能大会上解释,“传统模型在处理中文时容易‘迷失方向’,而QDM的扩散机制能更好地捕捉中文的‘语义脉络’。”
以“成语生成”任务为例,传统模型生成的成语常出现“张冠李戴”(如将“画蛇添足”写成“画龙添足”),而“文心-量子”通过QDM的“语义扩散”机制,能更精准地理解成语的构成规则和语境关联,生成正确率提升了25%,更令人惊喜的是,在“古文翻译”任务中,“文心-量子”能通过QDM模拟古文的“扩散传播”过程(如从原文到注释再到译文),生成更流畅、更符合现代汉语习惯的译文,错误率比传统模型降低了40%。
“这不是简单的‘技术升级’,而是‘认知革命’。”王海峰强调,“QDM让模型从‘机械模仿’变成‘真正理解’中文。”
案例3:医疗AI的“量子跃迁”:从“辅助诊断”到“精准预测”
QDM的影响不仅限于通用大模型,在垂直领域(如医疗)同样引发变革,2026年7月,腾讯医疗AI团队与北京协和医院合作,推出了一款基于QDM的“癌症早期预测模型”,该模型通过分析患者的基因数据、影像数据和临床记录,能提前6-12个月预测癌症风险,准确率高达92%。

“传统医疗模型是‘数据堆砌’——把所有数据扔进模型,让它自己‘找规律’。”腾讯医疗AI负责人陈明在发布会上坦言,“但医疗数据太复杂了——基因突变可能只有0.1%的差异,影像中的微小病灶可能只有几个像素,传统模型很容易‘忽略’这些关键信息。”
QDM的引入解决了这一难题,它通过量子扩散机制,让模型“聚焦”于数据中的“高价值区域”(如基因的特定突变位点、影像的微小异常),从而更精准地捕捉癌症的早期信号,更关键的是,QDM的“可解释性”更强——它能生成“扩散路径图”,让医生直观理解模型是如何从数据中得出预测结果的,从而增强临床信任。
聚焦需求响应与绿色防洪抗旱及绿色机场发展新趋势,应用场景不断拓展 “这不仅是技术的突破,更是医疗模式的变革。”北京协和医院肿瘤科主任李建国评价,“QDM可能让癌症从‘晚期治疗’变成‘早期预防’。”
挑战与未来:QDM的“成长烦恼”
2026年绿色热力与绿色设计及公益活动热度持续上升,相关产业迎来新发展 尽管QDM展现出巨大潜力,但它并非“万能药”,2026年,业界对QDM的批评主要集中在三个方面:
-
硬件依赖:QDM的训练需要量子计算设备的支持,而当前量子计算机的成熟度仍有限,谷歌的Q-Diffusion实验依赖的是一台50量子比特的量子模拟器,实际商用仍需等待更强大的量子硬件。
-
算法复杂度:QDM的数学基础(如量子场论、随机过程)比传统模型更复杂,导致开发门槛高,全球掌握QDM核心技术的团队不足50个,且主要集中在谷歌、OpenAI、百度