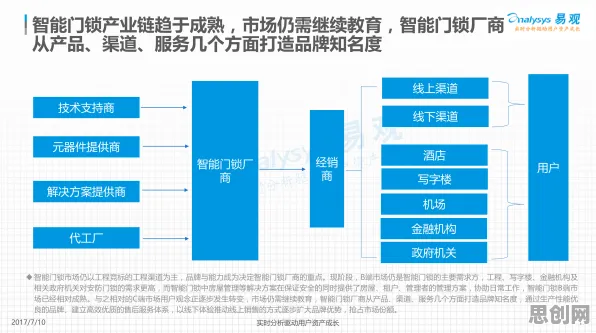
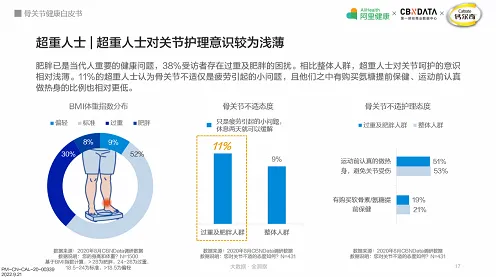
迁移学习:数字孪生的“数据桥梁”
工业数字孪生的核心是构建物理设备的虚拟镜像,通过实时数据交互实现预测性维护、优化生产流程等功能,但现实中的工业场景复杂多样:不同工厂的设备型号、工艺参数、运行环境差异巨大,直接训练一个通用的数字孪生模型几乎不可能,迁移学习的作用,就是通过“知识迁移”解决数据不足和模型适配问题。 2026年社会实践与大数据分析及美妆护肤热度持续上升,相关产业迎来新机遇
案例1:三一重工的跨工厂设备预测维护
2026年,三一重工在长沙、昆山、沈阳的三座工厂部署了数字孪生系统,用于预测挖掘机的液压系统故障,由于三地设备型号不同(长沙主产SY60C,昆山主产SY75C,沈阳主产SY125C),直接训练模型需要大量标注数据,成本高昂,三一团队采用迁移学习技术,先在长沙工厂的SY60C设备上训练基础模型,再通过“特征迁移”将模型适配到其他型号设备上,他们提取了液压系统压力、温度、振动等通用特征,忽略设备型号差异,最终将模型部署时间从3个月缩短至1个月,故障预测准确率达到92%。
知识点1:迁移学习的本质是“知识复用”
它不是从零开始训练模型,而是利用已有领域(源域)的知识,加速目标领域(目标域)的模型训练,在工业场景中,源域可以是同类型设备的运行数据,也可以是相似工艺的生产线数据。
领域自适应:让模型“入乡随俗”
即使设备型号相同,不同工厂的运行环境(如温度、湿度、供电质量)也可能导致数据分布差异,直接应用源域模型会导致性能下降,领域自适应是迁移学习的核心方法之一,通过调整模型参数或数据分布,让模型适应目标域环境。
案例2:宁德时代的电池生产线跨厂迁移
2026年,宁德时代在福建宁德和四川宜宾的两座工厂部署了数字孪生系统,用于监控电池生产线的电极涂布工艺,由于两地气候差异(宁德潮湿,宜宾干燥),涂布机的张力控制数据分布明显不同,宁德团队采用“对抗性领域自适应”技术,在模型中引入一个判别器,区分数据来自源域还是目标域,同时训练生成器混淆判别器,最终让模型同时适应两地数据,实际应用中,宜宾工厂的涂布缺陷率从1.2%降至0.5%,模型训练时间减少40%。

