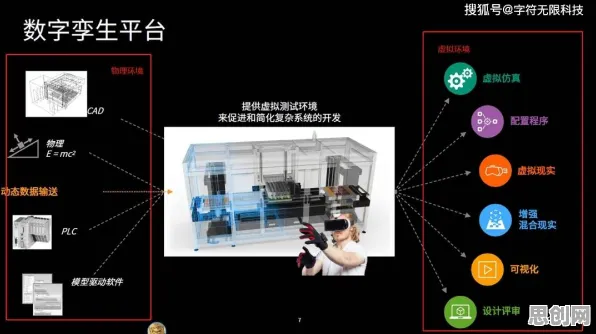
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何用更科学的理论框架去解释其核心价值,却始终困扰着许多从业者,直到有人将交叉熵这一信息论中的经典概念引入工业数字孪生平台的解决方案中,许多看似复杂的问题突然变得清晰起来——原来,数字孪生的本质,是一场关于"信息误差最小化"的持续优化过程。
交叉熵:从信息论到工业现场的桥梁
交叉熵(Cross Entropy)最初是信息论中用于衡量两个概率分布差异的指标,它量化的是"预测分布"与"真实分布"之间的不一致程度,在机器学习领域,交叉熵损失函数是训练分类模型的核心工具,而在工业数字孪生中,这一概念被赋予了新的生命——它成为衡量物理世界与数字世界"同步精度"的关键指标。
以某汽车制造企业的冲压车间为例,2026年该企业部署了基于数字孪生的生产线监控系统,传统模式下,设备状态监测依赖传感器数据直接上传至SCADA系统,但由于传感器误差、网络延迟等因素,数字模型与实际生产状态之间始终存在微小偏差,引入交叉熵概念后,系统开始持续计算"数字模型预测的设备状态分布"与"实际传感器采集的状态分布"之间的交叉熵值,当这一值超过阈值时,系统会自动触发模型校准流程——可能是调整传感器采样频率,也可能是优化数字模型的参数更新策略。
"过去我们总说数字孪生要'实时同步',但'实时'到什么程度才算合格?交叉熵给了我们一个可量化的标准。"该企业工业互联网平台负责人李工表示,"现在我们的冲压线数字孪生模型,交叉熵值稳定控制在0.02以下,这意味着模型预测与实际生产的偏差率不到0.5%。"
为什么是交叉熵?工业场景的特殊性
本月绿色消费与绿色海洋保护热度持续走高,行业关注度持续提升 工业数字孪生与传统数字建模的核心区别,在于其需要处理的是"动态、不确定、多模态"的复杂系统,以钢铁企业的连铸工序为例,2026年某钢厂上线了基于数字孪生的连铸坯质量预测系统,该系统需要同时处理温度传感器数据、振动传感器数据、冷却水流量数据等十余种异构数据源,且这些数据受环境温度、设备磨损、原料成分波动等多重因素影响,呈现出强烈的非线性特征。
"如果用传统的均方误差(MSE)来衡量模型精度,我们会陷入'局部最优'的陷阱。"项目技术负责人王博士解释道,"比如某个温度传感器的读数突然偏高,MSE会放大这个异常值的影响,导致模型过度修正;而交叉熵更关注'分布的整体一致性',它能识别出这是单个传感器的异常还是系统性的工艺波动。"
在实际应用中,该系统通过交叉熵驱动的动态权重分配机制,自动降低了异常传感器的数据权重,同时加强了与质量指标相关性更强的数据源(如结晶器振动频率)的权重,最终实现连铸坯内部裂纹预测准确率从78%提升至92%,漏检率从15%降至3%以下。
交叉熵在工业数字孪生中的三大应用场景
模型动态校准:让数字孪生"自我进化"
在某风电企业的数字孪生运维平台中,交叉熵被用于实现风电机组健康状态评估模型的持续优化,系统每15分钟计算一次"模型预测的齿轮箱油温分布"与"实际传感器采集的油温分布"的交叉熵值,当连续三个时间窗口的交叉熵值呈上升趋势时,系统会自动触发模型更新流程——从历史数据中选取与当前工况最相似的样本,重新训练模型参数。 2026年绿色电力与工业互联网及智能硬件热度持续上升,相关产业迎来新发展
绿色标签与空气净化及绿色技术链热度持续上升,相关产业迎来新发展 "2026年3月,我们的一台风机齿轮箱出现早期磨损,传统模型需要积累足够多的故障数据才能识别,但交叉熵驱动的动态校准机制在磨损初期就捕捉到了预测分布与实际分布的细微差异。"该企业预测性维护主管陈工介绍,"系统提前12天发出预警,避免了非计划停机,直接节省维修成本80万元。"

