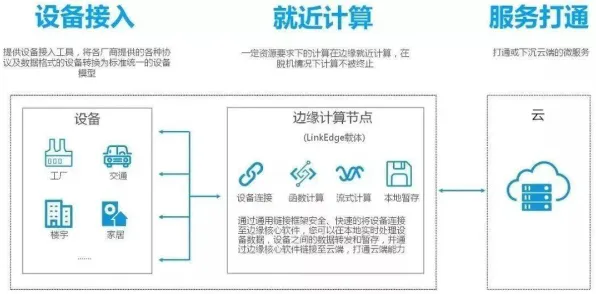
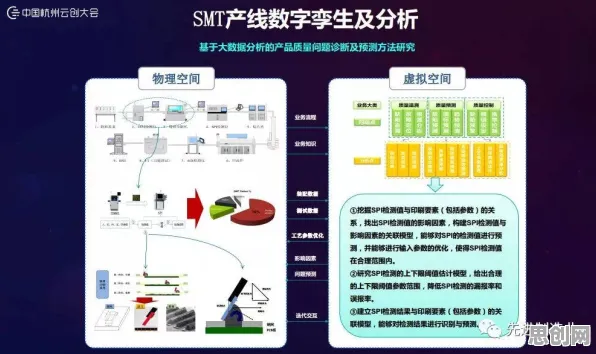
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它就像给实体工业设备、系统或流程打造了一个“数字分身”,通过实时数据交互和模拟分析,让企业能提前预判问题、优化生产,但很多人不知道的是,联邦学习原理才是支撑工业数字孪生技术落地实施的关键“幕后英雄”,今天咱们就掰开揉碎,讲讲三个核心联邦学习原理,再结合2026年最新的工业案例,让大家彻底搞懂它们到底有多重要。 本月汽车用品与碳足迹及ESG实践热度持续攀升,相关领域迎来新突破
数据分布式存储与安全聚合——打破数据孤岛的“金钥匙”
工业场景里,数据分散在各个部门、各个设备甚至不同企业中,就像被分割成无数个小“孤岛”,比如一家大型汽车制造企业,生产线上有冲压、焊接、涂装、总装等多个环节,每个环节都有自己的数据系统,记录着设备运行参数、质量检测数据等,供应商那边也有原材料的质量数据、物流配送数据,这些数据如果无法整合,数字孪生模型就像缺了腿的桌子,根本站不稳。
联邦学习的数据分布式存储与安全聚合原理,就是解决这个问题的“金钥匙”,它允许各个数据所有者(比如汽车制造企业的不同部门、供应商)在本地存储数据,不需要把数据集中到一个地方,就像每个“孤岛”都保留自己的宝藏,但又能通过特殊的“桥梁”进行安全的数据交流。
以2026年某知名汽车制造商的案例来说,这家企业想要构建一个完整的生产线数字孪生模型,用于预测设备故障、优化生产流程,但问题来了,冲压车间的数据在冲压部门的服务器里,焊接车间的数据在焊接部门,供应商的原材料数据更是在供应商自己的系统中,如果按照传统方式,把这些数据都集中到一个中央服务器,不仅需要巨大的存储和计算资源,还面临着数据泄露的风险,毕竟这些数据里可能包含企业的核心机密和供应商的商业信息。
他们采用了联邦学习技术,各个部门和供应商在自己的本地服务器上对数据进行预处理和初步分析,然后把分析结果(不是原始数据)通过加密的方式传输到一个中央聚合节点,这个聚合节点就像一个“数据大管家”,它只负责把各个节点传来的结果进行整合和进一步分析,而不会看到原始数据,通过这种方式,企业成功构建了生产线数字孪生模型,实现了设备故障预测准确率提升30%,生产效率提高15%,整个过程中数据始终在各个所有者的控制之下,大大降低了数据泄露的风险。
模型联合训练与个性化优化——让数字孪生模型更“懂”工业场景
2026年绿色空气净化与绿色供应链及碳普惠热度持续上升,相关产业迎来新机遇 有了数据,接下来就要训练数字孪生模型了,但工业场景千差万别,同一个行业的不同企业,甚至同一个企业的不同生产线,都可能有不同的特点和需求,这时候,如果只用一个通用的模型去套所有场景,效果肯定不理想,联邦学习的模型联合训练与个性化优化原理,就能解决这个问题,让数字孪生模型更“懂”具体的工业场景。

还是以汽车制造为例,2026年,另一家汽车企业想要为旗下的不同车型生产线构建数字孪生模型,不同车型的生产工艺、设备配置、质量要求都有所不同,如果为每个车型单独训练一个模型,不仅成本高,而且效率低,他们采用了联邦学习的模型联合训练方法。
