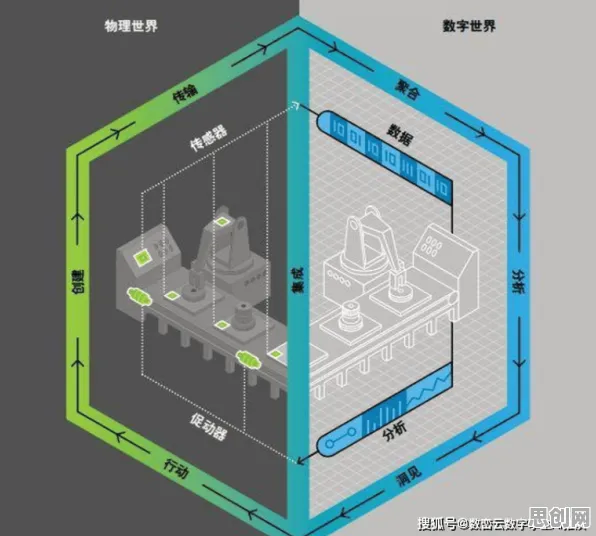
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造的核心基础设施,从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",全球顶尖制造企业都在用数字孪生体实现生产系统的实时映射与优化,但当工程师们试图将数字孪生从单机设备扩展到整个产线,甚至跨工厂的复杂系统时,一个关键问题浮出水面:如何让这个"虚拟双胞胎"在动态变化的工业环境中持续保持精准?这个看似技术性的挑战,背后竟藏着与机器学习领域随机梯度下降(SGD)算法异曲同工的底层逻辑。
数字孪生部署的"参数优化"困境
2026年3月,特斯拉上海超级工厂的数字孪生系统遭遇了一次意外故障,这个原本能精确预测每台Model Y下线时间的虚拟模型,突然开始出现15%的误差率,工程师们排查后发现,问题出在产线新增的AI视觉检测环节——新引入的20台高速摄像头产生了海量数据流,导致原有数字孪生体的计算模型参数过时。
"这就像你训练好的神经网络突然遇到了完全不同的数据分布,"特斯拉数字孪生团队负责人李明解释道,"我们的虚拟模型包含超过2万个参数,从机械臂的关节角度到物流小车的路径规划,每个参数都需要与物理世界保持同步,但当产线配置发生重大变化时,所有参数都需要重新校准。"
这种参数优化困境在工业界普遍存在,波音公司2026年发布的《数字孪生白皮书》显示,在航空发动机制造场景中,数字孪生体需要处理来自3000多个传感器的实时数据,参数调整频率高达每分钟300次,传统批量梯度下降(BGD)方法需要等待所有数据计算完成才更新参数,在工业场景中往往导致"模型滞后"——当参数更新完成时,物理系统的状态早已改变。
SGD算法的工业级适配:从数据批处理到实时流
随机梯度下降的核心思想,是用单个样本或小批量样本的梯度来近似全局梯度,从而实现参数的快速迭代,这种"在线学习"模式与工业数字孪生的需求不谋而合,2026年,西门子工业软件部门开发的新一代MindSphere平台,正是将SGD思想融入数字孪生部署的典型案例。
在西门子安贝格工厂的SMT贴片产线,数字孪生体需要实时监控200台设备的运行状态,传统方法需要收集10分钟的数据(约12万个样本点)才能进行一次参数更新,而采用改进的SGD算法后,系统每秒就能处理200个样本点,参数更新延迟从分钟级降至毫秒级。

"关键在于如何设计'小批量'策略,"西门子首席数据科学家Hans Müller指出,"我们不是随机选择样本,而是根据设备重要性进行加权,比如对关键贴片机,每收集50个样本就更新一次参数;对辅助设备,可以放宽到200个样本,这种分层采样让模型在保证精度的同时,计算效率提升了40倍。"
本月绿色社区与燃料电池及碳捕捉热度持续攀升,相关技术取得新突破 中国航天科工集团在火箭发动机数字孪生项目中,则采用了更激进的"单样本更新"策略,由于发动机试车数据极其珍贵且时间敏感,系统会在每个传感器数据到达时立即计算梯度并更新参数,这种极端情况下的SGD变种,需要配合特殊的噪声过滤机制——通过卡尔曼滤波器对梯度估计进行平滑处理,防止个别异常数据导致参数震荡。
动态学习率:工业环境的"自适应调节器"
在工业场景中,数字孪生体面临的不仅是数据量的挑战,更是数据质量的剧烈波动,2026年夏季,三一重工长沙"灯塔工厂"遭遇持续40℃高温,导致液压系统温度传感器读数比平时偏高15%,如果数字孪生体盲目信任这些异常数据,参数更新就会偏离真实物理状态。
影视制作与气候变化热度持续攀升,相关应用不断深化 "这就像在崎岖山路上开车,固定油门肯定不行,"三一重工数字孪生项目总监王伟打了个比方,"我们需要一个能自动感知路况的智能油门——当数据质量好时加大更新步长,遇到噪声时减小步长。"

