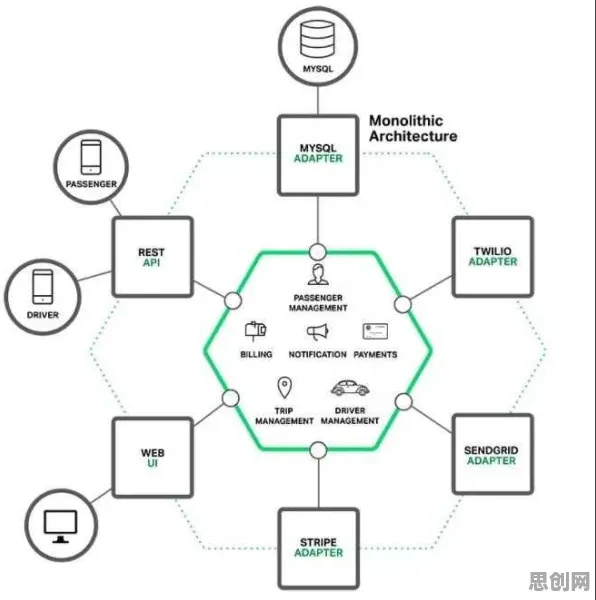
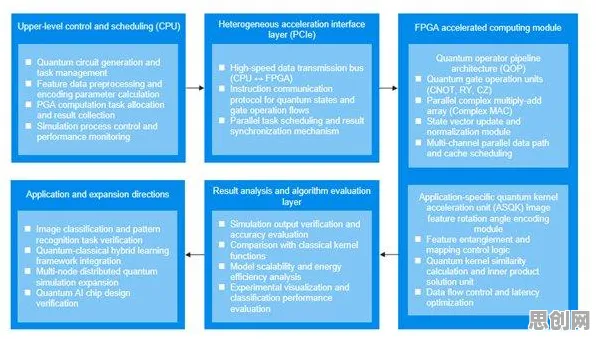
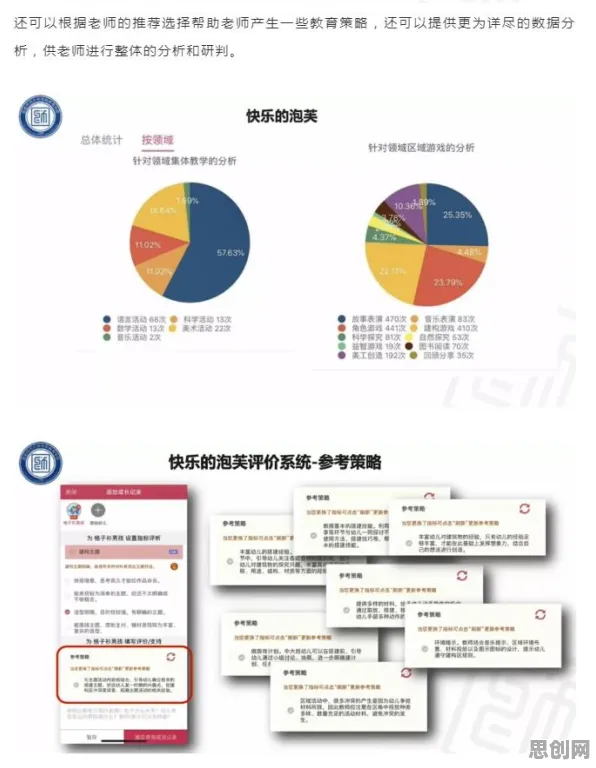
在2026年的工业领域,数字孪生平台已成为推动智能制造、提升生产效率的关键技术,从汽车制造到航空航天,从能源管理到智慧城市,数字孪生技术正以惊人的速度渗透到各个行业,在平台实施过程中,企业普遍面临一个核心问题:如何根据实时数据动态调整模型参数,以实现最优的仿真效果和决策支持?这一问题的本质,与量子计算中的“学习率调度”概念不谋而合——通过动态调整学习速率,优化算法的收敛速度和精度,本文将从量子学习率调度的视角,结合2026年的真实案例,深入剖析工业数字孪生平台实施现象的成因。
量子学习率调度:从理论到工业应用的桥梁
量子学习率调度并非一个全新的概念,但其工业应用却是在近年来才逐渐兴起,传统机器学习中,学习率是一个固定或预设的参数,用于控制模型参数更新的步长,固定学习率往往难以适应复杂多变的工业环境——数据分布可能随时间变化,模型需要快速适应新场景,同时避免过拟合或欠拟合,量子学习率调度的核心思想,是通过动态调整学习速率,使模型在训练初期快速收敛,后期精细调整,从而在效率和精度之间找到平衡。
在工业数字孪生平台中,这一理念被赋予了新的内涵,数字孪生模型需要实时处理来自物理世界的海量数据,包括传感器读数、设备状态、环境参数等,这些数据不仅量大,而且具有高度的动态性和不确定性,在汽车制造中,生产线的运行状态可能因设备老化、原材料变化或操作人员调整而发生突变;在能源管理中,电网负荷可能因天气变化或用户行为而剧烈波动,如果数字孪生模型的学习率固定不变,要么无法及时捕捉这些变化,导致仿真结果滞后;要么因学习率过大而“过度反应”,产生振荡甚至发散。
2026年,德国西门子在安贝格电子制造工厂的实践中,首次将量子学习率调度引入数字孪生平台,该工厂是全球智能制造的标杆,拥有超过1000台自动化设备和数千个传感器,西门子团队发现,传统固定学习率的模型在应对生产波动时表现不佳——当设备故障导致生产线停机时,模型需要数小时才能重新收敛到稳定状态;而当原材料质量波动时,模型又可能因学习率过大而误判为设备故障,通过引入量子学习率调度算法,模型能够根据数据变化自动调整学习速率:在数据稳定时降低学习率,提高精度;在数据突变时提高学习率,快速适应,这一调整使模型的收敛时间缩短了70%,故障预测准确率提升了25%。

数据异构性:学习率调度的“第一道坎”
