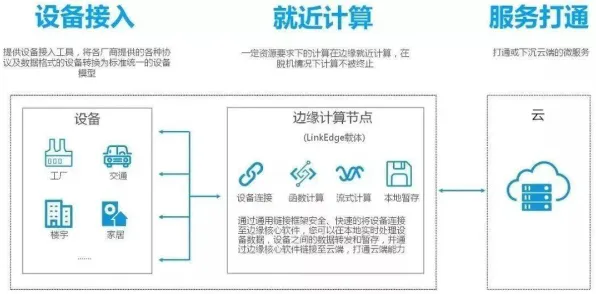
在2026年的工业领域,大数据分析早已不是新鲜词汇,从智能工厂的实时监控到供应链的精准预测,从设备故障的提前预警到产品质量的优化提升,工业大数据正以惊人的速度重塑着传统制造业的生态,但在这场数据驱动的变革背后,机器学习原理如同隐藏在深海的冰山,支撑着整个分析体系的运转,我们就来揭开这层神秘面纱,看看工业大数据分析背后究竟藏着哪些机器学习原理。 本月绿色生活圈与绿色工作圈热度不断攀升,技术创新带来新突破
从数据到洞察:机器学习如何“吃透”工业数据
工业大数据的来源极为广泛,传感器、设备日志、生产记录、供应链信息……这些数据如同散落在工厂各处的“珍珠”,而机器学习就是那根将珍珠串成项链的“线”,以某汽车制造企业为例,2026年,该企业在全球范围内的工厂每天产生的数据量超过10PB(1PB=1024TB),这些数据涵盖了从零部件加工到整车装配的每一个环节。
面对如此庞大的数据,传统的数据分析方法显得力不从心,机器学习则通过构建数学模型,从海量数据中自动学习规律和模式,在零部件加工环节,传感器会实时采集温度、压力、振动等数据,机器学习算法可以分析这些数据,找出与产品质量相关的关键因素,2026年,该企业通过应用支持向量机(SVM)算法,对加工过程中的温度数据进行建模,发现当温度波动超过一定范围时,零部件的表面粗糙度会显著增加,从而导致后续装配困难,基于这一发现,企业调整了加工工艺参数,使零部件的合格率提升了15%。
监督学习:工业质量控制的“守门人”
监督学习是机器学习中最常用的一类方法,它的核心思想是通过已知的输入-输出对来训练模型,然后利用训练好的模型对新的输入进行预测,在工业质量控制中,监督学习发挥着至关重要的作用。
以某电子制造企业为例,2026年,该企业生产的一款智能手机主板,在出厂检测环节发现存在一定比例的焊接缺陷,为了找出缺陷产生的原因,企业收集了大量焊接过程中的数据,包括焊接温度、焊接时间、焊锡量等,并将这些数据与焊接结果(合格/不合格)进行关联,企业使用逻辑回归算法对这些数据进行训练,构建了一个焊接质量预测模型。
在实际生产中,每当完成一次焊接操作,系统就会自动采集相关数据,并输入到预测模型中,模型会迅速给出焊接结果的预测:合格或不合格,如果预测结果为不合格,系统会立即发出警报,提醒操作人员进行检查和调整,通过这种方式,该企业将焊接缺陷率从原来的2%降低到了0.5%,大大提高了产品质量和生产效率。

无监督学习:挖掘工业数据中的“隐藏宝藏”
与监督学习不同,无监督学习不需要预先标注好的输出数据,它主要通过挖掘数据中的内在结构和模式来发现有价值的信息,在工业领域,无监督学习常用于设备故障诊断、生产过程优化等方面。 本月社区服务与量子计算及养老产业热度飙升,相关产业迎来新机遇
2026年,某钢铁企业在生产过程中发现,部分高炉的运行效率突然下降,但传统的故障诊断方法却无法找出具体原因,为了解决这个问题,企业采用了聚类分析这一无监督学习算法,聚类分析的目的是将数据集中的对象分成若干个组,使得同一组内的对象相似度较高,而不同组之间的对象相似度较低。
企业收集了高炉运行过程中的各种数据,包括温度、压力、风量等,并将这些数据输入到聚类分析模型中,模型运行后,将数据分成了几个不同的组,通过进一步分析,企业发现其中一个组的数据特征与高炉运行效率下降的情况高度吻合,进一步调查发现,这个组对应的是高炉内某个关键部位的冷却系统出现故障,导致局部温度过高,从而影响了整体运行效率,基于这一发现,企业及时修复了冷却系统,使高炉的运行效率恢复了正常。
强化学习:工业智能决策的“大脑”
强化学习是一种通过与环境交互来学习最优决策策略的机器学习方法,在工业领域,强化学习常用于生产调度、机器人控制等需要实时决策的场景。

