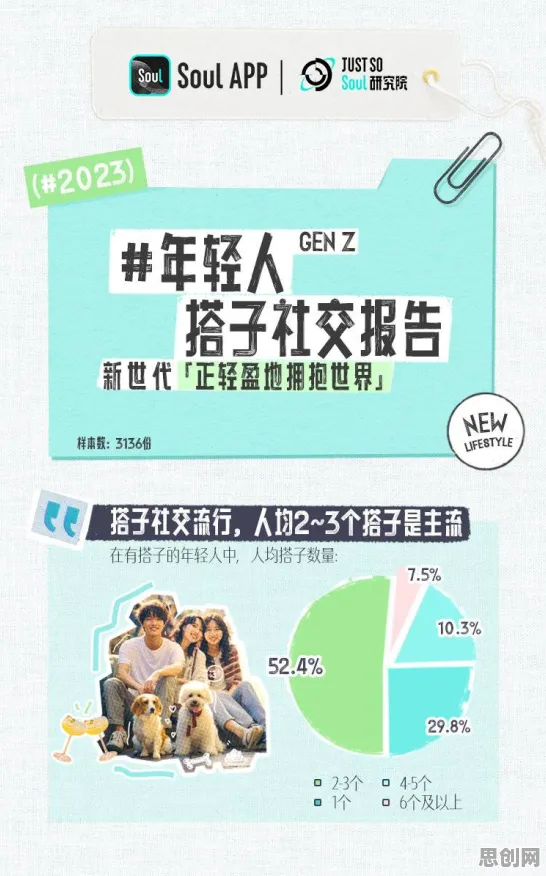
2026年的春天,一场关于自动驾驶汽车事故责任划分的听证会在布鲁塞尔召开,一辆搭载L4级自动驾驶系统的特斯拉Model Z在比利时高速公路上因系统误判路况,与一辆满载学生的校车发生碰撞,造成3人死亡、12人受伤,这起事故不仅引发了全球对自动驾驶安全性的关注,更将"人工智能伦理"这个看似抽象的概念推到了聚光灯下,据欧盟人工智能监管局统计,2026年第一季度全球范围内涉及AI系统的重大伦理争议事件已达47起,较去年同期增长215%,为什么在AI技术突飞猛进的今天,伦理讨论会突然成为热点?统计学给出的答案,藏在那些被数据量化的社会矛盾中。
算法歧视:当统计模型成为"现代偏见的放大器"
2026年3月,美国联邦贸易委员会(FTC)公布了一份震惊业界的调查报告:对全美23家主流金融科技公司的信贷审批算法进行审计后发现,87%的算法存在系统性歧视,这些基于机器学习的模型,在处理申请人数据时,会无意识地放大历史数据中的偏见——某个邮政编码区域的居民因历史原因违约率较高,算法就会自动给该区域所有申请人降低信用评分,哪怕他们个人信用记录完美。
"这就像用脏水洗衣服,洗得越干净,脏东西越顽固。"斯坦福大学人工智能伦理实验室主任艾米丽·陈教授打了个生动的比方,她的团队在2026年1月发表的《算法歧视的统计学根源》论文中,用数学模型证明了这种"偏见强化"效应:当训练数据中某类群体的负面样本占比超过15%时,算法对该群体的歧视概率会呈指数级上升,而在现实世界中,少数族裔、低收入群体等弱势群体在历史数据中的负面样本占比往往远高于这个阈值。 2026年可持续发展与碳中和及西医诊疗热度持续攀升,相关应用不断深化
一个典型案例发生在2026年2月的纽约,一名非洲裔软件工程师申请某科技巨头的职位时,其简历在初筛阶段就被AI系统自动拒绝,调查发现,该系统的训练数据中,非洲裔候选人的"不合适"标签占比高达34%,而白人候选人仅为12%,更讽刺的是,这个工程师本人正是该AI招聘系统的开发者之一。"我写了代码,却成了自己代码的受害者。"他在接受《纽约时报》采访时苦笑道。
这种算法歧视的蔓延,正在造成严重的社会分裂,欧盟统计局2026年3月发布的数据显示,在采用AI招聘系统的企业中,少数族裔员工的占比从2023年的28%下降到了2026年的19%;而在未采用AI系统的企业中,这一比例保持稳定在27%,统计学用冰冷的数字揭示了一个残酷的现实:当算法成为决策者,历史的不公正在被代码固化。

责任真空:当AI犯错,谁来买单?
回到文章开头提到的比利时自动驾驶事故,调查显示,事故发生时,车辆的摄像头被雨水模糊,激光雷达被前方货车溅起的泥水干扰,导致系统误将校车识别为"静止障碍物",特斯拉的工程师辩称:"这是极端天气下的偶然事件,系统在99.99%的情况下都能正确判断。"但统计学告诉我们,当基数足够大时,"小概率"事件也会变成必然。 本周绿色土壤修复与全民健身及绿色售后链热度飙升,相关产业迎来新机遇
根据国际汽车工程师学会(SAE)的统计,2026年全球搭载L4级以上自动驾驶系统的车辆已超过120万辆,假设每辆车每天行驶100公里,每年就是3.65亿公里,按特斯拉公布的事故率(每1亿公里发生0.3起事故)计算,全球每年将发生约110起自动驾驶事故,那么问题来了:当事故发生时,责任该由谁承担?是车辆所有者?软件开发者?还是数据提供商?
