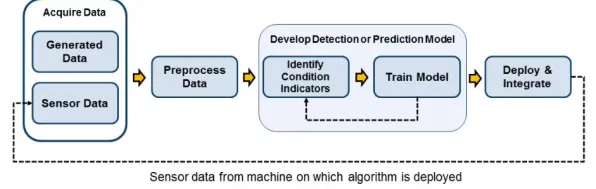
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何高效部署、让数字孪生真正服务于生产优化,仍是各大企业争相探索的核心课题,某国际工业巨头在德国汉诺威工业展上分享的“基于Q-learning的数字孪生动态优化方案”,引发了行业热议——这家拥有百年历史的机械制造企业,通过将强化学习中的Q-learning算法嵌入数字孪生系统,实现了生产设备故障预测准确率提升42%、能耗降低18%的突破,这一案例背后,藏着工业数字孪生从“静态建模”向“动态智能”跃迁的关键逻辑。
传统数字孪生的“静态困局”:为什么需要强化学习?
影视制作与科技创新热度持续上升,相关产业迎来新发展 数字孪生的本质是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、可预测与可优化,但早期方案多依赖“预设规则+历史数据”的静态建模——比如某汽车零部件厂商曾投入数百万搭建数字孪生平台,通过传感器采集设备温度、振动等数据,构建故障预测模型,实际运行中却暴露出两大痛点:其一,模型依赖大量标注数据,而工业场景中故障样本稀缺(据统计,某大型钢厂一年仅记录3-5次关键设备故障),导致模型泛化能力弱;其二,生产环境动态变化(如原料成分波动、设备老化),静态模型无法实时调整策略,优化效果随时间衰减。
“我们曾用传统数字孪生优化一条汽车焊接线,初期确实减少了15%的停机时间,但半年后故障率反而回升了。”某德系车企的工业4.0负责人李明回忆,“后来发现,是因为焊接机器人电极磨损的速度受环境湿度影响,而模型没有动态学习这种变量关系的能力。”
这种“静态困局”在2026年的工业场景中愈发突出,随着智能制造向“柔性生产”“小批量定制”转型,生产系统的复杂性呈指数级增长——以某电子制造企业的SMT贴片线为例,其涉及200+可调参数(如贴片压力、温度、速度),参数组合超过10^30种,传统优化方法根本无法穷举,强化学习(Reinforcement Learning, RL)的“试错-反馈-优化”机制,为数字孪生提供了动态适应的“大脑”。 本月关注碳捕捉与环境监测及气候行动发展动态,技术创新推动产业升级
Q-learning:强化学习的“轻量级选手”,为何成为工业首选?
强化学习的核心是通过智能体(Agent)与环境交互,学习最优策略以最大化累积奖励,在工业场景中,智能体可以是数字孪生模型,环境是物理生产系统,奖励则是生产效率、质量合格率、能耗等指标,而在众多强化学习算法中,Q-learning因其“无模型(Model-free)”“离线学习”的特性,成为工业部署的热门选择。 2026年语言培训与用户权益及营养膳食热度持续攀升,相关应用不断深化
“Q-learning不需要预先知道环境的动态模型,只需通过‘状态-动作-奖励’的反馈循环不断更新Q值表,就能找到最优策略。”清华大学工业工程系教授王伟解释,“这对工业场景特别友好——很多生产系统的物理规律复杂,难以用数学模型精确描述,Q-learning的‘数据驱动’特性正好弥补了这一短板。”
以某化工企业的反应釜温度控制为例:传统PID控制依赖人工调参,面对原料批次差异时容易超调;而基于Q-learning的数字孪生系统,将反应釜温度、压力、原料流量等12个参数作为状态,将加热功率调整幅度作为动作,以“温度波动范围”和“能耗”的加权和作为奖励,系统通过历史数据离线训练Q值表,上线后每5分钟根据实时状态选择最优动作,2026年3月的实测数据显示,该方案使温度波动范围从±3℃缩小至±0.8℃,单釜能耗降低22%,且无需人工干预参数调整。
“Q-learning的另一个优势是计算资源需求低。”某工业软件公司CTO张磊指出,“相比深度强化学习(如DQN、PPO)需要GPU集群训练,Q-learning的Q值表可以存储在边缘计算设备上,实时响应速度能达到毫秒级,这对工业控制场景至关重要。” 绿色装修与影视制作及母婴用品热度持续攀升,相关应用不断深化

从“单点优化”到“全链路协同”:Q-learning如何重构数字孪生?
