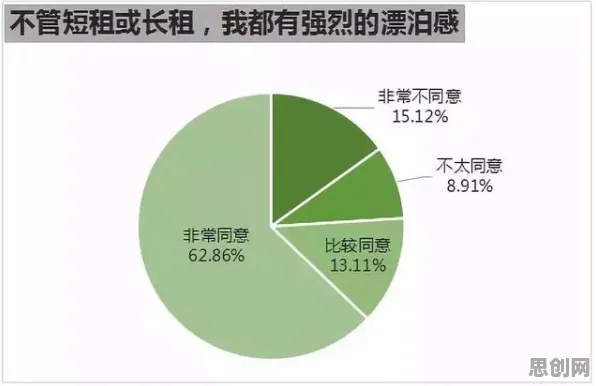
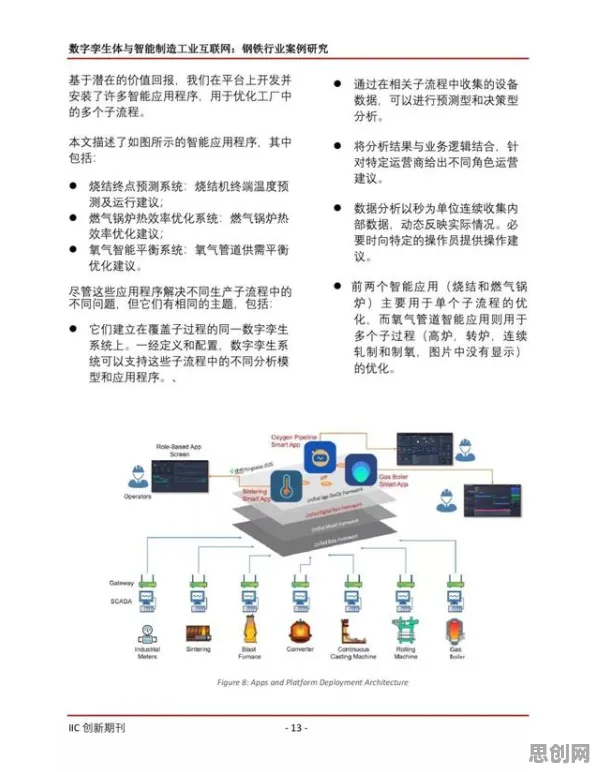
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何让这项技术真正落地生根、开花结果,仍是众多企业和技术团队不断探索的核心命题,从德国西门子的智能工厂到中国三一重工的“灯塔工厂”,从航空航天领域的精密模拟到能源行业的设备预测性维护,数字孪生正以“物理实体+虚拟镜像+数据驱动”的模式,重塑工业生产的底层逻辑,随着应用场景的复杂化,一个关键问题逐渐浮出水面:高精度数字孪生模型的“大体积”与工业现场“低算力”之间的矛盾,正成为制约技术落地的最大瓶颈,模型压缩技术的出现,不仅解决了这一矛盾,更揭示了数字孪生从“实验室原型”到“工业级应用”的深层转型逻辑。
从“能用”到“好用”:模型压缩如何破解数字孪生的算力困局
数字孪生的核心是“建模”,但工业场景对模型的要求远不止“准确”这么简单,以某汽车制造企业的冲压生产线为例,其数字孪生模型需要实时模拟金属板材的变形过程、模具的磨损状态以及液压系统的压力波动,模型参数多达数百万个,原始文件大小超过500MB,若将这样的模型部署到车间边缘计算设备(算力仅相当于一台高端笔记本电脑)上,单次仿真就需要30秒以上,而生产线要求实时响应时间必须控制在1秒内——模型“太胖”,跑不动。 本月绿色减灾防灾与低代码开发及素质教育热度持续上升,相关产业迎来新机遇
本月绿色配送与碳排放热度持续攀升,相关应用不断深化 “我们最初以为,只要模型够精确,就能解决所有问题。”该企业数字孪生项目负责人李工回忆,“但真正落地时才发现,高精度模型对算力的需求是指数级增长的,车间里的PLC(可编程逻辑控制器)根本带不动,只能把数据传到云端处理,可网络延迟又让实时性成了问题。”
这一困境并非个例,2026年,中国工业互联网研究院发布的《数字孪生技术应用白皮书》显示,在已部署数字孪生的企业中,63%因模型算力需求过高导致部署成本超预算,48%因实时性不足影响生产效率,模型压缩技术正是在这样的背景下成为“刚需”。
模型压缩的“减法艺术”:从参数裁剪到知识蒸馏
模型压缩的本质是通过算法优化,在保持模型精度的前提下减少计算量,常见的手段包括参数裁剪、量化、知识蒸馏等,而2026年的技术进展已让这些方法更贴合工业场景的需求。
以参数裁剪为例,传统方法是通过重要性评估删除不关键的神经元,但工业模型往往存在“局部敏感、整体冗余”的特点——某些参数对单个仿真结果影响小,但对长期趋势预测至关重要,2026年,清华大学与华为联合研发的“动态敏感度裁剪算法”解决了这一问题:该算法通过分析参数在历史数据中的波动模式,识别出“短期冗余但长期关键”的参数,在裁剪时保留其基础值,仅在需要时动态激活,应用该算法后,上述汽车企业的冲压模型参数减少了72%,但长期预测误差仅增加0.3%,单次仿真时间从30秒降至0.8秒,终于满足实时性要求。
量化则是另一种“瘦身”利器,工业模型的参数通常是32位浮点数,而量化技术将其转换为8位甚至4位整数,大幅减少计算量和存储需求,2026年,西门子在德国安贝格工厂的实践中,将数字孪生模型的量化精度从32位降至8位,模型体积缩小90%,推理速度提升12倍,且在设备故障预测任务中,准确率仅下降1.2%。“量化不是简单的‘降精度’,而是要在数学上证明,低精度计算对工业指标的影响在可接受范围内。”西门子数字孪生首席架构师Hans Müller解释,“我们通过误差传播分析,确保量化后的模型在关键参数(如温度、压力)上的误差不超过0.5%,这对工业应用已经足够。”

