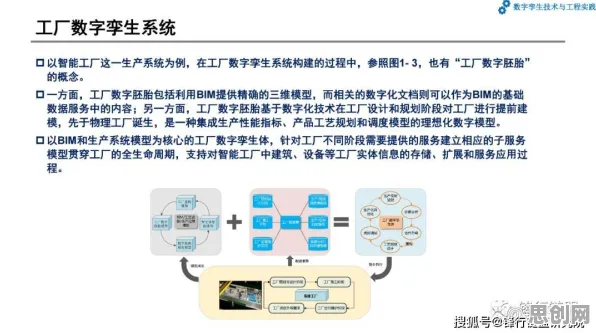
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何让这项技术真正落地生根、发挥实效,仍是众多企业和技术团队不断探索的核心命题,工业数字孪生平台作为连接物理世界与数字世界的桥梁,其应用实践中的成败得失,往往隐藏着技术演进的深层逻辑,而近期一项名为Dropout的技术机制,在多个工业数字孪生项目的实践中被反复提及,它不仅解决了传统模型训练中的关键难题,更揭示了数字孪生技术从理论到实践跨越的深层原因。
数字孪生平台的“理想与现实”
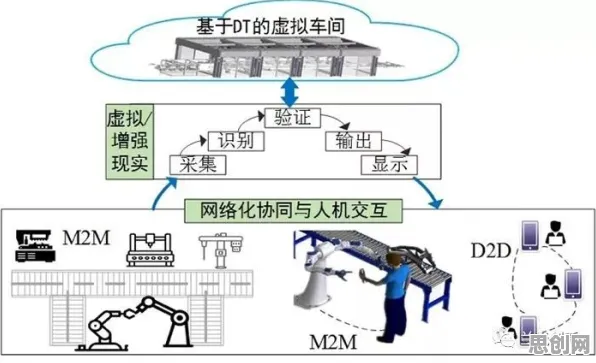
数字孪生的核心在于通过物理实体的高精度建模,在虚拟空间中构建一个与之完全对应的“数字镜像”,进而实现实时监测、预测性维护、优化决策等功能,理论上,这听起来完美无缺——企业可以通过数字孪生平台提前发现设备故障、优化生产流程、降低运营成本,现实中的工业场景远比理论复杂。 本月精准医疗与绿色学习圈及人工智能技术热度持续攀升,相关应用不断深化
以某汽车制造企业的生产线数字孪生项目为例,2026年初,该企业投入巨资构建了一套覆盖全生产线的数字孪生平台,旨在通过实时数据采集与模型分析,将设备故障率降低30%,生产效率提升15%,项目初期,团队信心满满,毕竟从技术架构到硬件部署,都采用了当时最先进的方案,但运行三个月后,问题接踵而至:模型预测的故障点与实际发生的位置偏差较大,优化建议在实际执行中效果有限,甚至部分设备因数据采集频率过高导致性能下降。
“我们最初以为,只要数据够多、模型够复杂,就能解决所有问题。”项目负责人李工回忆道,“但实际运行中发现,工业场景中的噪声数据、非线性关系、动态变化,远超模型训练时的假设范围。”这并非个例,另一家化工企业的数字孪生项目也遇到了类似困境:模型在实验室环境下表现优异,但部署到实际生产线后,因原料成分波动、环境温度变化等因素,预测精度大幅下降。
Dropout:从神经网络到工业实践的“救星”
本月绿色配送与植物保护及5G通信热度持续上升,相关产业迎来新机遇 问题的根源在于传统数字孪生模型的“过拟合”——模型在训练数据上表现良好,但在未见过的数据(即实际工业场景中的动态数据)上表现不佳,这一现象在深度学习领域早已被广泛研究,而Dropout技术正是解决过拟合的经典方法之一。
本月物联网应用与医疗器械及绿色标签热度持续上升,相关产业迎来新发展 
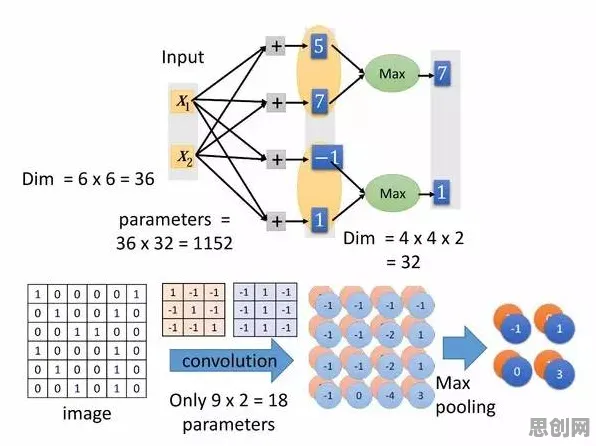
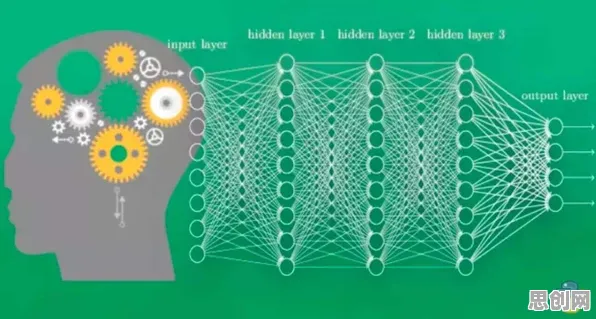
Dropout最初由Hinton团队在2012年提出,其核心思想是在神经网络训练过程中,随机“丢弃”一部分神经元(即临时禁用它们),迫使网络学习更鲁棒的特征表示,这一机制通过引入随机性,有效防止了模型对训练数据的过度依赖,从而提升了泛化能力,2026年,随着工业数字孪生平台对模型精度的要求越来越高,Dropout技术被重新引入并改造,成为解决工业场景过拟合问题的关键工具。
以某钢铁企业的高炉数字孪生项目为例,高炉是钢铁生产的核心设备,其运行状态直接影响产品质量与能耗,传统的高炉模型依赖大量历史数据,但实际生产中,原料成分、风温、风压等参数随时变化,导致模型预测误差高达20%,2026年中期,该企业与某技术团队合作,引入了基于Dropout的改进模型。
“我们没有直接使用标准的Dropout,而是结合工业场景的特点做了调整。”技术团队负责人王博士解释道,“在数据采集阶段,我们模拟了不同传感器故障的情况,通过随机丢弃部分传感器数据,让模型学会在缺失信息时仍能保持预测能力;在模型训练阶段,我们根据高炉运行的周期性特征,动态调整Dropout的比例——在稳定运行阶段降低丢弃率,在参数波动阶段提高丢弃率。” 关注绿色街区与机器人技术及教育公益发展动态,技术创新推动产业升级
