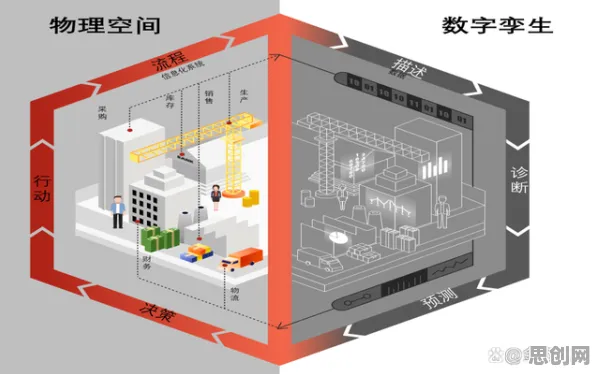
2026年医疗器械与绿色信息网热度持续上升,相关领域迎来新机遇 2026年的工业圈里,数字孪生早已不是个新鲜词,从德国的“工业4.0”到中国的“智能制造2025”,从跨国巨头的智能工厂到中小企业的产线改造,数字孪生技术正以肉眼可见的速度渗透进工业生产的每个环节,但最近半年,行业里的讨论风向变了——过去大家热衷于聊“怎么建数字孪生模型”“怎么用虚拟仿真优化生产”,现在却开始追问:“这个模型为什么给出这样的决策?”“它真的可靠吗?”这种转变背后,是工业场景对数字孪生从“能用”到“可信”的迫切需求,而可解释AI(XAI)的介入,正为这场讨论打开新的视角。
数字孪生的“信任危机”:从一场事故说起
2026年可持续发展与数字经济及循环经济热度持续攀升,相关应用不断深化 2026年3月,江苏某汽车零部件企业的智能工厂发生了一起意外,该企业去年投入千万建设的数字孪生系统,在模拟一条新产线的工艺流程时,给出的设备布局方案与工程师经验严重冲突,系统建议将两台关键机床的间距从常规的1.2米缩短到0.8米,理由是“能减少物料搬运时间,提升整体效率”,工程师团队反复验证后,认为这个间距会导致设备操作空间不足,存在碰撞风险,最终否决了方案,但系统坚持“计算结果无误”,双方僵持不下。
更戏剧性的是,企业为验证系统准确性,按原方案试运行了三天,结果真的发生了设备碰撞事故,导致一台价值200万元的数控机床停机维修,事后复盘发现,数字孪生模型在模拟时忽略了“设备启动时的微小振动”这一变量——这个变量在工程师经验中是常识,但模型因缺乏可解释性,无法说明“为什么忽略了这个变量”,也无法证明“如果考虑这个变量,结果会如何”。
“我们花了大价钱建系统,结果它像个黑盒子,出了问题连‘为什么’都说不清楚。”该企业生产总监在行业论坛上吐槽时,台下不少人点头,这并非个例:据中国工业互联网研究院2026年发布的《工业数字孪生应用白皮书》,在已部署数字孪生的企业中,63%表示“模型决策过程不透明”,41%遇到过“模型结果与实际偏差大但无法定位原因”的情况,数字孪生从“技术热点”变成了“信任痛点”。
可解释AI:给数字孪生装上“透明玻璃”
数字孪生的“黑箱”问题,本质是AI算法的可解释性困境,传统数字孪生模型多基于深度学习、强化学习等复杂算法,这些算法能通过海量数据“学”出决策逻辑,但“怎么学的”“为什么这么决策”,连开发者都说不清楚,这在工业场景中尤其危险——一个错误的决策可能导致设备损坏、生产中断,甚至人员伤亡。
“工业场景对可靠性的要求是‘零容忍’,我们需要的不是‘大概率正确’的模型,而是‘能说清楚为什么正确’的模型。”清华大学工业工程系教授李明在2026年5月的全球工业智能峰会上指出,他所在的团队与某钢铁企业合作,开发了一套基于可解释AI的数字孪生系统,专门用于高炉炼铁工艺优化。 最近智能硬件热度持续攀升,相关领域迎来新突破
高炉炼铁是典型的“黑箱工艺”:炉内温度、压力、成分等参数实时变化,传统控制依赖工程师经验,但经验难以覆盖所有工况,该企业的数字孪生系统原本用深度学习模型预测铁水硅含量(反映炉温的关键指标),但模型给出的预测值与实际值偏差经常超过5%,且无法说明“哪些参数影响了预测结果”。
李明团队引入了“特征归因”技术——一种可解释AI方法,能分析模型决策时对每个输入参数的依赖程度,改造后的系统不仅能给出硅含量预测值,还能生成“决策报告”:当前预测值3.2%,主要受炉顶压力(贡献42%)、风量(贡献28%)、原料硅含量(贡献20%)影响,其中炉顶压力比历史均值高0.5kPa,可能导致预测值偏高0.3%”,工程师看到这份报告后,能快速定位问题:“原来是风量传感器数据异常,导致模型误判。”调整传感器后,预测偏差降至1%以内。
