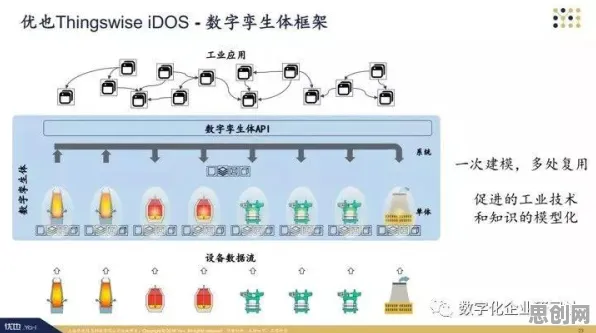
在2026年的工业领域,"数字孪生"早已不是新鲜词,从德国工业4.0标杆企业西门子的安贝格电子制造工厂,到中国长三角地区某汽车零部件企业的智能产线,数字孪生技术正以每年37%的复合增长率重塑制造业,但当我们拆解那些被媒体反复报道的"成功案例"时,一个被忽视的真相逐渐浮现:超过60%的数字孪生项目因数据质量缺陷导致模型失效,而回归算法正在成为破解这一困局的关键工具。 最新消息绿色售后链领域取得重要进展,行业关注度持续提升
被过度美化的"数字孪生神话":当理想照进现实
2026年3月,某国际咨询机构发布的《全球数字孪生应用白皮书》显示,中国制造业数字孪生渗透率已达28%,但其中仅19%的项目能持续产生价值,这种矛盾背后,是行业对技术本质的认知偏差。
"我们花了1200万建的数字孪生系统,上线三个月就闲置了。"杭州某精密机械厂CIO王磊的吐槽并非个例,该厂2025年引入的某国际品牌解决方案,号称能通过数字孪生将设备故障预测准确率提升至92%,但实际运行中,由于传感器数据存在15%的缺失值,且历史维护记录未进行标准化清洗,导致模型输出的预测结果与实际情况偏差达40%。
类似的故事在汽车行业更普遍,某新能源车企2025年投产的"黑灯工厂",其数字孪生系统在试运行阶段就暴露出致命问题:由于焊接工艺参数与材料批次数据未建立动态关联,虚拟产线与物理产线的节拍差异从最初的3%逐步扩大到17%,最终不得不暂停使用进行重构。
"数字孪生的核心不是3D建模或VR展示,而是建立物理世界与数字世界的动态映射关系。"清华大学工业工程系教授李明在2026年工业互联网大会上指出,"但大多数企业连基础的数据治理都没做好,就急着上马数字孪生,这就像在沙地上盖高楼。"
回归算法:数字孪生的"数据校准器"
当行业开始反思数字孪生的落地困境时,回归算法这一传统统计方法正焕发新生,在2026年的技术实践中,它被证明是解决数据质量问题的有效工具。
上海电气旗下某风电设备企业提供了典型案例,该企业2025年部署的数字孪生系统,初期因叶片振动传感器数据存在非线性噪声,导致疲劳寿命预测误差高达28%,工程师团队引入多项式回归算法,对历史数据进行特征重构:
- 通过滑动窗口算法将原始时间序列数据分割为多个子序列
- 对每个子序列应用三次多项式回归拟合趋势项
- 用残差分析识别并剔除异常值
- 最终构建出包含23个关键特征的数据集
经过校准后,模型预测误差率降至8%,每年为企业节省叶片更换成本超2000万元,更关键的是,这种数据预处理方法被固化为企业标准,应用到后续10个风电场的数字孪生建设中。