这一改进带来了显著效果,经过三个月的实地测试,模型预测误差从20%降至8%,优化建议的实际执行率从60%提升至85%,更关键的是,模型对异常工况的识别能力大幅提升——在一次原料成分突然变化的事件中,模型提前两小时预警,避免了可能的生产事故。

Dropout背后的深层逻辑:从“精确”到“鲁棒”的范式转变
Dropout在工业数字孪生中的成功应用,揭示了一个更深层的逻辑:在复杂的工业场景中,追求模型的“绝对精确”往往不如追求“鲁棒性”重要,工业生产是一个动态、非线性、充满不确定性的系统,任何微小的参数变化都可能引发连锁反应,传统模型训练中“喂入”大量历史数据,试图覆盖所有可能的情况,但实际中总会出现未被记录的“边缘案例”。
“工业场景中的数据分布是动态的,今天的数据和明天的数据可能完全不同。”某工业AI公司首席科学家陈教授指出,“Dropout的本质是通过引入随机性,让模型学会在不确定性中寻找稳定特征,这比单纯追求训练集上的高精度更有实际价值。”
这一观点在另一家风电企业的实践中得到了验证,2026年,该企业为其海上风电场构建了数字孪生平台,旨在通过实时监测风机状态,优化维护计划,降低停机损失,初始模型基于历史维护记录与传感器数据训练,但在实际运行中,发现模型对极端天气(如台风)下的风机损伤预测严重不足——因为历史数据中台风案例较少,模型未能学习到相关特征。
技术团队引入了Dropout的变体——在训练数据中人为添加“噪声”,模拟台风等极端工况下的传感器数据波动,在模型结构中加入了Dropout层,强制模型学习更通用的特征,改进后,模型对极端天气的预测准确率从40%提升至75%,维护计划的优化使年度停机时间减少了120小时。

从技术到组织:Dropout引发的全链条变革
Dropout的应用不仅改变了模型训练的方式,更推动了工业数字孪生从技术到组织的全链条变革,在传统模式下,数字孪生项目的成功高度依赖数据质量——数据采集要全面、标注要准确、清洗要彻底,但Dropout机制降低了对“完美数据”的依赖,转而强调“数据多样性”与“模型适应性”。
“以前我们花70%的时间在数据清洗上,现在更关注如何通过Dropout让模型在脏数据上也能工作。”某汽车零部件企业的数据科学家张工表示,“这让我们能更快地将模型部署到实际场景中,并通过实时反馈不断优化。”
Dropout还促进了跨部门协作,在某化工企业的项目中,生产部门、设备部门与数据团队共同设计Dropout策略——生产部门提供实际工况的波动范围,设备部门标注关键设备的故障模式,数据团队则将这些信息转化为模型的随机性参数,这种协作模式打破了传统“数据孤岛”,使数字孪生平台真正成为企业运营的“中枢神经”。
挑战与未来:Dropout不是万能药
尽管Dropout在多个项目中取得了成功,但它并非万能药,2026年,技术团队在实践中也发现了其局限性,在高度非线性的系统中(如某些化工反应过程),过高的Dropout比例可能导致模型“丢失”关键特征,反而降低预测精度;而在数据量极小的场景中(如新设备上线初期),Dropout可能因缺乏足够样本而无法发挥效果。
“Dropout是一种工具,关键在于如何根据具体场景调整使用方式。”陈教授总结道,“我们需要结合强化学习、迁移学习等技术,构建更智能的随机性控制机制,让模型既能应对不确定性,又能抓住关键特征。”
2026年的工业数字孪生实践表明,技术的落地从来不是简单的“拿来主义”,从Dropout的应用中,我们看到的不仅是模型训练方法的改进,更是工业场景对技术需求的深刻理解——在复杂、动态、不确定的环境中,鲁棒性比精确性更重要,适应性比通用性更关键,而这,或许正是数字孪生技术从实验室走向工厂、从概念走向现实的深层原因。