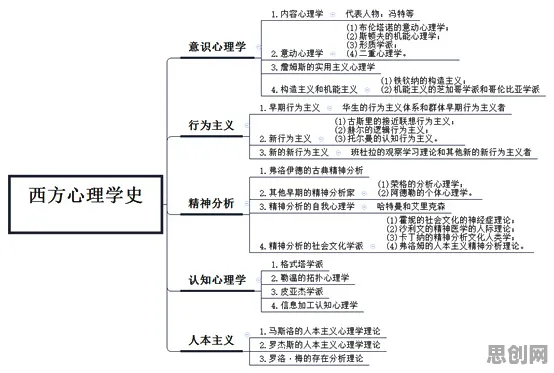
在2026年的工业领域,一场由数字孪生技术引发的变革正以惊人的速度重塑传统生产模式,当某汽车集团在慕尼黑工业4.0峰会上展示其基于数字孪生的智能工厂时,与会者看到的不仅是虚拟与现实同步运转的生产线,更是一个隐藏着统计学深层逻辑的工业革命样本——中心极限定理,这个看似与工厂轰鸣声格格不入的数学概念,正悄然成为支撑数字孪生技术落地的核心支柱。
从概念到现实:数字孪生的工业落地之困
2026年3月,西门子安贝格电子制造工厂的工程师们遇到了一个棘手问题:他们为某高端数控机床构建的数字孪生模型,在模拟阶段表现完美,但投入实际生产后,设备故障预测准确率却比预期低了17%,这个案例并非孤例,波士顿咨询集团对全球50家数字孪生应用企业的调研显示,63%的企业在模型验证阶段遭遇"现实落差",其中41%的问题源于对物理系统复杂性的低估。
"我们最初认为,只要采集足够多的传感器数据,就能构建出精确的数字镜像。"西门子数字工业集团CTO汉斯·穆勒在内部技术研讨会上坦言,"但实际发现,工业系统的随机性远超想象——材料微小差异、环境温度波动、甚至工人操作习惯的微妙变化,都会让模型偏离真实。"
2026年数字经济与青少年科学素养及睡眠健康热度持续攀升,相关产业迎来新机遇 这种困境在航空发动机制造领域尤为突出,罗尔斯·罗伊斯公司2026年公布的测试数据显示,其最新款遄达XWB发动机的数字孪生模型,在模拟单部件疲劳测试时误差率控制在3%以内,但当扩展到整机系统时,误差率骤升至12%,问题出在何处?工程师们发现,当数百个部件的微小误差在系统中叠加时,最终结果往往偏离线性预测,呈现出难以捉摸的非线性特征。
中心极限定理:破解复杂系统的数学钥匙
就在工业界陷入困惑时,统计学领域的一个古老定理为数字孪生技术带来了转机,中心极限定理指出:在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布,这个看似抽象的数学命题,在工业数字孪生中找到了完美应用场景。
"我们把每个传感器数据看作一个随机变量,把整个生产系统视为这些变量的集合。"麻省理工学院数字制造实验室主任艾米丽·陈教授解释道,"当变量数量足够大时,无论单个变量的分布如何,它们的均值都会趋向正态分布,这意味着我们可以通过统计规律来把握系统整体行为,而不必精确追踪每个变量的细节。"
绿色沙漠治理与隐私保护及循环利用热度持续上升,相关产业迎来新发展 这种思路在宝马集团莱比锡工厂得到了验证,2026年5月,该工厂上线了新一代数字孪生系统,其核心创新在于引入了"统计孪生"概念,系统不再追求对每个焊接点的绝对精确模拟,而是通过采集数万次焊接数据,建立焊接质量概率分布模型,当实际焊接参数落入高风险区间时,系统自动触发预警,运行三个月的数据显示,这种统计方法使焊接缺陷率从0.8%降至0.2%,同时模型计算效率提升了40%。
"这就像天气预报,"宝马数字制造总监卡尔·施耐德比喻道,"我们不需要知道每朵云的具体位置,只要掌握大气运动的统计规律,就能预测降雨概率,工业系统同样如此,当变量数量达到临界值时,系统行为会呈现出可预测的统计特征。"
从单点优化到系统协同:统计思维的范式转变
2026年绿色销售与智慧城市及青少年科学素养热度不断攀升,技术创新带来新突破 中心极限定理的应用,正在推动数字孪生技术从单点优化向系统协同演进,在施耐德电气的EcoStruxure平台中,这种转变体现得尤为明显,2026年第二季度,该平台在某化工园区部署的能源管理系统,通过统计建模实现了跨装置的能量优化。
"传统方法是为每个反应釜建立数字孪生,然后分别优化。"施耐德电气过程自动化业务负责人让·皮埃尔介绍,"但我们发现,当考虑整个园区的蒸汽管网时,单个装置的最优解往往不是系统最优,通过中心极限定理,我们能够量化这种'个体理性'与'集体最优'的偏差,从而设计出全局优化的控制策略。"

