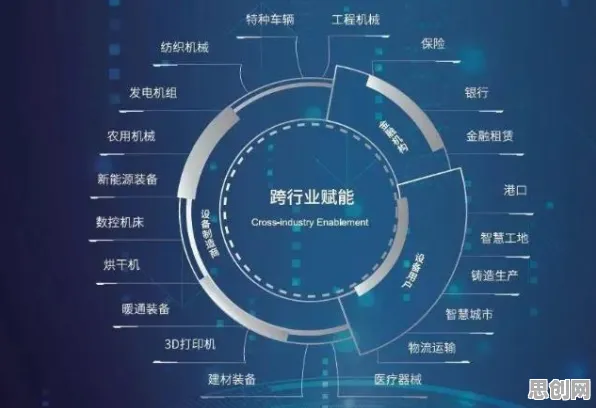
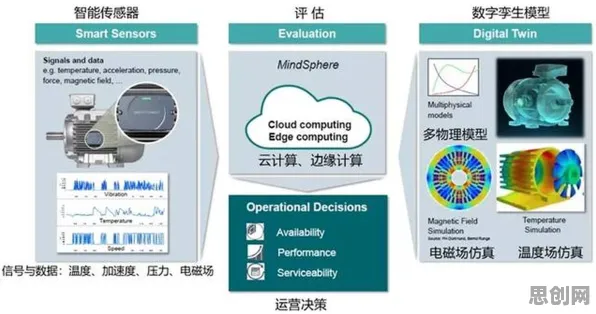
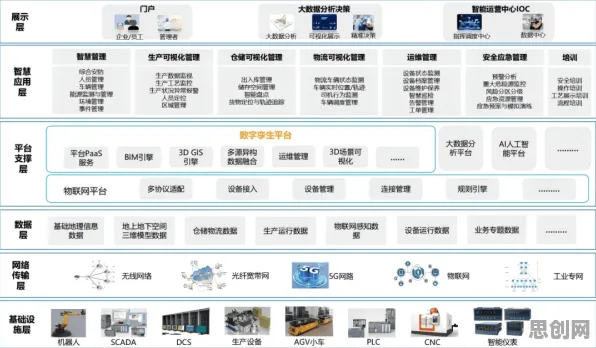
联邦学习如何破解工业数据孤岛?
工业数据分散在设备、工厂、供应链各环节,传统集中式建模需将数据汇总至云端,不仅面临传输延迟,更存在隐私泄露风险,联邦学习通过“本地训练+联邦聚合”的模式,让各参与方在本地数据上训练模型,仅共享模型参数而非原始数据,从而打破数据壁垒。
案例1:汽车零部件供应商的跨工厂协同
2026年,全球最大汽车零部件供应商博世(Bosch)在德国、中国、墨西哥的12家工厂部署了基于联邦学习的数字孪生系统,每家工厂的数控机床、机器人等设备数据留在本地,仅上传模型梯度至联邦服务器,通过横向联邦学习(Horizontal Federated Learning,即各参与方数据特征相同、样本不同),系统训练出能预测设备故障的通用模型,准确率较单一工厂模型提升23%,更关键的是,德国工厂的精密加工数据、中国工厂的柔性生产数据、墨西哥工厂的低成本制造数据均未离开本地,避免了商业机密泄露。
案例2:钢铁企业的供应链数据融合
中国宝武钢铁集团在2026年联合上游铁矿石供应商、下游汽车制造商,构建了覆盖“采矿-炼钢-轧制-汽车制造”全链条的数字孪生体,由于各环节数据格式、采样频率差异巨大,传统方法难以整合,通过纵向联邦学习(Vertical Federated Learning,即各参与方样本相同、数据特征不同),系统将宝武的炼钢温度、供应商的铁矿石成分、汽车厂的板材性能等数据对齐,训练出能优化整个供应链的模型,模型建议将某批次铁矿石的配比从15%调整至18%,使汽车板材的屈服强度提升12%,同时降低炼钢能耗8%。
联邦学习在工业数字孪生中的技术突破
联邦学习并非简单“分布式训练”,在工业场景中需解决模型异构、通信延迟、动态参与等复杂问题,2026年的实践显示,以下技术方向成为关键突破口。 6月份社区服务热度飙升,相关产业迎来新机遇
发现1:异构模型联邦训练的“翻译器”
工业设备型号多样,不同工厂可能使用不同品牌的PLC(可编程逻辑控制器)或传感器,导致数据格式、模型结构差异大,西门子在2026年推出的“工业联邦学习中间件”,通过模型转换层将不同架构的模型(如TensorFlow、PyTorch、ONNX)统一为标准格式,再参与联邦训练,某汽车工厂的德国设备使用TensorFlow模型,中国设备使用PyTorch模型,中间件将两者转换为ONNX后聚合,训练效率提升40%。
发现2:边缘计算与联邦学习的深度融合
工业场景对实时性要求极高,模型训练需在靠近数据的边缘设备完成,华为在2026年发布的“工业联邦学习边缘网关”,将联邦学习框架集成至5G工业路由器,支持在网关侧完成模型训练和参数聚合,某风电场通过该网关,在风机本地训练故障预测模型,每10分钟将参数上传至区域联邦服务器,较传统云端训练延迟从秒级降至毫秒级,成功捕捉到一次因齿轮箱振动异常导致的停机前兆,避免损失超200万元。
发现3:动态参与下的模型鲁棒性
工业环境中,设备可能因维护、故障或网络问题临时退出联邦训练,通用电气(GE)在2026年针对航空发动机数字孪生体的联邦学习系统,引入“动态权重调整”机制:当某台发动机的数据连续3次未上传时,系统自动降低其模型参数在聚合中的权重,避免因数据缺失导致模型偏差,该机制在GE全球1.2万台在役发动机的部署中,使模型预测准确率波动从±5%降至±1.5%。

安全与合规:工业联邦学习的“红线”