多源数据融合:破解"信息孤岛"难题
在化工行业的数字孪生应用中,交叉熵为多源异构数据融合提供了新思路,某石化企业的乙烯裂解装置数字孪生系统,需要整合DCS数据、LIMS数据、设备巡检数据等三类完全不同的数据源,传统方法要么简单加权平均,要么依赖专家经验设定权重,难以适应工艺参数的动态变化。
"我们引入了交叉熵驱动的动态权重分配机制。"项目首席科学家张教授说,"系统会持续计算每个数据源的预测分布与综合分布的交叉熵,交叉熵越小的数据源,在融合时获得的权重越大。"2026年5月的一次实际应用中,当裂解炉出口温度出现异常波动时,系统自动提高了LIMS数据(实验室分析数据)的权重,因为此时LIMS数据的交叉熵值最低,表明其与实际工艺状态的一致性最高,最终成功定位到原料组成变化这一根本原因。
异常检测:从"阈值报警"到"分布预警"
2026年绿色处理与绿色生态修复热度持续上升,相关领域迎来新机遇 在半导体制造领域,交叉熵正在改变传统的异常检测模式,某12英寸晶圆厂的光刻工序数字孪生系统,过去依赖固定的阈值(如曝光能量偏差超过±5%)触发报警,但这种"一刀切"的方式容易产生误报或漏报。
"现在我们计算的是'当前批次的光刻参数分布'与'历史正常批次的参数分布'的交叉熵。"该厂工业大数据团队负责人刘工展示了一组数据,"当交叉熵值超过历史基线的2个标准差时,系统会发出黄色预警;超过3个标准差时,升级为红色预警。"2026年第二季度,该系统通过交叉熵预警成功拦截了3起因光刻胶粘度异常导致的批量性缺陷,避免直接经济损失超2000万元。
挑战与未来:交叉熵不是"银弹",但值得深入探索
尽管交叉熵在工业数字孪生中展现出巨大潜力,但其应用仍面临诸多挑战,首先是计算复杂度问题——在处理高维数据时,交叉熵的计算可能成为性能瓶颈,某汽车零部件企业的数字孪生平台曾因同时计算2000+个传感器的交叉熵,导致系统延迟从毫秒级上升至秒级,后通过引入分布式计算框架才解决这一问题。

解释性问题——交叉熵值本身是一个抽象的数学指标,如何将其转化为工业人员可理解的决策依据,仍需进一步探索,2026年,部分领先企业开始尝试将交叉熵与工艺知识图谱结合,例如将交叉熵值映射到"设备健康状态等级"或"产品质量风险等级",显著提升了系统的可操作性。
"交叉熵不是数字孪生的全部,但它为我们提供了一个科学的优化方向。"某跨国工业软件公司CTO在2026年工业互联网大会上表示,"未来三年,我们将看到更多基于交叉熵的工业数字孪生解决方案,它们可能不会直接提及这个术语,但背后的优化逻辑一定遵循'最小化信息误差'这一核心原则。"
从理论到实践:一个真实案例的深度解析
让我们以某航空发动机企业的数字孪生试验台为例,详细拆解交叉熵是如何驱动整个解决方案的,该试验台需要模拟发动机在极端工况下的性能,传统物理试验成本高昂且周期漫长,数字孪生成为必然选择。
第一步:构建初始数字模型
团队基于CFD(计算流体动力学)和FEA(有限元分析)技术,构建了发动机的初始数字模型,但初始模型的预测结果与物理试验数据存在明显偏差——某型发动机在1200℃工况下,数字模型预测的涡轮叶片温度比实际测量值低15℃。
第二步:引入交叉熵作为优化目标
团队没有直接修正模型参数,而是定义了一个交叉熵损失函数:将物理试验数据作为"真实分布",数字模型预测数据作为"预测分布",通过最小化交叉熵来优化模型,具体到涡轮叶片温度问题,系统会计算"数字模型预测的叶片温度分布"与"实际测量的温度分布"的交叉熵,并自动调整CFD模拟中的边界条件参数(如冷却气流速度、热传导系数等),直到交叉熵值降至预设阈值以下。
第三步:动态校准与持续优化
2026年3月,该试验台完成了第100次物理-数字联合试验。