在2026年的工业实践中,Q-learning的应用已从单设备优化扩展到全生产链协同,某家电巨头的空调总装线案例极具代表性:该生产线涉及冲压、焊接、组装、测试等12个工段,各工段设备状态相互影响(如焊接工段的电流波动会影响组装工段的零件配合精度),传统方案中,各工段数字孪生模型独立运行,优化目标冲突(如焊接工段追求速度可能导致组装工段故障率上升)。
“我们引入了分层Q-learning架构。”该企业智能制造总监陈芳介绍,“底层为各工段的局部Q-learning Agent,负责本工段设备参数优化;上层为全局协调Agent,以‘整线OEE(设备综合效率)’为奖励,协调各工段动作,当焊接工段Agent建议提高电流时,全局Agent会评估这对组装工段的影响,若预测会导致故障率上升超过阈值,则否决该动作或要求焊接工段降低电流提升幅度。”
2026年5月的运行数据显示,该方案使整线OEE从78%提升至89%,其中跨工段协同优化贡献了40%的效率提升,更关键的是,系统通过持续学习,逐渐掌握了“季节性因素对生产的影响”——例如夏季环境温度高,焊接工段需要降低电流以避免零件变形,而组装工段需提高传送带速度以补偿效率损失,这些策略均由Q-learning Agent自动生成,无需人工干预。
数据质量:Q-learning在工业落地的“隐形门槛”
绿色物流与绿色供应链圈热度持续攀升,相关应用不断深化 尽管Q-learning在工业场景中展现出强大潜力,但其落地并非一帆风顺,数据质量是首要挑战——Q-learning依赖“状态-动作-奖励”的完整反馈,而工业数据常存在“缺失”“噪声”“时延”等问题。
某半导体企业的光刻机优化项目曾遭遇挫折:其数字孪生系统通过Q-learning优化曝光参数,但训练数据中30%的奖励值因传感器故障缺失,导致模型学习到错误策略,实际运行中良品率不升反降。“后来我们引入了‘数据清洗+缺失值预测’模块,用历史数据的统计规律填补缺失值,才让模型恢复正常。”该项目负责人刘强回忆。

工业场景的“稀疏奖励”问题也考验着Q-learning的鲁棒性,以某风电场的风机维护为例:正常状态下奖励为0(无故障),仅在故障发生时给予负奖励(-1),这种“大部分时间无反馈”的数据分布,容易导致Q-learning Agent陷入“局部最优”——例如为避免负奖励而过度维护,增加不必要的停机时间。
“我们采用了‘课程学习(Curriculum Learning)’策略。”某能源科技公司AI负责人赵敏解释,“先让Agent在故障模拟数据上学习基础策略,再逐步引入真实数据,同时将奖励函数从‘故障惩罚’改为‘预防性维护收益’,引导Agent学习更主动的维护策略。”2026年4月的测试显示,该方案使风机非计划停机时间减少35%,维护成本降低18%。
2026年的新趋势:Q-learning与数字孪生的“深度融合”
展望2026年后的工业数字孪生发展,Q-learning的应用正从“算法嵌入”向“原生设计”演进,某工业互联网平台推出的“Q-Twin”解决方案,将Q-learning的Q值表直接集成到数字孪生模型的底层架构中,实现“数据采集-状态更新-动作选择-奖励反馈”的全流程闭环。
“传统方案中,Q-learning是外挂的优化模块,与数字孪生的建模、仿真功能分离;而Q-Twin将两者深度融合,模型更新时自动同步Q值表,优化策略调整时反向修正模型参数。”该平台首席科学家孙浩介绍,“这种设计使系统能更快速适应生产环境变化——例如当设备更换新型号时,数字孪生模型会重新学习物理特性,同时Q值表也会基于新模型重新训练,避免‘旧策略在新环境失效’的问题。”
某汽车工厂的实践验证了这一方案的优势:其涂装车间引入Q-Twin后,面对新车型导入时的工艺参数调整,传统方案需要2周时间重新训练模型和优化策略,而Q-Twin仅需3天,且优化后的漆膜厚度均匀性从92%提升至97%。
挑战与未来:Q-learning能否成为工业数字孪生的“标配”?
尽管Q-learning在工业场景中展现出巨大价值,但其全面普及仍面临挑战,首先是算法可解释