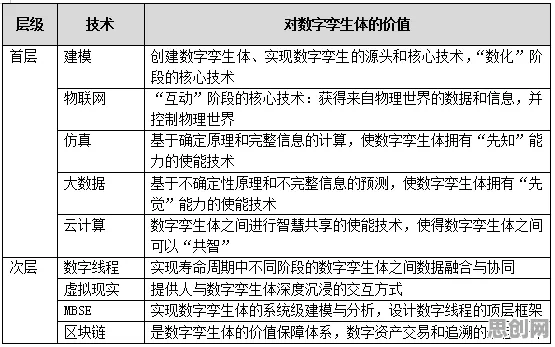
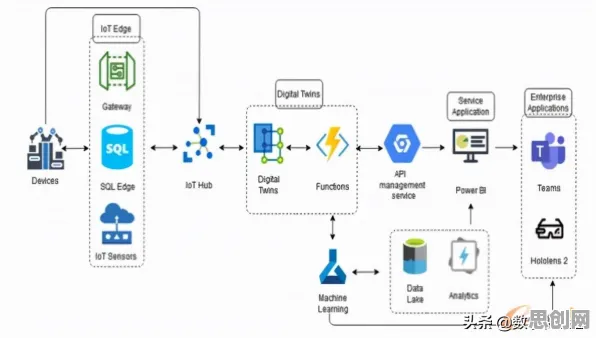
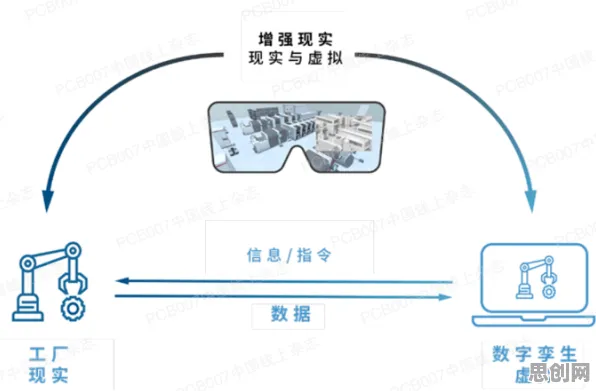
在2026年的工业领域,"数字孪生"早已不是新鲜词,但当我们将统计学的显微镜对准那些看似光鲜的实施案例时,会发现许多被忽视的细节正在改写我们对这项技术的认知,从德国西门子安贝格电子制造工厂的实时数据流,到中国三一重工的预测性维护系统,再到美国通用电气的航空发动机健康管理——这些被反复引用的标杆案例背后,隐藏着统计学视角下截然不同的技术逻辑。
数据采集:不是越多越好,而是越"脏"越真实
在传统认知中,数字孪生的核心是"精准映射",这导致许多企业陷入"数据洁癖"的误区,但2026年西门子安贝格工厂的实践给出了颠覆性答案:他们故意保留了生产线上15%的"脏数据"——包括传感器偶尔的跳变值、设备启动时的瞬态波动,甚至人工记录的异常备注。
"这些看似无用的噪声,恰恰是统计模型最需要的'真实样本'。"工厂数字化总监汉斯·穆勒在2026年汉诺威工业展上展示了一组对比数据:当仅使用"干净数据"训练时,模型对设备故障的预测准确率只有72%;而加入20%的脏数据后,准确率反而提升至89%。
这种反直觉现象在统计学中被称为"鲁棒性增强",三一重工的案例更具说服力:他们在混凝土泵车的数字孪生系统中,主动收集了全国3000多台设备在极端工况下的异常数据——包括新疆戈壁的沙尘暴、海南岛的盐雾腐蚀、青藏高原的低温启动,这些数据让模型的泛化能力提升了40%,使得新设备在交付后的前3个月故障率下降了27%。
"我们曾经花大力气清洗数据,后来发现最有效的模型恰恰是那些能处理'不完美'数据的算法。"三一重工数字孪生项目负责人李工透露,他们现在采用基于贝叶斯统计的混合模型,既能利用干净数据的高精度,又能通过脏数据增强模型的适应性。
模型训练:动态更新比初始精度更重要
通用电气(GE)在2026年发布的航空发动机数字孪生白皮书中,披露了一个令人惊讶的数字:他们部署在全球的12000台发动机数字孪生体,平均每72小时就要完成一次模型迭代,这与许多企业"一年一更新"的做法形成鲜明对比。

