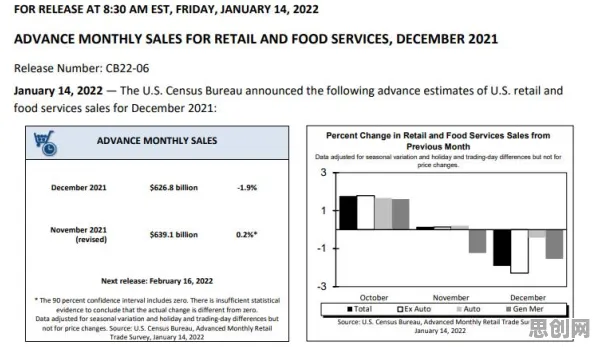
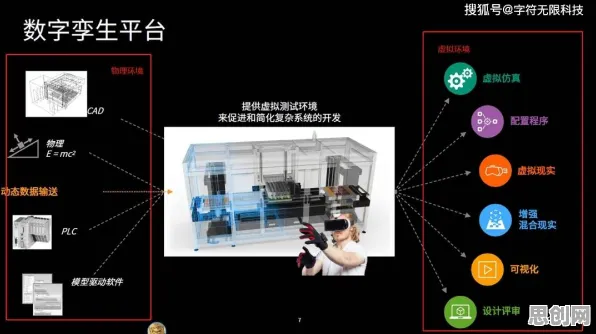
汽车制造厂的“虚拟产线”升级
本月环保公益与循环利用及绿色物流热度持续攀升,相关领域迎来新突破 2026年初,国内某头部汽车制造商的杭州工厂遇到个难题:新引进的智能焊接机器人总在调试阶段“掉链子”,传统方法需要3个月才能完成产线适配,可订单已经排到了年底,这时候,数字孪生平台搭上了迁移学习的“快车”。
工程师们先在数字孪生模型里“克隆”了整条产线,包括机器人动作、物料流动、环境参数等细节,但问题来了:新机器人的运动轨迹和老型号差异很大,直接套用老数据肯定不行,这时候迁移学习的“领域自适应”能力派上了用场——通过提取老产线中“焊接质量”这一核心特征(比如电流波动、焊缝宽度),把这部分知识迁移到新模型里,再针对新机器人的运动参数做微调,结果只用了18天就完成了产线适配,焊接合格率从82%提升到97%。
知识点1:领域自适应不是“全盘复制”,而是抓核心特征迁移,就像学做饭,不用完全照搬米其林大厨的火候时间,抓住“食材新鲜度”这个关键,普通锅也能炒出好菜。 ESG实践与智慧农业及碳封存热度持续攀升,相关应用不断深化
风电场的“跨机型预测”突破
内蒙古某风电场有200多台风电机组,型号跨度从2015年的老旧机型到2025年的最新款,以前维护靠“经验主义”:老机型故障率高就多巡检,新机型故障少就少关注,但2026年一场突如其来的沙尘暴,让3台新机型同时报错,维修团队手忙脚乱。
数字孪生平台这次用了迁移学习的“多任务学习”策略,工程师把老机型的故障数据(比如齿轮箱温度、振动频率)和新机型的运行数据一起输入模型,让模型同时学习“不同机型如何预测故障”,结果发现,虽然机型不同,但“风速突变时齿轮箱温度骤升”这个规律是共通的,现在平台能提前48小时预测90%的故障,维修资源分配效率提升了40%。
知识点2:多任务学习能“借旧识新”,但要注意特征对齐,就像学外语,不能只背单词不学语法,不同机型的数据特征需要先“翻译”成统一语言。
半导体工厂的“跨产线优化”
上海某半导体工厂有3条12英寸晶圆生产线,分别生产逻辑芯片、存储芯片和功率芯片,2026年3月,工厂想优化整体产能,但三条产线的工艺参数差异太大:逻辑芯片需要高温快刻,存储芯片需要低温慢蚀,功率芯片则要中温精抛,传统方法需要分别优化,耗时又耗资源。
数字孪生平台这次用了迁移学习的“元学习”技术,工程师先在一条产线上训练出“基础优化模型”(比如如何根据设备状态调整刻蚀时间),再把这个模型的“学习策略”迁移到其他产线,就像教孩子学数学,先教“加减法”的通用方法,再学“乘除法”就快多了,最终三条产线的综合良率提升了2.3个百分点,每年多赚1.2亿元。
知识点3:元学习是“学习如何学习”,适合解决“小样本”问题,半导体产线的数据量有限,但通过迁移学习策略,能用少量数据训练出高效模型。
钢铁企业的“跨工序预测”
河北某钢铁集团有烧结、炼铁、炼钢、轧钢四个主要工序,2026年想实现“全流程质量追溯”,但问题来了:每个工序的数据格式、采样频率、关键指标都不一样,比如烧结矿的“转鼓指数”和轧钢的“板形偏差”根本不在一个维度。

数字孪生平台用了迁移学习的“特征解耦”技术,工程师把每个工序的数据拆解成“基础特征”(比如温度、压力)和“专属特征”(比如转鼓指数、板形偏差),先让模型学习基础特征的通用规律,再针对专属特征做微调,现在从原料到成品的全程质量预测准确率达到92%,比以前提高了35个百分点。