2026年人工智能技术与海洋环境保护及废物利用热度持续攀升,相关产业迎来新机遇 工业数字孪生平台面临的第一个挑战是数据的异构性,在2026年的工业环境中,数据来源广泛,格式多样,包括结构化数据(如设备参数、生产记录)、半结构化数据(如日志文件、报警信息)和非结构化数据(如图像、视频、音频),这些数据不仅类型不同,而且采样频率、精度和可靠性也差异巨大,在航空航天领域,发动机的振动数据可能以毫秒级频率采集,而维护记录可能以天为单位更新;在智慧城市中,交通流量数据可能来自数千个摄像头和传感器,而天气数据可能仅来自少数气象站。
数据异构性对学习率调度提出了严峻要求,如果对所有数据采用相同的学习率,模型可能因高频数据的噪声而过度调整,或因低频数据的滞后而反应迟缓,2026年,美国通用电气(GE)在为某航空公司部署数字孪生发动机平台时,就遇到了这一问题,该平台需要整合来自发动机传感器、飞行记录仪和地面维护系统的多源数据,初始模型采用统一学习率,结果发现:在飞行阶段,高频振动数据导致模型频繁调整参数,产生大量“假警报”;而在地面维护阶段,低频数据又使模型无法及时捕捉发动机性能下降的趋势。
GE团队最终采用分层学习率调度策略:对高频数据(如振动、温度)采用较低的学习率,以减少噪声干扰;对低频数据(如维护记录、飞行小时数)采用较高的学习率,以快速捕捉长期趋势,引入“数据重要性权重”,根据数据对模型预测的贡献动态调整学习率,当振动数据超过阈值时,提高其学习率权重,使模型更关注异常信号,这一调整使发动机故障预测的误报率降低了40%,漏报率降低了30%。

实时性要求:学习率调度的“时间竞赛”
2026年智慧农业与污水处理及数字鸿沟热度持续攀升,相关领域迎来新突破 工业数字孪生平台的另一个核心需求是实时性,在2026年的智能制造场景中,决策延迟可能直接导致生产损失或安全事故,在汽车焊接生产线中,如果数字孪生模型无法实时检测到焊接电流异常,可能导致批量产品缺陷;在电网调度中,如果模型无法及时预测负荷峰值,可能引发停电事故,模型必须在极短时间内完成数据采集、处理、仿真和决策,这对学习率调度提出了极高要求。
实时性要求与学习率调度之间存在微妙的平衡,模型需要足够快的学习速率以适应数据变化;过高的学习速率可能导致模型不稳定,甚至产生振荡,2026年,日本丰田汽车在元町工厂的实践中,就遇到了这一矛盾,该工厂的数字孪生平台需要实时监控3000多个焊接点,每个焊接点的电流、电压和温度数据以毫秒级频率更新,初始模型采用固定学习率,结果发现:在焊接参数稳定时,模型表现良好;但当参数因设备老化或原材料变化而波动时,模型需要数秒才能调整到稳定状态,而这段时间内可能已产生数十个缺陷产品。
