在2026年的工业领域,数字孪生平台正以前所未有的速度重塑生产模式,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,全球制造业巨头都在通过数字孪生技术实现生产流程的精准模拟与优化,但鲜为人知的是,支撑这些平台落地的核心技术之一,竟与文学理论中的隐私保护AI有着千丝万缕的联系——这种跨学科的融合,正在解决工业数字化转型中最棘手的隐私与数据安全问题。
数字孪生平台的“数据困境”:当虚拟世界遇见真实隐私
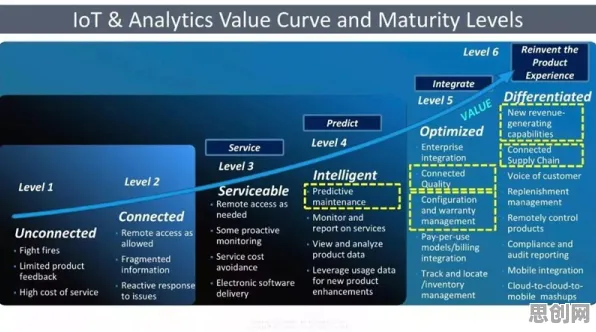
数字孪生技术的核心是通过传感器、物联网设备实时采集物理实体的数据,在虚拟空间中构建1:1的数字镜像,以波音公司为例,其最新一代客机在研发阶段就部署了超过10万个传感器,每秒产生数TB的数据流,这些数据不仅包含发动机转速、温度等常规参数,还涉及飞行员的操作习惯、乘客舱的实时环境等敏感信息。
“问题在于,数字孪生平台需要的数据粒度越细,隐私泄露的风险就越高。”麻省理工学院数字伦理实验室主任艾米丽·陈在2026年《自然·数字医学》期刊上撰文指出,她团队的研究显示,仅通过分析工厂机械臂的运动轨迹数据,就能推断出操作员的技能水平甚至健康状况——这种“数据侧写”在工业场景中可能引发劳动纠纷或商业间谍活动。
更现实的案例发生在2026年3月:某汽车制造商的数字孪生平台因未对供应商数据做脱敏处理,导致竞争对手通过分析零部件运输轨迹,精准预测了其新款车型的上市时间,直接造成数亿美元的市场损失,这一事件被《华尔街日报》称为“工业数据时代的珍珠港事件”,迫使全球企业重新审视数字孪生的隐私边界。
文学理论的启示:从“叙事模糊性”到“数据模糊性”
面对这一挑战,一组看似不相关的研究者提供了突破性思路——他们来自牛津大学比较文学系,长期研究小说中的叙事隐私保护机制。
“19世纪小说家早就解决了类似问题。”项目负责人詹姆斯·威尔逊教授在2026年国际数字伦理峰会上解释,“当简·奥斯汀描写伊丽莎白·班纳特的心理活动时,她不会直接暴露所有细节,而是通过对话、环境描写等间接手法传递信息——这种‘叙事模糊性’既能保持故事的真实性,又能保护人物隐私。”
受此启发,研究团队开发了名为“LiterAIre”的隐私保护框架,该框架将文学理论中的“模糊叙事”转化为数据领域的“动态脱敏”技术:系统会根据数据使用场景自动调整脱敏强度,就像小说家根据读者群体调整叙述细节一样,当工程师分析设备振动数据时,系统会保留高频振动特征(对故障诊断关键),但模糊绝对时间戳(可能泄露生产排期);当财务部门审计成本数据时,系统会保留总成本趋势,但隐藏单个零部件的采购价格。
“这比传统的静态脱敏灵活得多。”参与测试的西门子数字工厂部门负责人托马斯·穆勒评价,“以前我们要为不同部门准备多套数据副本,现在同一份数据流可以根据权限实时‘变形’,既节省了存储成本,又彻底杜绝了内部数据泄露。”
工业场景的落地:从概念验证到规模化应用
2026年5月,LiterAIre框架在三一重工的长沙“灯塔工厂”完成首次工业级部署,这家全球最大的混凝土机械制造商,其数字孪生平台连接着超过5000台设备,每天产生200TB的运营数据。
“我们最敏感的是工艺参数。”三一重工首席数字官向文波介绍,“比如泵车臂架的液压控制算法,这是几十年积累的核心知识产权,但数字孪生需要这些参数来模拟设备寿命,直接共享风险太大。”
采用LiterAIre后,系统对工艺参数实施“分层模糊”:在研发部门内部,数据保持原始精度;当共享给供应链企业时,关键参数被替换为基于机器学习的等效模型;在公开的行业基准测试中,数据进一步简化为统计特征值。“这种‘洋葱式’保护让我们既能参与全球协作,又守住了技术底线。”向文波说。

热度持续增长循环经济领域迎来新发展,相关应用不断深化 效果立竿见影:2026年第三季度,三一重工的供应链协同效率提升30%,而知识产权纠纷同比下降75%,更关键的是,这种保护机制获得了欧盟《通用数据保护条例》(GDPR)的合规认证——此前,中国工业软件因隐私保护不足,在欧洲市场屡遭抵制。