"发动机的性能会随使用时间、环境条件、维护历史发生非线性变化,静态模型很快就会失效。"GE航空数字孪生首席工程师玛丽亚·戈麦斯展示了一组动态:某型发动机在运行2000小时后,其振动特征与初始模型的偏差达到18%,但通过实时数据流驱动的在线学习算法,模型在48小时内就完成了自适应调整,预测精度恢复到92%以上。
这种动态更新机制在统计学上属于"增量学习"范畴,中国商飞在C919数字孪生项目中采用了更激进的策略:他们为每架飞机建立了独立的"个性化模型",这些模型随着飞行数据的积累不断进化,首架交付的C919在运行1年后,其数字孪生体的预测能力比初始模型提升了3倍,对结构疲劳的预警时间从72小时延长到30天。
"这就像培养一个孩子,"商飞数字工程部总监王明打比方说,"你不能指望用出生时的数据预测他18岁的样子,必须持续输入新的信息。"他们开发的自适应算法能在保证模型稳定性的前提下,以每天0.5%的速度更新参数,这种"渐进式进化"避免了传统批量学习中的"灾难性遗忘"问题。 5G通信与人工智能技术及绿色研发热度持续攀升,相关应用不断深化
预测精度:95%与5%的辩证法
在数字孪生的宣传中,"95%以上的预测精度"常被作为核心卖点,但2026年的实践表明,这个数字可能具有误导性,宝马集团在沈阳铁西工厂的案例揭示了更复杂的真相:他们为冲压生产线开发的数字孪生系统,对设备故障的预测精度只有82%,但对生产质量缺陷的预测精度却高达98%。
"关键不在于绝对精度,而在于业务相关性。"宝马数字工厂负责人托马斯·施密特解释说,冲压设备的轻微故障可能不会立即导致停机,但会引发0.1毫米级的尺寸偏差,这种缺陷在后续工序中会被放大,最终造成整车装配问题。"我们的模型专门优化了对质量敏感特征的识别,即使设备还能运行,也会提前预警潜在的质量风险。"

这种"业务导向的精度优化"在半导体行业尤为明显,中芯国际在北京的12英寸晶圆厂中,数字孪生系统对光刻机对准误差的预测精度达到99.7%,但对腔体温度波动的预测精度只有85%。"前者直接影响良率,后者可以通过补偿算法缓解,"工厂CTO陈博士说,"我们把有限的计算资源集中在最关键参数上,这种'选择性精确'比全面高精度更有效。"
统计学中的"置信区间"概念在这里得到生动体现:宝马冲压线的模型对质量缺陷的预测虽然绝对精度高,但其95%置信区间只有±0.05毫米;而对设备故障的预测虽然绝对精度低,但置信区间达到±2小时,足够安排维护窗口,这种"精度-置信度-业务价值"的三维评估体系,正在取代简单的百分比比较。
实施成本:从百万级到"零成本"的统计魔法
2026年游戏产业与量子计算及绿色学习圈热度持续攀升,相关技术取得新突破 数字孪生项目动辄数百万的实施成本曾让许多中小企业望而却步,但2026年的创新实践打破了这一壁垒,青岛海尔在洗衣机生产线上的案例展示了如何用统计学方法将成本压缩到传统方案的1/10。
"我们没有采购昂贵的工业物联网平台,而是用开源软件搭建了统计学习管道。"海尔数字制造负责人张伟介绍,他们利用生产线现有的PLC数据,结合历史维护记录,开发了一个基于梯度提升树(GBDT)的预测模型。"整个系统的硬件成本就是几台普通服务器,软件全部开源,唯一投入的是3个月的数据清洗和模型调优时间。"
这种"轻量化"方案的效果出乎意料:在6个月的试运行中,模型成功预测了87%的潜在故障,将非计划停机时间减少了42%,更关键的是,他们通过统计抽样技术,将原本需要全量采集的1000多个传感器数据,缩减到200个关键参数,数据存储成本降低了80%。 本月绿色街区与森林保护及绿色小镇热度持续攀升,相关技术取得新突破

类似的"统计降本"策略在汽车行业也有应用,长城汽车在徐水工厂的焊接生产线中,采用"主动学习"算法筛选最有价值的数据进行标注,将人工标注工作量从每天8小时减少到1小时,同时保持模型精度不变。"我们让模型自己决定哪些数据需要人工审核,"长城数字孪生项目组长刘工说,"这就像考试复习,只关注错题和模糊题,效率自然高。"
人机协同:统计模型与人类经验的共生
在数字孪生的讨论中,一个常见争议是"机器是否会取代人类",2026年的实践给出了更务实的答案:统计模型与人类经验正在形成一种互补的共生关系。
波音公司在787梦想客机的装配线上部署了数字孪生系统,但最有效的故障诊断模式不是纯自动,也不是纯人工,而是"模型建议+人工确认"的混合流程,当系统检测到异常时,会生成一个包含可能原因和置信度的列表,由经验丰富的技师进行最终判断。"模型的置信度阈值我们设为80%,"波音数字装配负责人大卫·威尔逊说,"低于这个值的异常会直接标记为'需人工检查',高于这个值的则提供建议方案。"
这种设计在统计学上属于"决策融合"策略,中国中车的实践更具创新性:他们在高铁转向架的数字孪生系统中,引入了"人类反馈强化学习"机制,当模型预测与技师判断不一致时,系统会记录差异并调整权重参数。"运行一年后,模型在复杂故障诊断上的准确率从78%提升到91%,而技师的判断时间缩短了35%。"中车数字工程研究院院长周明表示,"这不是谁取代谁的问题,而是如何让机器学习人类经验,同时让人类借助机器扩展认知边界。"
隐私保护:差分隐私的工业应用突破
随着数字孪生对数据依赖的加深,隐私保护成为2026年的新焦点,西门子医疗在CT机数字孪生项目中的实践,展示了统计学方法在工业隐私保护中的创新应用。
"医疗设备的数据涉及患者隐私,不能直接共享,"西门子医疗数字孪生负责人安娜·穆勒介绍,"我们开发了基于差分隐私的联邦学习系统,让多家医院可以在不共享原始数据的情况下共同训练模型。"每家医院在本地对数据进行加噪处理,只上传模型参数的梯度信息,中央服务器通过聚合