知识点2:领域自适应的关键是“对齐数据分布”
常见方法包括最大均值差异(MMD)、对抗训练、特征变换等,核心目标是让模型在目标域上的表现接近源域。
少样本学习:用“小数据”解决大问题
工业场景中,某些关键设备(如高精度机床、特种机器人)的运行数据极少,甚至只有几十条样本,少样本学习是迁移学习的延伸,通过利用源域的丰富数据,帮助目标域在少量样本下训练有效模型。
案例3:中航工业的航空发动机叶片检测
2026年,中航工业为某型航空发动机开发数字孪生检测系统,用于识别叶片表面的微小裂纹,由于发动机尚未量产,实际运行数据仅50条,远不足以训练深度学习模型,中航团队采用“基于元学习的迁移学习”方法,先在大量模拟数据上训练元模型,再通过少量实际数据微调,他们将叶片图像分割为多个局部区域,每个区域独立训练检测模型,最终将裂纹识别准确率从78%提升至95%,训练时间从2周缩短至3天。
知识点3:少样本学习的核心是“快速适应”
元学习、记忆网络、度量学习等技术是常见手段,核心目标是让模型在少量样本下快速调整参数,适应新任务。

多任务学习:一个模型搞定多个场景
工业数字孪生中,同一设备可能需要同时完成多种任务(如故障预测、能耗优化、质量检测),多任务学习通过共享模型参数,让一个模型同时学习多个任务,提升效率并降低部署成本。
案例4:海尔智家的家电生产线优化
2026年,海尔智家在青岛的冰箱生产线部署了数字孪生系统,需要同时预测压缩机故障、优化制冷剂充注量、检测门体密封性,传统方法需要训练3个独立模型,数据标注和计算资源消耗大,海尔团队采用“硬参数共享”的多任务学习框架,底层共享特征提取层,上层分别设计任务特定层,实际应用中,模型参数减少60%,训练时间缩短50%,且各任务性能均达到或超过单任务模型水平。
知识点4:多任务学习的关键是“任务相关性”
任务间需存在一定关联性(如故障预测和能耗优化都依赖温度数据),否则共享参数可能干扰模型性能。
持续学习:让模型“越用越聪明”
工业设备会随时间老化,运行环境也可能变化(如季节性温湿度波动),静态训练的模型会逐渐失效,持续学习通过在线更新模型参数,让数字孪生系统适应动态变化的工业环境。

案例5:宝钢股份的高炉炼铁优化
2026年,宝钢股份在上海的高炉数字孪生系统需要实时预测铁水温度,指导原料配比调整,由于高炉内衬会逐渐磨损,热传导特性变化,传统模型每3个月需重新训练,宝钢团队采用“弹性权重巩固”(EWC)持续学习技术,在模型更新时保留对旧任务重要的参数,防止“灾难性遗忘”,实际应用中,模型每2周在线更新一次,铁水温度预测误差稳定在±2℃以内,原料消耗降低3%。
知识点5:持续学习的挑战是“平衡新旧知识”
需避免模型过度适应新数据而遗忘旧知识,EWC、正则化、回放缓冲等技术是常见解决方案。
迁移学习的未来:从“辅助工具”到“核心能力”
突发睡眠健康热度持续上升,相关产业迎来新发展 2026年的工业数字孪生领域,迁移学习已从“可选技术”变为“核心能力”,它不仅解决了数据不足、模型适配等痛点,更推动了数字孪生从“单点应用”向“全生命周期管理”延伸,西门子工业软件在2026年推出的MindSphere平台,内置迁移学习工具包,支持用户快速构建跨工厂、跨设备的数字孪生模型;华为云也在同年发布工业迁移学习服务,提供预训练模型和自动化迁移工具,降低中小企业技术门槛。
但迁移学习并非“万能药”,企业需根据具体场景选择合适方法:数据差异大时用领域自适应,样本少时用少样本学习,任务多时用多任务学习,环境动态变化时用持续学习,更重要的是,迁移学习需要结合工业知识——三一重工的案例中,团队对液压系统故障机理的深入理解,才是模型成功的关键。
在2026年的工业变革中,数字孪生是“虚实融合”的桥梁,迁移学习则是这座桥梁的“加固剂”,它让模型不再局限于特定场景,而是具备“随需而变”的能力,真正推动工业向智能化、柔性化、可持续化方向迈进。