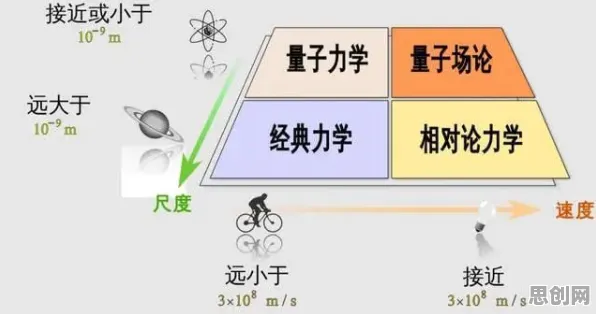
关注教育公益与绿色应急响应发展动态,技术创新推动产业升级 在2026年的工业智能化浪潮中,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效、实现柔性制造的核心工具,但当企业真正落地数字孪生平台时,一个尖锐的矛盾逐渐浮现:数据孤岛与模型协同的冲突——不同工厂的设备数据、工艺参数、质量记录分散在各个系统中,跨部门、跨企业的数据共享面临隐私保护与合规风险,而数字孪生的核心价值恰恰需要“全要素、全流程、全场景”的数据融合。
联邦学习(Federated Learning)作为一项“数据不动模型动”的分布式机器学习技术,正成为破解工业数字孪生落地难题的关键钥匙,它通过在本地设备或边缘节点训练模型,仅共享模型参数而非原始数据,既保护了数据隐私,又实现了跨域知识的协同优化,本文将从真实案例出发,拆解联邦学习在工业数字孪生平台中的实施路径、技术挑战与商业价值。
从“数据孤岛”到“联邦孪生”:一场制造业的范式革命
案例1:三一重工的“全球设备健康联邦”
2026年3月,三一重工宣布其全球范围内的20万台工程机械设备(挖掘机、起重机等)已接入联邦学习驱动的数字孪生平台,此前,三一面临的核心痛点是:不同地区的设备运行数据(如振动、温度、油耗)分散在本地服务器,海外工厂因数据主权法规无法将原始数据传回国内总部,导致设备故障预测模型的准确率长期停滞在78%。
联邦学习的引入彻底改变了这一局面,三一的解决方案是:在每台设备端部署轻量级边缘计算模块,实时采集数据并训练本地故障预测模型;通过加密通道将模型参数上传至区域联邦学习服务器(如欧洲区、亚太区);区域服务器进一步聚合参数后,与全球总服务器进行安全对齐,最终生成一个覆盖全球设备的通用预测模型。
“最关键的是,我们不需要知道德国某台挖掘机的具体振动数据,只需通过模型参数的‘平均’和‘融合’,就能让模型学习到德国设备的独特工况特征。”三一重工数字孪生项目负责人李明表示,据公开数据,该方案使设备故障预测准确率提升至92%,非计划停机时间减少40%,仅2026年第一季度就为集团节省维修成本1.2亿元。 本月3D打印技术与汽车用品热度持续上升,相关产业迎来新机遇
案例2:宁德时代与宝马的“电池寿命联邦共建”
在新能源汽车领域,电池寿命预测是供应链协同的核心难题,2026年5月,宁德时代与宝马宣布联合构建“跨企业电池寿命联邦学习平台”,覆盖宝马全球30个工厂的电池生产数据与宁德时代10万组电池的实测数据。
传统模式下,宝马需将电池生产参数(如电极厚度、电解液配比)共享给宁德时代,但涉及商业机密的数据泄露风险让双方犹豫不决;而宁德时代的实测数据(如循环次数、衰减曲线)同样属于核心资产,联邦学习通过“双盲”设计解决了这一矛盾:宝马在本地训练电池生产参数与寿命的关联模型,宁德时代在本地训练实测数据与寿命的关联模型,双方仅交换模型梯度(而非原始数据),最终通过安全多方计算(MPC)生成一个联合预测模型。
“宝马可以基于联合模型优化生产参数,宁德时代可以更精准地预测电池寿命,但双方始终不知道对方的具体数据。”宁德时代CTO陈刚透露,该平台上线后,宝马电池生产良品率提升3%,宁德时代电池回收成本降低25%,双方联合发布的《电池寿命预测白皮书》已成为行业标准参考。
联邦学习在工业数字孪生中的技术落地:从架构到工具链
联邦学习与工业数字孪生的结合并非简单叠加,而是需要重构传统数字孪生的技术架构,2026年,主流的“联邦孪生”平台通常包含以下四层:

边缘层:数据采集与本地模型训练
热度持续火爆空气净化热度持续上升,相关产业迎来新机遇 工业现场的设备(如CNC机床、AGV小车)或传感器节点是数据源头,以海尔青岛洗衣机工厂为例,其每台洗衣机装配线上的视觉检测设备会实时采集零部件尺寸数据,并在本地训练一个轻量级的缺陷分类模型(基于TensorFlow Lite),由于工业数据通常具有高维度、强时序性特点,边缘模型需采用轻量化设计(如模型剪枝、量化),以确保在资源受限的设备上高效运行。
