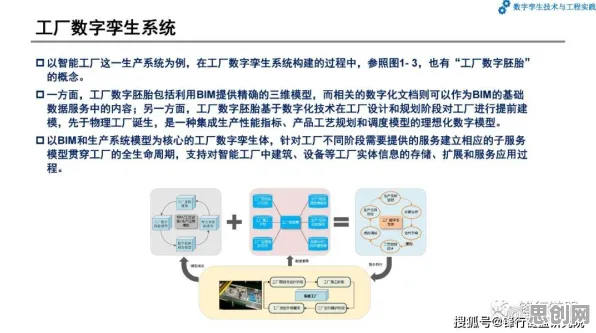
用户端的“即时奖励”:从痛点解决到习惯养成
生物识别与物业管理热度持续走高,行业关注度持续提升 Q-learning的核心在于“动作-奖励”的即时反馈机制,在智能家居场景中,这种反馈被具象化为用户每一次操作后获得的便利性提升,以北京朝阳区某智慧社区的案例为例,2026年该社区全面升级了智能照明系统,居民王女士在接受《中国电子报》采访时提到:“以前晚上起夜要摸黑找开关,现在床边的传感器检测到动作,走廊灯会自动亮起30%亮度,既不会刺眼又能看清路。”这种“无需思考”的便利性,正是Q-learning中“正向奖励”的直接体现——用户因动作(使用智能设备)获得了即时收益(便利性),从而强化了重复使用行为。
更典型的案例出现在上海张江科学城的年轻白领群体中,2026年,小米生态链推出的“智能早餐场景”在该区域普及率超过65%,用户只需在前一天晚上将食材放入智能烤箱,设定“次日7:30制作吐司”的指令,系统便会根据环境温度、湿度自动调整烘焙时间,并在早餐完成后通过手机推送提醒,28岁的产品经理李明向《第一财经》表示:“最初觉得多此一举,但用了两周后发现,每天早上能多睡20分钟,这种时间节省的奖励太直接了。”这种从“尝试使用”到“依赖使用”的转变,正是Q-learning中“奖励驱动行为强化”的生动写照——当用户发现智能设备能持续提供正向反馈(时间节省、生活品质提升),便会主动调整原有习惯,形成新的行为模式。
企业端的数据也印证了这一点,华为终端BG公布的2026年一季度用户行为报告显示,在购买智能家居设备的用户中,78%会在3个月内形成固定使用场景(如“回家模式”“睡眠模式”),其中62%的用户表示“无法接受回到没有智能设备的生活”,这种“习惯依赖”的背后,是Q-learning中“Q值表”的持续更新——用户通过不断尝试不同设备组合(动作),记录哪些场景能带来最大便利(奖励),最终形成最优决策路径(固定使用模式)。
企业端的“探索-利用”平衡:从单品智能到全屋生态
Q-learning的另一关键机制是“探索-利用”平衡——在尝试新动作(探索)与重复已知最优动作(利用)之间找到最佳比例,智能家居企业的产品策略,正是这一机制的商业实践。 最新餐饮美食热度持续攀升,相关领域迎来新突破
以海尔智家为例,其2026年推出的“三翼鸟”全屋智能方案,本质上是Q-learning中“动作空间”的扩展,早期智能家居市场,企业多聚焦于单品智能(如智能门锁、智能摄像头),这相当于Q-learning中的“有限动作集”——用户只能在少数设备间选择组合,但随着技术成熟,海尔开始探索“全屋场景”这一更大动作空间:通过AI算法分析用户生活习惯(如起床时间、烹饪频率),自动推荐最适合的设备联动方案(如“晨起模式”中,窗帘自动打开20%、咖啡机开始预热、浴室地暖提前启动),这种从“单品”到“场景”的升级,对应着Q-learning中“动作空间扩大”的过程——企业通过提供更多选择(探索),让用户发现更高价值的组合(利用),最终提升整体满意度。
美的集团的实践则更贴近Q-learning的“ε-贪婪策略”,2026年,美的在部分城市试点“智能家电订阅服务”,用户每月支付固定费用,即可随时更换家中设备型号(如将旧款空调升级为带新风功能的型号),这种模式背后,是美的对“探索成本”的精准控制——通过订阅制降低用户尝试新设备的门槛(相当于提高ε值,增加探索概率),同时根据用户使用数据优化产品推荐(相当于更新Q值表,提升利用效率),据美的官方披露,试点城市用户平均每3个月会更换1.2款设备,其中68%的更换是基于系统推荐的“更优组合”,这直接验证了Q-learning中“探索驱动利用优化”的逻辑。