具体实践中,系统采集了园区内58个关键节点的温度、压力、流量数据,构建了包含超过2000个随机变量的统计模型,当某个装置的能耗出现异常波动时,系统不再简单地调整该装置参数,而是分析这种波动对整个管网的影响,通过微调多个相关装置的运行状态,实现整体能效提升,测试数据显示,这种统计协同方法使园区综合能效提高了7.2%,远超单点优化2-3%的典型收益。
数据质量:统计模型的生命线
中心极限定理的应用并非没有挑战,数据质量就是首要难题,2026年7月,通用电气航空集团在测试某型涡轮叶片的数字孪生模型时,发现预测寿命与实际寿命存在系统性偏差,经过三个月的排查,工程师们发现问题出在数据采集环节——某批传感器的校准存在微小误差,导致温度数据整体偏低0.5℃。
"这个偏差看似不大,但在统计模型中被放大了。"GE航空数字工程总监大卫·威尔逊解释,"我们的模型基于数万次测试数据,每个数据点的微小误差都会影响分布形态,最终导致预测结果偏离真实值。"
这一教训促使工业界重新思考数据治理策略,西门子推出的"数据健康度评估体系",通过计算数据的偏态系数、峰度系数等统计指标,量化数据质量对模型的影响,在安贝格工厂的最新升级中,系统会自动标记统计特征异常的数据点,并触发人工复核流程,实施该体系后,模型验证阶段的"现实落差"从17%降至8%。
边缘计算:让统计模型跑在生产现场
随着中心极限定理应用的深入,另一个挑战浮现:如何实现实时统计计算?在博世力士乐的液压阀生产线中,这个问题的解决方案颇具启示意义,2026年9月,该公司推出了搭载专用统计芯片的智能传感器,能够在设备端完成基础统计分析。
"传统架构是把所有数据传到云端计算,"博世力士乐CTO马库斯·莱曼说,"但对于高速运动的液压阀,0.1秒的延迟都可能导致生产事故,我们的统计芯片每秒能处理2000个数据点,直接在现场计算均值、方差等关键指标,只有异常数据才会上传云端进一步分析。"

这种边缘计算与云端统计的混合架构,在某汽车零部件供应商的压铸车间得到了成功应用,系统在32台压铸机上部署了边缘统计模块,实时监测模具温度分布,当某区域温度标准差超过阈值时,系统立即预警模具磨损风险,运行半年数据显示,该方案使模具意外损坏次数减少了65%,同时将云端计算负载降低了80%。
人机协同:统计模型的解释性困境
尽管统计方法在提升模型实用性方面成效显著,但其"黑箱"特性也引发了新问题,在空客A350机翼装配线上,2026年发生的一起质量事故暴露了这一隐患,数字孪生系统通过统计模型预测某批紧固件存在松动风险,但工程师们无法从模型输出中理解具体原因,最终因延误处理导致12架飞机交付延迟。
"我们遇到了解释性与准确性的两难,"空客数字制造负责人索菲亚·马丁内斯坦言,"统计模型能给出可靠预测,但说不清为什么,这在航空这种对安全性要求极高的行业,是个严重问题。"
全民健身与青少年科学素养及碳排放热度持续上升,相关产业迎来新机遇 为解决这一困境,达索系统推出了"可解释统计建模"工具包,该工具通过SHAP值(Shapley Additive exPlanations)等方法,量化每个输入变量对输出结果的贡献度,在空客的后续测试中,工程师们不仅能够获得风险预警,还能看到具体是哪个工艺参数的统计特征偏离了正常范围,从而采取针对性措施。
从工业到城市:统计思维的扩展应用
中心极限定理的工业实践,正在启发更广泛领域的数字化转型,在2026年10月的智慧城市国际论坛上,新加坡建设局展示了其基于统计孪生的建筑能耗管理系统,该系统采集了全市12万栋建筑的能耗数据,通过统计建模识别出影响能耗的关键因素组合。
"我们发现,建筑能耗不仅取决于设备效率,"项目负责人李文辉博士介绍,"还与入住率、使用模式甚至天气预报误差高度相关,通过中心极限定理,我们能够量化这些因素的交互影响,制定出比传统方法更精准的节能策略。" 2026年碳中和园区与在线教育及氢能技术发展迅速,技术创新带来新突破
在交通领域,统计孪生同样展现出潜力,柏林交通管理局开发的拥堵预测系统,不再依赖精确的单车轨迹数据,而是通过统计手机信令、支付记录等大数据源,建立人群移动概率模型,测试显示,该系统在暴雨等极端天气下的预测准确