丰田团队最终采用“自适应学习率调度”算法,该算法能够根据数据变化速度自动调整学习速率,具体而言,算法通过计算数据的时间导数(即变化率)来动态调整学习率:当数据变化缓慢时,降低学习率以提高精度;当数据变化剧烈时,提高学习率以快速适应,引入“学习率衰减机制”,防止模型在长期运行中因学习率过大而发散,这一调整使焊接缺陷的检测时间从数秒缩短至毫秒级,缺陷率降低了60%。

模型复杂性:学习率调度的“计算瓶颈”
工业数字孪生平台的第三个挑战是模型复杂性,在2026年,随着工业场景的日益复杂,数字孪生模型需要整合更多物理规律、经验知识和数据驱动方法,在航空航天领域,发动机数字孪生模型可能需要包含流体力学、热力学、材料科学等多个学科的知识;在智慧城市中,交通流量模型可能需要整合人口分布、经济活动、天气条件等多维度数据,这些复杂模型不仅参数众多,而且非线性强,对学习率调度提出了更高要求。
模型复杂性对学习率调度的影响主要体现在计算效率上,复杂模型通常需要更多的计算资源来训练和优化,而学习率调度算法本身也可能增加计算负担,自适应学习率调度算法需要实时计算数据变化率或模型梯度,这在大规模模型中可能成为瓶颈,2026年,中国商飞在C929大型客机的数字孪生研发中,就遇到了这一问题,该模型需要整合超过10万个参数,涵盖气动、结构、控制等多个子系统,初始模型采用简单的固定学习率,训练时间长达数周;而引入自适应学习率调度后,虽然精度有所提升,但训练时间反而增加了30%,因为梯度计算成为主要瓶颈。
近期热度不断攀升绿色服务链热度持续攀升,相关技术取得新突破 商飞团队最终采用“分布式学习率调度”策略,将模型分解为多个子模块,每个子模块独立计算梯度并调整学习率,同时通过通信协议同步全局参数,这一策略既保留了自适应学习率调度的优势,又通过并行计算显著提高了效率,模型训练时间缩短至数天,同时预测精度提升了15%。
安全与隐私:学习率调度的“隐形约束”
在工业数字孪生平台的实施中,安全与隐私是常被忽视但至关重要的因素,在2026年,随着工业互联网的普及,数字孪生模型需要处理大量敏感数据,包括设备参数、生产记录、用户信息等,这些数据一旦泄露,可能引发严重的安全风险或法律纠纷,学习率调度算法不仅需要优化模型性能,还需要考虑数据安全和隐私保护。 2026年托育服务与互联网医疗热度不断攀升,技术创新带来新突破
安全与隐私对学习率调度的影响主要体现在数据访问和模型更新上,在多租户数字孪生平台中,不同用户的数据需要隔离存储和处理,学习率调度算法必须确保模型更新不会泄露其他用户的信息,2026年,欧洲某能源公司在部署智慧电网数字孪生平台时,就遇到了这一问题,该平台需要整合来自数千个家庭和企业的用电数据,初始模型采用集中式学习率调度,结果发现:在模型更新过程中,部分用户的用电模式被其他用户“反向推断”出来,引发隐私担忧。
该公司最终采用“联邦 健身教练与压力缓解热度持续攀升,相关技术取得新突破