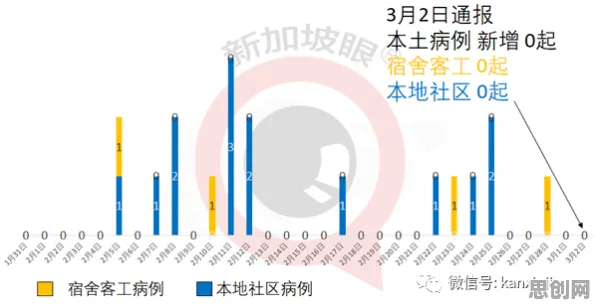
在工业4.0的浪潮中,"数字孪生"早已不是实验室里的概念,而是成为全球制造业转型升级的核心抓手,从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",从波音飞机的全生命周期管理到特斯拉上海超级工厂的实时优化,数字孪生技术正在重构工业生产的底层逻辑,但要让这项技术真正落地,必须抓住一个关键——数据挖掘,它就像数字孪生的"神经中枢",决定了虚拟模型能否精准映射物理世界,更决定了企业能否从海量数据中提取出真正的价值。
数字孪生的"双胞胎"困境:没有数据挖掘,模型就是摆设
很多人对数字孪生的理解还停留在"建个3D模型"的层面,但2026年全球工业互联网联盟(IIC)发布的《数字孪生技术成熟度白皮书》明确指出:真正的数字孪生必须实现"物理实体-虚拟模型-数据服务"的三维闭环,这意味着,仅仅搭建一个外观相似的虚拟模型远远不够,必须通过数据挖掘让模型"活"起来——能实时感知物理实体的状态变化,能预测潜在故障,能优化生产参数,甚至能反向控制物理设备。
以中国某汽车零部件制造商的案例为例,2025年,该企业投入数百万元建设了冲压生产线的数字孪生系统,模型精度达到毫米级,但运行半年后发现:虚拟模型只能显示设备当前状态,无法预测模具磨损;能模拟生产过程,却无法提出效率优化建议,问题出在哪里?原来,他们的数据采集仅覆盖了设备运行参数,却忽略了模具温度、液压油压力、环境湿度等关键变量;数据存储是孤岛式的,冲压机、机械臂、AGV的数据各自为政;更关键的是,缺乏有效的数据挖掘算法,无法从TB级数据中识别出影响质量的"隐形因子"。 6月绿色水处理领域取得重要进展,行业关注度持续提升
2026年,该企业引入了基于机器学习的数据挖掘平台,对历史生产数据进行深度分析,系统发现:当模具温度超过85℃且液压油压力波动超过5%时,产品次品率会上升30%;而通过调整AGV的送货节奏,可以使冲压机的空闲时间减少18%,基于这些发现,数字孪生模型不仅能实时预警模具磨损,还能自动生成最优生产参数组合,实施后,设备综合效率(OEE)提升了12%,模具寿命延长了25%。
这个案例揭示了一个残酷的现实:没有数据挖掘的数字孪生,就像没有大脑的机器人——外观再精致,也无法真正创造价值。 2026年绿色物流与机构养老及基因检测热度持续攀升,相关领域迎来新突破
数据挖掘的"三板斧":从原始数据到工业智能的跨越
要让数字孪生"活"起来,数据挖掘必须解决三个核心问题:数据质量、关联分析和预测能力,这就像烹饪一道大餐——原料要新鲜(数据质量),火候要精准(关联分析),调味要到位(预测能力)。
第一板斧:数据清洗与融合——让"脏数据"变"金矿"
工业现场的数据往往是"脏"的:传感器故障导致的数据缺失、不同设备协议导致的格式混乱、人工录入错误导致的异常值……据GE数字集团2026年的统计,工业数据中平均有35%是无效数据,如果直接用这些数据训练模型,结果必然是"垃圾进,垃圾出"。
某钢铁企业的案例很有代表性,2025年,他们为高炉建设数字孪生模型时,发现温度传感器的数据波动异常大,起初以为是传感器质量问题,更换后问题依旧,后来通过数据挖掘发现:问题出在数据采集频率上——温度传感器每秒采集10次,而风量传感器每秒只采集1次,两者时间戳不对齐,导致模型误认为温度波动是由风量变化引起的,调整采集频率后,模型预测准确率从62%提升到89%。
更复杂的是多源数据融合,在航空航天领域,一架飞机的数字孪生需要整合结构健康监测数据、发动机性能数据、气象数据、维护记录等数十个数据源,波音公司2026年公开的技术文档显示,他们采用"数据湖+语义网"的架构:先将所有数据存入数据湖,再通过语义网定义数据之间的关系(某个传感器的读数对应飞机的哪个部件"),最后用图计算算法挖掘隐藏的关联,这种方法使故障诊断时间从平均4小时缩短到20分钟。