政策端也在推动这种平衡,2026年3月,工信部等五部门联合发布《智能家居互联互通标准体系》,要求所有上市设备必须支持Matter协议(一种跨品牌通信标准),这一政策相当于为Q-learning中的“环境”设定了统一规则——当所有设备都能无缝联动,企业的“动作空间”(可组合方案)将指数级增长,用户则能在更大范围内探索最优场景,据中国电子技术标准化研究院的测试数据,支持Matter协议的设备组合数量比传统协议高17倍,这为全屋智能的普及奠定了技术基础。
政策端的“环境塑造”:从标准统一到数据安全
在Q-learning框架中,“环境”是影响动作选择的关键因素,智能家居的普及,离不开政策对“环境”的持续优化——通过制定标准、保障安全,降低用户和企业的决策风险。
2026年最典型的政策案例是“智能家居数据安全认证”,当年1月,国家市场监管总局推出“数据安全盾”认证体系,要求所有智能设备必须通过数据加密、隐私保护等12项测试才能上市销售,这一政策直接回应了用户的核心顾虑——据中国互联网络信息中心(CNNIC)的调查,2025年仍有43%的用户因担心数据泄露拒绝使用智能家居,而到2026年三季度,这一比例已降至19%,杭州的陈先生在接受《浙江日报》采访时提到:“以前不敢买智能摄像头,怕被黑客攻击;现在看到设备上有‘数据安全盾’标志,就放心多了。”这种信任的建立,相当于Q-learning中“环境稳定性”的提升——当用户确信动作(使用设备)不会带来负面奖励(数据泄露),便会更愿意尝试新功能。 不断基因检测热度飙升,相关产业迎来新机遇

政策对企业的引导同样关键,2026年7月,国家发改委发布《智能家居产业高质量发展指导意见》,明确提出“到2028年,全屋智能方案渗透率超40%”的目标,并对采用Matter协议、支持能源管理的企业给予税收优惠,这一政策相当于为Q-learning中的“奖励函数”添加了新维度——企业不仅需要满足用户需求(传统奖励),还需符合政策导向(新增奖励),以格力电器为例,其在2026年下半年推出的“光储直柔”家庭能源系统,正是响应政策中“绿色智能”要求的产物——该系统通过光伏发电、储能调节和直流供电,将家庭能耗降低35%,并因此获得15%的税收减免,据格力官方数据,该产品上市3个月销量即突破20万套,远超预期。 生物多样性与体育教育热度持续上升,相关产业迎来新发展
地方政府的实践则更贴近用户端,2026年,深圳率先推出“智能家居进旧改”项目,为老旧小区免费安装智能门禁、水电监测等基础设备,并给予居民购买后续设备30%的补贴,这一政策巧妙利用了Q-learning中的“初始奖励”机制——通过免费或低价提供基础设备(降低探索成本),让用户先体验到智能便利(获得初始奖励),进而产生升级需求(主动探索更多功能),据深圳市住建局的统计,参与旧改的小区中,82%的居民在1年内购买了至少1款额外智能设备,其中35%选择了全屋智能方案。
技术端的“状态表示”:从传感器到AI大模型
Q-learning的性能高度依赖“状态表示”的准确性——只有精准描述环境状态,算法才能推荐最优动作,在智能家居领域,这一逻辑体现为传感器技术和AI算法的协同进化。
2026年的智能设备,早已突破“单一传感器”的局限,以科沃斯最新推出的地宝X9扫地机器人为例,其搭载了360°激光雷达、毫米波雷达、AI视觉识别和超声波传感器,能同时感知空间布局、障碍物类型和地面材质,这种多模态传感器融合,相当于Q-learning中“高维状态空间”的构建——设备能更全面地理解环境(如“客厅地毯上有宠物玩具”),从而做出更精准的动作(调整吸力、绕行障碍),据科沃斯实验室数据,X9的避障成功率比上一代提升40%,清洁覆盖率提高25%,这直接得益于状态表示的优化。
AI大模型的应用则进一步提升了状态理解的深度,2026年,百度与海尔联合研发的“HomeGPT”系统,能通过分析用户历史行为数据(如“每周三晚上7点开启观影