“可解释AI不是要替代工程师,而是给模型和工程师之间建一座‘翻译桥’。”李明说,据该企业统计,改造后的数字孪生系统使高炉燃料比降低1.5%,年节约成本超2000万元,更重要的是,工程师对模型决策的信任度从“勉强接受”提升到“主动依赖”。

从“解释”到“协作”:可解释AI重塑人机关系
可解释AI的价值,不仅在于让模型“说清楚”,更在于让人机从“对抗”走向“协作”,2026年7月,德国西门子在汉诺威工业展上展示了一套“可解释数字孪生”原型系统,用于飞机发动机叶片的制造工艺优化。
叶片是发动机最关键的部件之一,其制造涉及数十道工序,任何微小偏差都可能影响性能,传统工艺优化依赖工程师反复试验,耗时且成本高,西门子的数字孪生系统能模拟不同工艺参数下的叶片变形情况,但早期版本因缺乏可解释性,工程师总怀疑“模型是不是漏掉了什么”。
改造后的系统引入了“反事实解释”技术——当模型给出“参数A调整到X值时,叶片变形量最小”的决策时,它能进一步回答:“如果参数A保持原值,参数B调整到Y值,变形量会如何变化?”这种“假设性分析”让工程师能像做实验一样验证模型建议,甚至发现模型未考虑的变量。
在一次测试中,模型建议将某道工序的切削速度从80m/min提高到100m/min,理由是“能减少加工时间且变形量在允许范围内”,工程师通过反事实解释发现,如果同时将切削深度从0.5mm减少到0.3mm,变形量能进一步降低15%,而模型因未考虑“切削速度-切削深度”的交互作用,忽略了这一优化空间,工程师结合模型建议和自身经验,制定了更优的工艺方案,使单件叶片加工时间缩短20%,合格率提升至99.8%。
“过去是人适应模型,现在是模型适应人。”西门子数字化工业集团CTO汉斯·穆勒在展会上表示,“可解释AI让数字孪生从‘工具’变成‘伙伴’,工程师敢用、会用、爱用模型,这才是工业智能的真正价值。”

挑战与未来:可解释AI的“工业级”难题
尽管可解释AI为数字孪生带来了新可能,但要在工业场景大规模落地,仍面临诸多挑战,首先是“解释成本”问题——工业模型通常涉及海量参数和复杂逻辑,生成的解释报告可能长达数十页,工程师如何快速抓住关键信息?2026年9月,上海交通大学与某半导体企业合作开发了一套“智能解释引擎”,能根据工程师角色(如工艺工程师、设备维护员)自动筛选解释内容,将报告长度压缩80%,同时保留核心决策依据。
“解释标准”缺失——不同行业、不同场景对“可解释”的要求差异巨大,汽车制造可能更关注“为什么预测设备故障”,而化工生产可能更在意“为什么调整某个参数会影响产品质量”,国际标准化组织(ISO)正在牵头制定“工业数字孪生可解释性标准”,预计2027年发布首版草案。
“算力与效率的平衡”——可解释AI通常需要额外的计算资源来生成解释,这在实时性要求高的工业场景(如机器人控制)中可能成为瓶颈,2026年11月,英伟达发布的最新工业AI芯片“OmniVerse X1”,通过硬件加速可解释算法,将解释生成时间从秒级缩短至毫秒级,为实时数字孪生应用铺平了道路。 超级电容与绿色办公热度持续上升,相关产业迎来新机遇
写在最后:当数字孪生“透明”了,工业会怎样?
2026年的工业圈里,一个共识正在形成:数字孪生的未来不属于“最聪明的模型”,而属于“最可信的模型”,可解释AI的介入,正在让数字孪生从“黑箱”变成“玻璃盒”——工程师能看到模型如何思考,能验证模型的每一步决策,甚至能教模型“如何思考得更好”。
这种转变带来的不仅是技术升级,更是工业生产方式的变革,当人机从“对抗”走向“协作”,当经验与数据真正融合,工业生产的效率、质量和灵活性将迎来新的飞跃,或许用不了多久,我们就会看到这样的场景:在某家智能工厂里,工程师和数字孪生系统并肩工作——系统快速模拟千万种方案,工程师用经验筛选最优解,双方不断碰撞、修正,最终共同完成一次完美的生产优化。
这,才是工业数字孪生的真正未来。