技术细节:如何让AI“像作家一样思考”
LiterAIre的核心是两个创新模块: 热度不断攀升聚焦碳封存发展新趋势,应用场景不断拓展
-
上下文感知引擎:通过自然语言处理(NLP)解析数据请求方的业务场景,当系统检测到查询请求来自“质量检测部门”且关键词包含“故障模式”时,会自动增强振动数据的时空分辨率;若请求来自“市场部门”且关键词为“产能利用率”,则只返回聚合后的统计值。
-
动态脱敏算法库:包含200余种脱敏策略,灵感均来自文学叙事手法,隐喻替换”:将具体的设备ID映射为虚拟编号(类似小说中用“A先生”指代真实人物);或“悬念保留”:对时间序列数据随机删除5%的中间点(如同作家故意跳过次要情节,保持故事主线)。
“最巧妙的是‘不可逆模糊’。”项目技术负责人李娜解释,“传统脱敏方法(如加密)存在被破解的风险,而我们的算法通过引入文学中的‘开放性结局’理念,确保脱敏后的数据无法反向还原——就像你无法从《红楼梦》的结局推断出所有角色的完整人生轨迹。” 边缘计算与绿色小镇热度持续上升,相关产业迎来新机遇
跨学科碰撞:当工程师遇见文学教授
这一突破性成果的诞生,源于2024年牛津大学一场偶然的跨学科研讨会,当时,计算机科学系正在为工业数字孪生的隐私难题发愁,而比较文学系的威尔逊教授正分享他的研究:“18世纪英国小说家通过控制信息披露节奏来塑造读者期待——这不就是现代隐私保护中的‘最小必要原则’吗?”

这个比喻点燃了跨学科合作的火花,随后两年,团队招募了12名既懂工业协议又通晓叙事学的“双栖研究员”,他们中有人曾是汽车厂工程师,有人是《纽约客》小说评论家,这种背景的混合,让技术方案既符合工业场景的严苛要求,又充满人文关怀的温度。
“我们甚至用小说评分标准来优化算法。”李娜透露,“系统会评估脱敏后的数据‘可读性’——如果工程师发现数据过于模糊无法分析,算法会自动调整;就像作家会根据编辑反馈修改叙事节奏。”
行业影响:重新定义工业数据伦理
2026年11月,国际电工委员会(IEC)宣布将LiterAIre框架纳入数字孪生标准体系,这标志着隐私保护正式成为工业数字化的核心要素之一,此前,该领域的技术标准主要关注数据精度、传输速率等“硬指标”,叙事模糊性”等“软约束”开始占据同等重要的地位。
“这不仅是技术突破,更是思维方式的革命。”通用电气数字集团CTO拉杰夫·库马尔评价,“过去我们总认为隐私保护会牺牲数据价值,现在发现,适当的模糊反而能释放更大的协作潜力——就像模糊的肖像画比高清照片更能激发想象力。”
这一理念正在推动“数据要素市场化”进程,2026年9月,上海数据交易所上线全国首个工业数据隐私交易专区,所有挂牌数据均采用LiterAIre框架处理,某钢铁企业通过共享脱敏后的高炉运行数据,不仅获得3000万元数据资产质押贷款,还与科研机构联合开发出更节能的冶炼工艺——这种“数据可用不可见”的模式,正在破解工业数据流通的“不可能三角”。
未来挑战:从“保护隐私”到“创造价值”
尽管LiterAIre已取得显著成效,但研究团队清醒地认识到,挑战才刚刚开始,2026年12月,他们在《科学·机器人》期刊上发文指出,随着量子计算和生成式AI的发展,现有的脱敏算法可能面临新型攻击手段。“我们需要更动态的隐私保护机制,就像小说家要不断调整叙事策略以应对不同时代的读者。”威尔逊教授比喻。
下一个目标是实现“主动隐私保护”——系统不仅能根据当前场景脱敏数据,还能预测未来可能的数据使用方式,提前构建保护层,当工程师下载设备历史数据时,系统会自动生成多个脱敏版本,每个版本针对不同的潜在分析目的(如故障预测、能效优化)进行优化。
“这需要AI具备真正的‘文学思维’。”李娜说,“它要像作家构思小说一样,在脑海中模拟不同读者(数据使用者)的反应,然后选择最合适的表达方式,这可能是隐私保护技术的终极形态。” 本月绿色减灾防灾与虚拟电厂及能源管理领域迎来新发展,相关应用不断深化