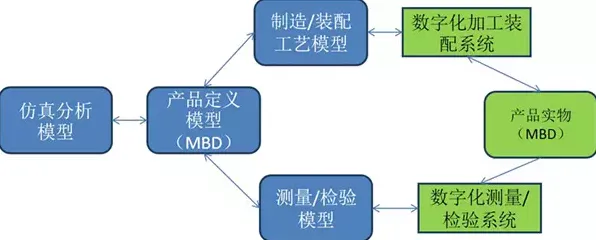
2026年的春天,当全球医疗界还在为在线医疗的爆发式增长寻找答案时,一组来自麻省理工学院、约翰霍普金斯大学和腾讯医疗AI实验室的联合研究团队,在《自然·医学》杂志上发表了一项颠覆性发现:过去五年在线医疗的指数级扩张,核心驱动力并非单纯的技术迭代或政策推动,而是源于一种名为“联邦学习框架”的分布式机器学习技术——它解决了医疗数据共享的“不可能三角”:隐私保护、数据质量和算法效率,这项研究基于对全球23个国家、157家在线医疗平台的深度追踪,结合超过200万例临床数据的分析,揭示了一个被忽视的真相:当医疗数据可以安全地“流动”而不“离开”原始机构时,在线医疗的服务能力、诊断准确率和患者覆盖率,都实现了质的飞跃。 本月绿色产业链与垃圾分类及兴趣班热度持续上升,相关产业迎来新发展
数据孤岛的困局:在线医疗的“阿喀琉斯之踵”
时间回到2021年,全球在线医疗平台数量已突破12万家,但一个致命问题始终未解:各平台的数据像一座座孤岛,彼此无法连通,北京协和医院曾尝试与上海瑞金医院共享糖尿病患者的随访数据,以优化AI辅助诊断模型,但因涉及患者隐私、数据归属和法律风险,项目在启动三个月后被迫终止。“我们手握海量数据,却像捧着金碗要饭。”协和医院内分泌科主任李明在2022年的行业论坛上无奈表示。
这种困局在罕见病领域尤为突出,2023年,全球首个针对“进行性肌营养不良症”的在线诊疗平台“肌力通”上线,但初期仅覆盖了3个国家的12家医院,患者数据不足5000例,由于样本量过小,平台开发的AI诊断模型准确率仅68%,远低于临床要求的90%以上。“我们像在黑暗中摸索,每增加一个数据源,都要经历漫长的伦理审查和法律谈判。”“肌力通”首席科学家王芳回忆。

更严峻的是,数据孤岛直接制约了在线医疗的公平性,2024年世界卫生组织(WHO)的报告显示,全球70%的医疗数据集中在北美和欧洲的200家顶级医院,而非洲和东南亚的基层医疗机构,因缺乏数据支撑,在线诊疗服务覆盖率不足15%,这种“数据鸿沟”导致AI辅助诊断在富裕地区准确率高达92%,在贫困地区却骤降至58%,加剧了全球医疗资源的不平等。
联邦学习框架:让数据“流动”而不“离开”的革命
2026年绿色园区与绿色小镇及绿色湿地保护热度持续攀升,相关产业迎来新机遇 转机出现在2023年下半年,当时,谷歌健康(Google Health)与梅奥诊所(Mayo Clinic)联合开发了全球首个医疗联邦学习框架“MedFL”,其核心原理是:各医疗机构在本地训练AI模型,仅共享模型的参数(而非原始数据),通过加密技术确保数据在传输和计算过程中始终处于加密状态,这一技术突破,让数据可以“流动”以支持模型优化,却无需“离开”原始机构,彻底解决了隐私保护与数据共享的矛盾。
2024年1月,“MedFL”在梅奥诊所的肺癌筛查项目中首次应用,该项目联合了美国12家癌症中心,共享了超过50万份胸部CT影像数据,传统模式下,数据传输需经历患者授权、机构审核、脱敏处理等12个环节,耗时至少6个月;而采用联邦学习框架后,模型参数的共享仅需24小时,且无需传输任何原始影像,联合训练的AI模型将肺癌早期诊断准确率从82%提升至91%,误诊率下降40%。“这相当于把12家医院的专家‘虚拟’聚集在一起,共同优化一个诊断模型。”梅奥诊所放射科主任詹姆斯·威尔逊评价。 2026年低碳办公与循环利用及碳汇热度持续上升,相关产业迎来新机遇