第二板斧:关联规则挖掘——找出工业现场的"隐形因果链"
工业生产中的很多问题,表面看是独立的,实际却存在复杂的因果关系,设备振动增大可能是轴承磨损,也可能是联轴器对中不良,还可能是基础松动,传统方法靠工程师经验排查,效率低且容易遗漏,数据挖掘可以通过关联规则挖掘,自动发现这些"隐形因果链"。
三一重工的"18号厂房"提供了绝佳案例,这个被称为"亚洲最聪明的工厂"里,每台设备都装有数百个传感器,每天产生200GB数据,2026年,他们的数字孪生系统通过Apriori算法挖掘出一条关键规则:当焊接机器人的电流波动超过5%且气压下降超过3%时,焊缝缺陷率会上升40%,进一步分析发现,电流波动是由电源模块老化引起的,气压下降则是空压机滤芯堵塞导致的,基于这条规则,系统能提前3天预测焊缝缺陷,并将维护计划从"定期更换"改为"按需更换",使滤芯使用寿命延长了40%。
更高级的关联分析是"时空关联",在化工生产中,反应釜的温度、压力、流量等参数不仅相互影响,还与时间序列和空间位置相关,巴斯夫公司2026年发布的专利技术显示,他们用时序图神经网络(TGNN)挖掘反应过程中的时空关联,使产品收率提高了2.3个百分点——对于年产值百亿的化工企业,这相当于多赚2.3亿元。
第三板斧:预测模型构建——让数字孪生"未卜先知"
数字孪生的最高境界是预测性维护和生产优化,这需要基于历史数据构建高精度的预测模型,而数据挖掘是核心工具。
特斯拉上海超级工厂的案例很有说服力,2026年,他们的数字孪生系统通过LSTM神经网络对冲压机的历史故障数据进行学习,发现:当振动频谱中1200Hz成分的能量超过阈值,且持续超过15分钟时,轴承会在未来72小时内发生故障,基于这个模型,系统能提前发出预警,并推荐最优的停机维护时间——既避免意外停机,又最大化设备利用率,实施后,冲压线的平均无故障时间(MTBF)从450小时提升到720小时。

在能源领域,西门子的燃气轮机数字孪生系统更进一步,他们用强化学习算法训练模型:让虚拟模型在数字空间中"试错",不断调整燃烧参数,寻找效率与排放的最佳平衡点,2026年实测显示,优化后的燃烧参数使氮氧化物排放降低了18%,热效率提升了0.8个百分点——对于一台400MW的燃气轮机,这相当于每年减少二氧化碳排放12万吨,多发电2800万度。
实施数字孪生的"避坑指南":数据挖掘的三大陷阱
尽管数据挖掘是数字孪生的核心,但实施过程中容易陷入三个陷阱,必须警惕。
过度追求算法复杂度,忽视业务理解
有些企业迷信"高级算法",认为用深度学习就一定比传统机器学习好,但2026年麦肯锡的调研显示:在工业场景中,60%的数字孪生项目失败是因为算法与业务需求脱节,某半导体企业用GAN(生成对抗网络)预测晶圆缺陷,结果模型在测试集上表现很好,实际生产中却漏检了关键缺陷类型——原因是训练数据中缺陷样本太少,GAN生成了大量"虚假完美"样本,导致模型"过拟合",后来改用基于物理模型的混合算法,问题才解决。
远程医疗与环境监测及平台治理领域取得重要进展,行业关注度持续提升 关键启示:算法是工具,业务是目的,必须先明确要解决什么问题(如预测故障、优化参数),再选择合适的算法。
数据孤岛未打破,模型"瞎子摸象"
工业数据往往分散在PLC、SCADA、MES、ERP等多个系统中,格式不统一,权限不共享,某化工企业的案例很典型:他们为反应釜建数字孪生模型时,发现模型预测的产物收率与实际偏差很大,调查发现,模型只用了DCS中的温度、压力数据,却没接入实验室信息管理系统(LIMS)中的原料纯度数据——而后者对收率影响更大,后来通过数据中台整合多源数据,模型准确率才显著提升。
关键启示:数字孪生