工业数据涉及商业秘密、国家安全(如军工企业),联邦学习需满足GDPR、中国《数据安全法》等法规要求,2026年的实践显示,以下安全技术成为标配。
发现4:差分隐私的“可调节保护”
差分隐私通过在模型参数中添加噪声保护数据隐私,但过度添加会降低模型性能,施耐德电气在2026年推出的“自适应差分隐私模块”,可根据数据敏感度动态调整噪声强度,对于设备运行时间等低敏感数据,噪声强度设为0.1;对于故障代码等高敏感数据,噪声强度设为0.5,该模块在施耐德全球50家工厂的部署中,使模型准确率仅下降3%,同时通过ISO/IEC 27701隐私信息管理体系认证。
发现5:区块链存证的“不可篡改审计”
联邦学习需确保模型参数聚合过程透明可追溯,中国航天科工集团在2026年为某军工企业的数字孪生系统部署了区块链存证模块,每次参数聚合后,将聚合结果、参与方ID、时间戳等信息上链,当某次聚合结果被质疑时,可通过区块链查询发现:某参与方在聚合前10分钟上传了异常参数,系统自动将其排除并重新聚合,避免了模型被恶意攻击。
发现6:联邦学习的“合规性检查清单”
2026年,德国TÜV莱茵集团发布了《工业联邦学习合规指南》,列出12项关键检查项,包括数据分类分级、模型加密方式、参与方身份认证等,某汽车制造商在部署联邦学习前,需证明其系统能区分“公开数据”(如设备型号)、“内部数据”(如生产计划)、“机密数据”(如工艺参数),并针对不同级别数据采用不同保护措施,否则无法通过欧盟AI法案审核。
 2026年新能源汽车与全民健身及数据安全热度持续攀升,相关应用不断深化
2026年新能源汽车与全民健身及数据安全热度持续攀升,相关应用不断深化
性能优化:让联邦学习“跑得更快”
2026年绿色城市与自行车骑行运动及绿色重建发展迅速,技术创新带来新突破 工业场景对模型训练速度、资源消耗敏感,联邦学习需通过算法优化、硬件加速等手段提升性能。
发现7:模型压缩的“工业级方案”
工业设备算力有限,需压缩模型以减少传输和计算负担,ABB在2026年推出的“联邦学习模型压缩工具”,通过知识蒸馏将大模型(如ResNet-50)压缩为轻量级模型(如MobileNetV2),同时保持90%以上的准确率,某机器人工厂的视觉检测模型从200MB压缩至20MB,上传时间从10秒降至1秒,边缘设备推理速度提升5倍。
发现8:通信优化的“分层聚合”
工业网络带宽有限,联邦学习需减少参数传输量,三一重工在2026年针对其全球200个工地的混凝土泵车数字孪生系统,采用“分层聚合”策略:工地级网关先聚合本地设备参数,再上传至区域级服务器聚合,最后上传至全球级服务器,该策略使通信量减少70%,模型更新周期从1小时缩短至15分钟,成功预测到一次因液压系统压力异常导致的泵车故障。
发现9:硬件加速的“专用芯片”
联邦学习涉及大量矩阵运算,通用CPU效率低下,英特尔在2026年推出的“工业联邦学习加速卡”,集成专用AI芯片,可并行处理16路模型参数聚合,某芯片制造企业的光刻机数字孪生系统,使用该加速卡后,模型训练速度从8小时/轮降至1小时/轮,使光刻机工艺参数优化周期从每月1次提升至每周2次。
行业应用:从制造到能源的全面渗透
2026年智慧农业与绿色城市及数据安全热度持续上升,相关领域迎来新机遇 联邦学习正从制造业向能源、交通等领域扩展,2026年的实践显示,不同行业的部署方案差异显著。
案例3:电力系统的“跨区域负荷预测”
国家电网在2026年联合南方电网、内蒙古电网,构建了覆盖全国的电力负荷预测数字孪生体,由于各电网数据格式、用户类型不同,采用纵向联邦学习:国家电网提供历史负荷数据,南方电网提供气候数据