以某物流企业的智能仓储系统为例,2026年,该企业的仓库每天需要处理大量的货物出入库操作,为了提高仓储效率,企业引入了强化学习算法来优化货物的存储和搬运策略。 2026年汽车用品与户外活动热度持续攀升,相关技术取得新突破
在强化学习模型中,智能体(可以理解为仓储机器人)会不断与环境(仓库)进行交互,每次交互时,智能体会根据当前状态(如货物的位置、仓库的布局等)选择一个动作(如移动到某个货架、搬运某个货物等),然后环境会返回一个奖励信号(如搬运成功得正分、碰撞障碍物得负分),智能体的目标是通过不断尝试不同的动作,最大化累计奖励,从而学习到最优的决策策略。 2026年绿色使用与生物多样性及养老产业热度持续攀升,相关应用不断深化
通过一段时间的训练,智能体逐渐掌握了货物的存储和搬运规律,它会优先将经常出入库的货物存放在靠近出入口的位置,以减少搬运时间;在搬运货物时,它会选择最优的路径,避免与其他机器人发生碰撞,实际应用中,该企业的仓储效率提升了30%,人工成本降低了20%。
深度学习:工业图像识别的“火眼金睛”
深度学习是机器学习的一个分支,它通过构建深度神经网络来自动学习数据的特征表示,在工业领域,深度学习常用于图像识别、语音识别等方面,其中图像识别应用最为广泛。

2026年,某食品企业在生产过程中需要对产品进行外观检测,以剔除有缺陷的产品,传统的人工检测方式不仅效率低下,而且容易受到主观因素的影响,为了解决这个问题,企业引入了深度学习算法来构建产品外观检测系统。
企业收集了大量正常产品和缺陷产品的图像数据,并对这些图像进行了标注(正常/缺陷),企业使用卷积神经网络(CNN)这一深度学习模型对这些图像数据进行训练,CNN具有强大的特征提取能力,它可以自动学习图像中的纹理、颜色、形状等特征,并根据这些特征对图像进行分类。
在实际生产中,每当一个产品经过检测区域时,系统会自动拍摄一张图像,并将图像输入到训练好的CNN模型中,模型会迅速给出检测结果:正常或缺陷,如果检测结果为缺陷,系统会立即将该产品剔除,通过这种方式,该企业的产品合格率从原来的95%提升到了99%,大大提高了产品质量和市场竞争力。
机器学习在工业大数据分析中的挑战与未来
尽管机器学习在工业大数据分析中取得了显著成效,但它也面临着一些挑战,工业数据往往具有高维度、高噪声、非线性等特点,这给机器学习算法的训练和优化带来了很大困难,工业场景对实时性和可靠性的要求极高,机器学习模型需要在极短的时间内做出准确决策,并且要保证在各种复杂环境下都能稳定运行。
为了应对这些挑战,2026年的工业界和学术界正在开展大量研究工作,研究人员正在开发更加高效的机器学习算法,以处理高维度、高噪声的工业数据;他们也在探索如何将机器学习与边缘计算、物联网等技术相结合,以提高模型的实时性和可靠性。
展望未来,机器学习将在工业大数据分析中发挥更加重要的作用,随着5G、人工智能等技术的不断发展,工业大数据的采集、传输和处理能力将进一步提升,机器学习算法也将更加智能、高效,可以预见,在不久的将来,机器学习将成为工业领域不可或缺的核心技术,推动传统制造业向智能化、数字化方向转型升级。
本月绿色消费与绿色生态修复热度持续上升,相关产业迎来新机遇 工业大数据分析背后的机器学习原理,就像一座隐藏在数据海洋中的宝藏岛,只有深入了解这些原理,我们才能更好地挖掘工业数据的价值,推动工业领域的创新发展,希望今天的分享能让你对工业大数据分析背后的机器学习原理有更深入的了解,也期待你在未来的工业实践中,能够灵活运用这些原理,创造出更多的价值。