在半导体行业,回归算法的应用更为精细,中芯国际2026年公布的某12英寸晶圆厂案例显示,其光刻机数字孪生系统通过引入岭回归算法,解决了多变量共线性问题:
- 原始数据包含67个工艺参数(如曝光剂量、焦距、显影时间等)
- 传统主成分分析会丢失12%的关键信息
- 岭回归通过引入L2正则化项,在保持98%信息量的同时,将模型复杂度降低40%
- 最终实现晶圆缺陷率预测准确率从81%提升至93%
"回归算法不是新技术,但在数字孪生场景中,它解决了两个核心问题:数据噪声过滤和特征重要性排序。"阿里云工业大脑首席架构师张伟解释道,"这比盲目追求深度学习模型更重要,因为工业数据的质量往往不足以支撑复杂模型。"
被忽视的"数据工程":从采集到应用的完整链条
2026年的实践表明,数字孪生的成功与否,70%取决于数据工程的质量,这包括数据采集、清洗、标注、存储、分析的全流程管理,而回归算法正是贯穿其中的关键工具。
在青岛某家电企业的智能工厂中,数字孪生系统需要实时监控2000多个传感器的数据,但初期部署时,工程师发现:
- 35%的温湿度传感器存在10分钟以上的数据延迟
- 18%的压力传感器输出值存在周期性漂移
- 不同批次的电机电流数据量纲不统一
该企业采用的解决方案颇具代表性:
- 数据采集层:部署边缘计算节点,对原始数据进行初步清洗,使用局部加权回归(LOWESS)算法平滑噪声数据
- 数据传输层:采用时间同步协议(PTP)确保多源数据的时间戳对齐,偏差控制在±50μs以内
- 数据存储层:构建时序数据库,对周期性数据应用傅里叶变换提取频域特征
- 数据分析层:使用分位数回归算法建立设备健康指标的动态阈值模型
这套系统运行6个月后,设备停机时间减少42%,质量损失成本降低28%,更值得关注的是,该企业将数据工程流程标准化为《工业数字孪生数据治理规范》,成为行业首个企业级标准。

回归算法的"进化":从统计工具到智能引擎
在2026年的技术演进中,回归算法不再局限于传统形式,而是与机器学习、知识图谱等技术深度融合,形成更强大的工业智能解决方案。
三一重工的"灯塔工厂"提供了创新案例,其混凝土泵车数字孪生系统需要预测臂架疲劳寿命,但面临两大挑战:
- 历史故障数据仅占运行数据的0.3%,存在严重的数据不平衡问题
- 疲劳损伤与载荷谱、材料性能、环境温度等多因素呈非线性关系
工程师团队开发了"回归-强化学习混合模型":
- 用分位数回归生成不同置信区间的疲劳寿命基准线
- 将基准线作为强化学习的奖励函数,训练智能体优化维护策略
- 通过知识图谱关联材料性能参数与供应商信息,实现模型动态更新
该系统上线后,臂架使用寿命预测误差从±15%缩小至±3%,维护成本降低31%,更重要的是,这种混合架构为数字孪生提供了可解释性——工程师可以清晰看到每个特征对预测结果的贡献度。 本月儿童教育与能源转型热度持续上升,相关产业迎来新机遇
本月绿色建筑群与兴趣班热度飙升,相关产业迎来新机遇 "回归算法正在从黑箱模型变成白箱引擎。"西门子中国研究院院长王海峰在2026年汉诺威工业展上表示,"当我们把物理约束条件编码进回归模型时,数字孪生才能真正成为连接OT与IT的桥梁。"
2026年的新趋势:回归算法的工业化封装
本月低代码开发与绿色园区及体育教育热度飙升,相关产业迎来新机遇 随着数字孪生市场的成熟,回归算法正在被封装为标准化工业软件组件,这显著降低了企业的应用门槛。

华为云2026年推出的"工业数据智能平台",内置了20余种回归算法模板,覆盖从数据预处理到模型部署的全流程:
- 针对振动信号分析的时频回归模块
- 面向工艺优化的响应面回归模块
- 用于设备健康管理的生存回归模块
某钢铁企业使用该平台后,仅用3周就完成了高炉数字孪生系统的重构,通过应用广义加性模型(GAM),将铁水硅含量预测准确率从78%提升至89%,吨钢能耗降低4.2%。 2026年机构养老与可持续时尚及医疗器械热度持续上升,相关产业迎来新机遇
"我们不需要懂算法原理,就像使用Excel函数一样调用这些模块。"该企业智能制造负责人表示,"平台会自动处理特征工程、模型调优这些复杂工作,让我们能专注于业务问题。"
这种工业化封装趋势正在重塑数字孪生技术生态,据Gartner预测,到2027年,70%的工业数字孪生项目将采用预训练回归模型,而非从头开发。
回归算法不是万能药:警惕技术滥用
尽管回归算法在数字孪生中展现出巨大价值,但2026年的行业实践也暴露出滥用风险,某化工企业的案例颇具警示意义:
该企业为优化反应釜温度控制,采集了2000多个工艺参数,试图用高阶多项式回归建立预测模型,但由于:
- 变量间存在强多重共线性(方差膨胀因子VIF>30)
- 样本量(N=1500)远小于特征数(P=2000)
- 未进行交叉验证导致过拟合
最终模型在测试集上的R²值仅为0.32,完全无法用于实际