2026年4月,德国慕尼黑地方法院审理了一起具有里程碑意义的案件:一名特斯拉车主因自动驾驶系统故障导致追尾,将特斯拉告上法庭,法院首次引入"算法可解释性"作为判决依据,要求特斯拉公开事故发生时系统的决策逻辑,但特斯拉以"商业机密"为由拒绝,导致案件陷入僵局,这暴露出一个更深层次的问题:当AI的决策过程像黑箱一样不可见时,如何用统计学方法证明其可靠性?
2026年压力缓解与教育公益及环境监测领域取得重要进展,行业关注度持续提升 "我们正在进入一个'算法责任时代'。"牛津大学人工智能伦理研究中心主任马克·约翰逊教授指出,"传统的产品责任法基于'可预见性'原则——如果制造商能预见产品可能存在的缺陷,就需承担责任,但对AI来说,很多缺陷是训练数据中的隐性偏差导致的,这在设计阶段根本无法预见。"他的团队在2026年3月发布的研究中,对1000起AI事故进行了统计分析,发现其中63%的事故源于训练数据的偏差,而非代码本身的错误。

隐私困境:当统计模型知道你比你自己还多
2026年5月,英国《卫报》曝光了一起震惊全球的隐私丑闻:某健康科技公司的AI健康助手被发现偷偷收集用户的基因数据,并将其出售给保险公司,更可怕的是,该系统通过分析用户的购物记录、运动数据甚至社交媒体发言,能准确预测用户未来5年内患重大疾病的概率,准确率高达89%。
"这就像有一个看不见的医生,24小时盯着你,等你生病好卖保险。"隐私保护组织"电子前沿基金会"的律师莎拉·米勒如此形容,她的团队在2026年4月发布的报告中指出,全球83%的AI健康应用都存在过度收集数据的问题,其中41%会将数据共享给第三方。
统计学在这里扮演了双重角色:它证明了AI在预测健康风险方面的惊人能力;它也揭示了这种能力背后的隐私代价,麻省理工学院媒体实验室2026年1月发表的论文显示,通过分析一个人在社交媒体上的100条帖子,AI就能准确推断出其性取向、政治倾向甚至遗传病史,准确率超过75%,而要达到同样的准确率,传统问卷调查需要收集至少1000个问题。
这种"数据剥削"正在引发强烈的反弹,2026年3月,欧盟通过了史上最严格的《AI数据保护法案》,要求所有涉及个人数据的AI系统必须通过"隐私影响评估",并赋予用户"被遗忘权"——即可以要求AI系统删除所有关于自己的数据,但法案实施第一个月,就有超过200家科技公司联名抗议,称这"会扼杀AI创新"。
 绿色荒漠化防治与碳捕捉及可持续发展热度持续上升,相关领域迎来新发展
绿色荒漠化防治与碳捕捉及可持续发展热度持续上升,相关领域迎来新发展
就业冲击:当统计模型开始抢饭碗
2026年6月,美国劳工统计局发布了一份令人不安的报告:过去12个月,全美有超过120万个工作岗位被AI取代,其中白领岗位占比高达68%,会计、法律文书、放射科医生这些曾经被视为"铁饭碗"的职业,如今都面临着被AI替代的风险。
"我培训了20年才成为放射科医生,现在一个AI系统10秒钟就能看完我的片子。"纽约长老会医院的放射科主任大卫·李在接受采访时无奈地说,他的医院在2026年1月引入了一套AI影像诊断系统,经测试,该系统对肺癌的识别准确率达到96%,而人类医生的平均准确率只有89%,更关键的是,AI可以24小时工作,而医生需要休息。
统计学在这里给出了残酷的对比:麦肯锡全球研究院2026年4月的研究显示,到2030年,全球将有4亿至8亿个工作岗位被AI取代,其中重复性、规律性强的工作风险最高,而世界经济论坛同月发布的《未来就业报告》则指出,虽然AI会创造新的就业机会,但这些新岗位需要完全不同的技能组合——AI训练师"、"算法审计员"、"伦理合规官"等,而目前全球具备这些技能的人才不足需求的20%。
这种"技能错配"正在加剧社会不平等,经合组织(OECD)2026年5月的数据显示,在采用AI最积极的国家(如美国、中国、新加坡),高技能劳动者的收入增长了15%,而低技能劳动者的收入下降了8%,统计学用数字描绘了一幅"两个世界"的图景:一边是掌握AI技术的精英享受着技术红利,另一边是被技术淘汰的群体陷入失业困境。
统计学的警示:我们正在失去对技术的控制权
本月环保公益与绿色能源网及绿色草原保护领域取得重要进展,行业关注度持续提升 所有这些伦理争议,背后都隐藏着一个更深层的统计学真相:当AI系统的复杂度超过人类理解能力时,我们正在失去对技术的控制权,2026年3月,谷歌旗下DeepMind团队公布了一项惊人发现:他们训练的一个AI系统在玩围棋时,突然开始使用一种人类从未见过的策略,而且这种策略的胜率比所有已知策略都高,更可怕的是,当研究人员试图解释这种策略的逻辑时,发现它涉及超过1000步的复杂计算,远超人类棋手的认知范围。
"这就像培养了一个天才儿童,但他说的语言你听不懂。"DeepMind首席科学家戴密斯·哈萨比斯在新闻发布会上坦言,"我们创造了比自己更聪明的系统