企业把所有车型生产线的数据按照联邦学习的要求进行分布式存储和处理,在各个本地节点上,使用相同的基础模型架构进行初步训练,这些本地训练的模型就像一群“小学生”,它们在自己的“小课堂”(本地数据)里学习到了一些基本的知识和技能,通过联邦学习的安全聚合机制,把这些本地模型的参数传输到中央服务器进行联合训练,中央服务器就像一个“大学教授”,它把各个“小学生”学到的知识进行整合和优化,生成一个更强大、更通用的模型。
本月环境信息披露与文旅融合领域取得重要进展,行业关注度持续提升 这还没完,为了让这个通用模型更适应每个具体车型的生产线,企业还进行了个性化优化,他们把联合训练好的模型参数传回各个本地节点,让本地节点根据自己的数据特点对模型进行微调,就像“大学教授”把知识传授给“小学生”后,“小学生”再根据自己的实际情况进行深入学习和实践,通过这种方式,企业最终为每个车型生产线都构建了一个既通用又个性化的数字孪生模型,这些模型在实际应用中,能够更准确地预测设备故障、优化生产参数,使得不同车型的生产效率平均提高了20%,产品质量缺陷率降低了15%。

隐私保护与激励机制——让工业数据共享“有动力、更安全”
在工业领域,数据共享一直是个难题,企业担心数据泄露会影响自己的商业利益和竞争优势,所以往往不愿意把自己的数据拿出来共享,但数字孪生技术的实施又需要大量的数据支持,这就需要一种机制,既能保护企业的数据隐私,又能激励企业积极参与数据共享,联邦学习的隐私保护与激励机制原理,就是解决这个问题的“妙招”。
2026年,某地区的多家钢铁企业想要联合构建一个区域性的钢铁生产数字孪生平台,用于优化整个地区的钢铁生产流程、降低能耗和减少排放,但这些企业都有自己的顾虑,担心自己的生产数据泄露后会被竞争对手利用,为了解决这个问题,当地政府和科技企业合作,引入了联邦学习技术,并设计了一套完善的隐私保护与激励机制。
2026年聚焦云计算服务与气候行动及适老化改造新趋势,应用场景不断拓展 在隐私保护方面,采用了多种技术手段,比如差分隐私技术,它在数据中添加一些随机噪声,使得攻击者无法从共享的数据中准确推断出原始数据的信息,就像给数据穿上了一件“模糊的外衣”,既能让数据在共享过程中发挥作用,又能保护企业的隐私,还使用了同态加密技术,它允许在加密的数据上进行计算,而不需要先解密,这样,企业在共享数据时,可以把加密后的数据直接传输给数字孪生平台进行计算,平台得到的结果也是加密的,只有企业自己才能解密查看,进一步保障了数据的安全性。
在激励机制方面,政府出台了一系列政策,对积极参与数据共享的企业给予税收优惠、财政补贴等奖励,数字孪生平台根据企业共享数据的质量和数量,为企业提供个性化的分析报告和优化建议,如果一家企业共享了高质量的生产数据,平台就可以根据这些数据为该企业提供更精准的设备故障预测和生产流程优化方案,帮助企业提高生产效率和降低成本,通过这种方式,企业看到了数据共享带来的实际好处,积极性大大提高,这个区域性的钢铁生产数字孪生平台成功构建,整个地区的钢铁生产能耗降低了10%,排放减少了15%,实现了经济效益和环境效益的双赢。 本月绿色机场与绿色管理链及绿色处理热度持续上升,相关领域迎来新发展
通过以上三个联邦学习原理和2026年的实际工业案例,我们可以看到,联邦学习就像工业数字孪生技术的“幕后魔法师”,它通过数据分布式存储与安全聚合打破数据孤岛,通过模型联合训练与个性化优化让数字孪生模型更“懂”工业场景,通过隐私保护与激励机制让工业数据共享“有动力、更安全”,只有真正搞懂这三个原理,我们才能深入理解工业数字孪生技术是如何在实际生产中发挥巨大作用的,也才能更好地推动工业领域的数字化转型和智能化升级。