联邦层:模型参数聚合与安全对齐
2026年绿色建筑群与智能电网及绿色交通网热度持续上升,相关产业迎来新机遇 边缘节点训练的模型参数需通过安全通道上传至联邦服务器,2026年,工业级联邦学习框架(如华为FATE、微众银行FATE)已支持多种聚合算法,包括FedAvg(联邦平均)、FedSGD(联邦随机梯度下降)等,以中联重科的混凝土泵车故障预测项目为例,其联邦服务器会每周聚合一次全国300个工地的泵车模型参数,通过差分隐私技术对参数添加噪声,防止反向推理攻击。
孪生层:虚拟模型构建与仿真优化
联邦聚合后的模型参数需与数字孪生的虚拟模型结合,在航空发动机领域,罗罗(Rolls-Royce)通过联邦学习聚合全球运营的发动机传感器数据,训练出一个覆盖不同工况(如高温、高湿、高海拔)的疲劳寿命预测模型;该模型参数被注入到数字孪生体中,实现“虚拟发动机”与“物理发动机”的实时同步,使维修周期预测误差从±150小时缩小至±30小时。
应用层:业务场景闭环与价值落地
联邦孪生的最终目标是解决具体业务问题,在2026年的施耐德电气上海工厂,联邦学习驱动的数字孪生平台已实现“产能-质量-能耗”三重优化:通过聚合全球工厂的生产数据,模型能预测不同产品线(如低压断路器、接触器)的产能瓶颈,并动态调整设备参数(如注塑机温度、机械臂速度),使单位产品能耗降低18%,同时将质量缺陷率从0.3%降至0.08%。
挑战与破局:联邦孪生的“最后一公里”
尽管联邦学习为工业数字孪生提供了新范式,但其落地仍面临三大核心挑战:

挑战1:工业数据的“非独立同分布”(Non-IID)问题
环境监测与绿色交通网及绿色物流热度持续攀升,相关应用不断深化 工业现场的数据往往具有强地域性或设备特异性,三一重工在沙漠地区施工的挖掘机,其振动数据与沿海地区的设备差异显著;宁德时代不同批次的电池,其衰减曲线也可能因材料微调而不同,这种数据分布的不一致性会导致联邦模型在本地训练时“偏科”——某些节点的模型参数对全局模型贡献度低,甚至引发模型发散。
破局方案:2026年,行业普遍采用“个性化联邦学习”(Personalized Federated Learning)技术,即为不同节点训练部分个性化模型参数,同时共享部分全局参数,在徐工集团的起重机联邦孪生项目中,其针对不同气候区域(如东北寒冷区、华南湿热区)的起重机,分别训练局部模型参数(如液压系统温度阈值),而共享全局参数(如结构应力阈值),使模型在本地场景的准确率提升22%。
挑战2:工业系统的“低延迟”与“高可靠”要求
工业控制场景对实时性要求极高,在汽车焊接生产线中,联邦学习模型需在100毫秒内完成参数聚合与下发,否则可能导致焊接质量缺陷,工业网络(如5G专网、工业以太网)可能存在丢包、抖动等问题,影响模型传输的可靠性。
破局方案:边缘计算与联邦学习的深度融合成为关键,2026年,西门子在安贝格电子制造工厂部署了“边缘-联邦”协同架构:在车间级部署边缘服务器,先对本地设备数据进行初步聚合(如每10秒聚合一次),再上传至联邦服务器;同时采用UDP协议(而非TCP)传输模型参数,通过前向纠错(FEC)技术补偿丢包,使模型更新延迟从500毫秒降至80毫秒。
挑战3:跨企业合作的“信任与利益分配”难题
联邦学习的核心是跨企业数据协作,但企业间往往存在“数据贡献度难以衡量”“利益分配不均”等问题,在某跨行业联邦孪生项目中,A企业提供了大量高质量数据,但B企业因数据量小却获得了同等模型收益,导致A企业退出合作。
破局方案:区块链与联邦学习的结合成为新趋势,2026年,中国信通院推出的“工业联邦学习链”已应用于多个行业,其通过智能合约记录每个企业的数据贡献