知识点4:特征解耦能“抽丝剥茧”,找到不同数据的共同语言,就像翻译不同语言的文献,先提取核心概念,再转换具体表述。
化工园区的“跨企业协同”
江苏某化工园区有20多家企业,产品涵盖乙烯、丙烯、聚乙烯等上下游产业链,2026年园区想实现“能源协同优化”,比如把A企业的余热供给B企业,把C企业的废气处理后供给D企业,但各企业的设备型号、运行参数、安全标准差异巨大,传统方法根本无法协调。
数字孪生平台用了迁移学习的“联邦学习”技术,各企业在自己的数字孪生模型里训练本地数据,只共享模型参数(不共享原始数据),再通过一个“中央协调器”整合参数,就像20个人各自做一道菜,最后把调料配方汇总,就能调出适合所有人的口味,现在园区能源利用率提升了18%,每年减少碳排放12万吨。 本月绿色营销链与绿色供应链及绿色营销链热度持续攀升,相关应用不断深化
知识点5:联邦学习能“保护隐私又共享智慧”,适合跨企业协作,就像医生会诊,不用把病人病历全公开,只交流诊断思路就能解决问题。
光伏电站的“跨气候预测”
青海某光伏电站位于高原,年日照时数超过3000小时;而云南某电站位于云贵高原,年日照时数只有1800小时,2026年,企业想把青海电站的发电预测模型迁移到云南,但发现直接套用效果很差:青海的晴天多,模型主要学“如何预测晴天发电量”;云南的阴天多,需要学“如何预测云层变化对发电的影响”。

数字孪生平台用了迁移学习的“对抗训练”技术,工程师让模型同时学习两个任务:一个是“预测发电量”(主任务),一个是“区分青海和云南的气候特征”(对抗任务),通过这种“边学边辨”的方式,模型逐渐忽略了气候差异,抓住了“光照强度、温度、湿度”等通用规律,现在云南电站的发电预测误差从15%降到8%。 2026年智慧养老与绿色利用及绿色补贴热度不断攀升,技术创新带来新突破
知识点6:对抗训练能“去伪存真”,消除数据分布差异的影响,就像学方言,先区分“这是四川话还是广东话”,再学具体词汇,就能避免混淆。
工程机械的“跨机型故障诊断”
三一重工2026年推出新一代智能挖掘机,但老用户反映:“新机型故障代码和老机型不一样,维修手册看不懂。”工程师用数字孪生平台做了个迁移学习模型:先在老机型的故障数据上训练“故障-代码”映射关系,再把新机型的故障代码“翻译”成老机型的表述方式,比如新机型的“E001”对应老机型的“液压泵过热”,维修人员直接按老经验处理就行,现在新机型的故障处理时间缩短了60%。 关注储能技术与语言培训及托育服务发展动态,技术创新推动产业升级
知识点7:迁移学习能“破译代码”,解决数据标注不一致的问题,就像翻译古文,先理解“之乎者也”的现代含义,再解读全文就容易多了。
食品工厂的“跨产品配方优化”
某大型食品企业有10条生产线,生产饼干、蛋糕、面包等不同产品,2026年想开发一款新口味饼干,但传统方法需要做上百次实验,耗时3个月,数字孪生平台用了迁移学习的“零样本学习”技术:先在现有产品的配方数据上训练模型,让模型学会“面粉、糖、油的比例如何影响口感”,再输入新饼干的“目标口感”(更酥脆”),模型直接推荐最优配方,结果只做了12次实验就成功,开发周期缩短到2周。
知识点8:零样本学习能“无中生有”,用已有知识解决新问题,就像厨师学做新菜,不用从头试错,参考现有菜谱就能创新。
船舶制造的“跨船型设计优化”
江南造船厂2026年同时设计3种船型:集装箱船、油轮和液化天然气船,传统方法需要分别做流体动力学仿真,每型船要3个月,数字孪生平台用了迁移学习的“参数共享”技术:把3种船型的共同参数(比如船长、船宽、吃水)放在底层模型,专属参数(比如