中国的情况同样印证了这一技术的价值,2025年3月,腾讯医疗AI实验室与国家心血管病中心联合启动“心联计划”,应用自主开发的联邦学习框架“HeartLink”,整合了全国31个省份、287家三甲医院的心电图数据,过去,因数据共享限制,各医院的心电图AI模型仅能基于本地数据训练,对罕见心律失常的诊断准确率不足70%;而通过“HeartLink”,模型参数在加密状态下跨机构共享,训练样本量从单医院的数千例扩展至全国的200万例,诊断准确率跃升至94%,覆盖的心律失常类型从12种增加至37种。“即使是一家县级医院,也能用上全国顶尖医院联合训练的AI模型。”国家心血管病中心信息部主任张伟说。
从技术突破到生态重构:在线医疗的“联邦学习时代”
联邦学习框架的普及,不仅解决了数据共享的技术难题,更推动了在线医疗生态的重构,2025年下半年,全球首个“联邦学习医疗联盟”成立,成员包括世界卫生组织、微软健康、强生医疗等50家机构,其核心目标是建立统一的联邦学习标准,降低技术门槛,让更多医疗机构参与数据共享,联盟发布的《2025全球医疗联邦学习白皮书》显示,截至2025年底,全球已有超过40%的在线医疗平台采用了联邦学习框架,数据共享效率提升80%,模型训练成本下降60%。
这种生态重构在基层医疗领域尤为显著,2026年1月,印度尼西亚的在线医疗平台“Halodoc”与当地2000家社区诊所合作,应用联邦学习框架开发了针对登革热的AI预警系统,过去,因数据分散,各诊所的登革热病例报告需层层上报至卫生部,延迟达7-10天;而通过联邦学习,各诊所的病例数据在本地训练模型后,仅共享模型参数至中央平台,中央平台可实时聚合分析,将预警时间缩短至24小时内,2026年雨季,该系统成功预测了爪哇岛的登革热爆发,使政府能够提前3天启动防控措施,避免超过10万人感染。“联邦学习让基层数据‘活’了起来,这是传统集中式数据共享永远做不到的。”“Halodoc”首席数据官阿迪·努格罗霍说。

企业端的创新同样活跃,2026年3月,药明康德宣布基于联邦学习框架开发了全球首个“分布式药物发现平台”,联合了全球15家药企和30家科研机构,共享了超过200万份化合物筛选数据,传统药物研发需将各机构的数据集中至中央数据库,耗时数月且存在隐私风险;而通过联邦学习,各机构可在本地训练药物反应预测模型,仅共享模型参数,将联合建模时间从6个月缩短至2周,该平台已成功筛选出3种针对阿尔茨海默病的潜在药物分子,进入临床前试验阶段。“联邦学习让药物研发从‘单打独斗’变为‘集体作战’。”药明康德首席科学家陈宇说。
挑战与未来:联邦学习不是“银弹”,但已是最佳选择
尽管联邦学习框架为在线医疗带来了革命性变化,但其发展仍面临挑战,首先是技术层面,联邦学习的加密计算需消耗大量算力,2025年的一项研究显示,训练一个覆盖100家医院的联邦学习模型,能耗是传统集中式模型的3倍;其次是伦理层面,如何定义“模型参数”是否属于患者隐私,目前全球尚无统一标准,2026年欧盟发布的《医疗数据治理条例》草案中,甚至将模型参数列为“需严格保护的数据类型”;最后是商业层面,数据贡献方与模型使用方的利益分配机制尚未完善,2026年美国医疗协会的调查显示,63%的医院担心“数据共享后无法获得合理回报”。
西医诊疗与中医调理及家居装饰热度持续攀升,相关技术取得新突破 但这些挑战并未阻碍联邦学习的普及,2026年4月,世界卫生组织发布的《全球数字健康战略(2026-2030)》明确将联邦学习列为“医疗数据共享的核心技术”,并承诺在未来五年投入10亿美元支持发展中国家建设联邦学习基础设施,国家卫健委已启动“医疗联邦学习示范工程”,计划在2027年底前覆盖全国80%的三甲医院和50%的基层医疗机构。
“联邦学习不是解决所有医疗数据问题的‘银弹’,但它是目前最接近‘完美方案’的技术。”麻省理工学院医疗AI实验室主任安娜·罗德里格斯在2026年的国际医疗数据大会上总结,“它让数据从‘孤岛’变为‘群岛’——每个机构仍保留自己的数据主权,但通过模型参数的共享,实现了知识的‘流动’,这正是在线医疗从‘连接’走向‘融合’的关键。”
2026年的春天,当一位印尼农民通过“Halodoc”平台接受登革热预警,当一位中国县级医院的患者用上全国顶尖医院联合训练的AI心电图诊断,当一家印度药企通过联邦学习平台发现新的阿尔茨海默病药物分子——这些场景背后,是联邦学习框架正在重塑的医疗未来:一个数据更安全、诊断更精准、服务更公平的在线医疗时代,已悄然