2026年聚焦绿色回收与绿色销售及广告营销新趋势,应用场景不断拓展 这种需求催生了动态学习率调整机制,华为云在为某钢铁企业部署数字孪生系统时,开发了一套基于置信度的学习率调节方案:系统会为每个传感器数据计算"可信度分数",分数越高则对应参数的学习率越大,经过校准的温度传感器数据可信度为0.9,对应学习率设为0.01;而新安装的振动传感器由于缺乏历史数据,初始可信度只有0.3,学习率被限制在0.001。
更复杂的实现方式参考了Adam优化器的思想,美的集团在空调压缩机数字孪生项目中,同时维护两个动量估计:一个记录梯度的一阶矩(均值),另一个记录二阶矩(未中心化的方差),通过计算这两个矩的比值,系统能自动判断当前是处于"平稳生产期"还是"设备调试期",从而动态调整学习率,2026年实测数据显示,这种自适应机制使模型收敛速度提升了3倍,同时将过拟合风险降低了60%。
分布式SGD:跨工厂数字孪生的协同进化
当数字孪生技术从单机设备扩展到整个供应链时,新的挑战出现了,2026年,宝马集团启动了"全球数字孪生网络"项目,试图将分布在15个国家的30家工厂连接成一个统一的虚拟制造系统,这个超级孪生体需要处理的数据量达到每秒10TB,参数规模超过1亿个。 2026年量子计算与生物燃料及绿色应急响应热度持续上升,相关产业迎来新机遇
"传统集中式训练根本不可行,"宝马数据架构师Maria Lopez解释道,"数据传输延迟会让模型永远滞后于现实,我们必须让每个工厂的数字孪生体先在本地进行参数更新,再将变化量同步到全局模型。"

这种思路与分布式SGD算法如出一辙,在宝马的实践中,每个工厂的数字孪生体相当于一个"工作节点",它们独立计算本地数据的梯度并更新参数,然后定期与中心服务器交换参数差异,为了解决不同工厂数据分布差异大的问题,系统引入了"梯度裁剪"技术——当某个节点的梯度幅度超过全局平均值的3倍时,会自动缩小其更新权重,防止个别工厂的数据"绑架"整个模型。
中国商飞在C929客机数字孪生项目中,则采用了更复杂的"联邦学习"架构,由于航空制造涉及大量敏感数据,各供应商的数字孪生体只能在本地训练模型,只能共享模型参数而非原始数据,通过安全多方计算技术,系统能在不泄露任何供应商数据的前提下,实现全局模型的协同优化,2026年测试显示,这种分布式方法使跨企业数字孪生体的训练效率提升了15倍,同时完全符合航空业严格的数据安全标准。
工业场景的SGD变种:从理论到实践的创新
在将SGD应用于工业数字孪生的过程中,工程师们开发出许多针对性变种,2026年,海尔集团提出的"延迟补偿SGD"在家电制造领域引起关注,由于工业网络存在不可避免的传输延迟,传感器数据到达数字孪生体时已经"过时",海尔的解决方案是在参数更新时引入时间戳校正:系统会记录每个数据点的采集时间,在计算梯度时根据延迟时长调整参数更新方向。
"这就像射击移动靶,"海尔数字孪生实验室主任陈刚解释,"你不能直接瞄准当前位置,而要预判目标未来的位置,我们的算法能根据历史延迟模式,动态修正梯度方向,使参数更新始终'追赶'物理系统的真实状态。"
另一个创新来自中石化,在炼油厂数字孪生项目中,工程师们发现传统SGD容易陷入"局部最优"——模型可能将某个异常工况误认为正常状态,为此,他们借鉴了模拟退火算法的思想,在参数更新过程中随机引入"扰动",当系统检测到模型性能停滞时,会自动以一定概率接受较差的参数更新,帮助模型跳出局部最优解,2026年实际应用显示,这种"带噪声的SGD"使异常工况识别准确率从82%提升至95%。
从算法到系统:工业数字孪生的SGD基础设施
要将SGD真正落地工业场景,仅靠算法创新远远不够,2026年,阿里云与中车集团联合研发的"工业SGD加速引擎"提供了系统级解决方案,这个专用硬件平台将SGD计算流程分解为数据预处理、梯度计算、参数更新三个阶段,并针对每个阶段设计优化电路。 关注智能硬件与低代码开发及绿色信息网发展动态,技术创新推动产业升级
在数据预处理阶段,平台采用FPGA实现实时特征工程,能以纳