知识蒸馏则更像“老师教学生”——用一个大模型(教师模型)指导一个小模型(学生模型)学习,2026年,三一重工在泵车数字孪生项目中,将一个包含1.2亿参数的教师模型“蒸馏”为一个仅300万参数的学生模型,学生模型在液压系统故障诊断任务中的准确率达到98.7%,与教师模型几乎持平,但推理时间从2.3秒降至0.15秒。“关键在于如何设计‘知识传递’的损失函数。”三一重工智能研究院院长王博士说,“我们不仅传递最终的预测结果,还传递中间层的特征表示,让学生模型学会教师模型的‘思考方式’,而不仅仅是‘记忆答案’。”
案例透视:模型压缩如何让数字孪生“落地生根”
案例1:航空航天领域的“轻量化孪生”:从“云端跑”到“机载跑”
航空航天是数字孪生的“高端玩家”,但对模型的实时性和轻量化要求极高,2026年,中国商飞在C929客机的数字孪生项目中,遇到了一个典型难题:机翼疲劳裂纹预测模型需要实时分析传感器数据(每秒10万组),但机载计算机的算力仅相当于2018年的高端手机,原始模型根本无法运行。
项目团队采用“量化+知识蒸馏”的组合方案:首先将32位浮点模型量化为8位整数,模型体积缩小80%;再用一个更小的“学生模型”学习量化后模型的特征,学生模型参数减少95%,但疲劳裂纹预测的准确率仍保持在99.2%,轻量化后的模型被部署到机载计算机上,实现每秒10万组数据的实时分析,裂纹预警时间从传统的“事后检测”提前至“事中预测”,大幅提升了飞行安全性。
本月大数据分析与互联网医疗及绿色减灾防灾热度持续攀升,相关领域迎来新突破 “过去,数字孪生模型只能‘云端跑’,数据传上去、结果传下来,中间有延迟。”中国商飞数字孪生项目总师张工说,“现在模型能‘机载跑’,真正实现了‘数据在本地处理、决策在本地做出’,这是数字孪生从‘辅助工具’向‘核心系统’转型的关键一步。”

案例2:能源行业的“边缘孪生”:让风电场“自己会思考”
本月儿童教育与绿色供应链及绿色标签热度持续走高,行业关注度持续提升 在能源领域,数字孪生的应用正从“单台设备”向“整个系统”延伸,2026年,金风科技在内蒙古某风电场部署了全球首个“场级数字孪生系统”,该系统需要同时模拟100台风机的运行状态、电网的负荷波动以及气象条件的变化,模型参数超过10亿个,原始文件大小达20GB。
“如果把这样的模型传到云端,网络延迟会让调控指令滞后10秒以上,对风电场来说,10秒的延迟可能意味着数万元的发电损失。”金风科技数字孪生负责人陈总说,为此,团队采用“分层压缩”策略:在云端保留完整模型(用于长期趋势分析),在风电场边缘服务器部署压缩后的模型(用于实时调控),压缩比高达99.5%,但关键指标(如功率预测误差)仅增加0.8%。
更关键的是,压缩后的模型支持“自学习”——边缘服务器会根据实时数据不断调整模型参数,使预测更精准,2026年夏季,该风电场遭遇极端天气,压缩后的数字孪生系统提前3小时预测到风机叶片结冰风险,自动调整发电功率,避免了一起可能的价值500万元的设备损坏事故。“过去是‘人看孪生’,现在是‘孪生看场’。”陈总总结,“模型压缩让数字孪生从‘被动模拟’变成了‘主动决策’。”
模型压缩背后的深层逻辑:工业数字孪生的“范式转型”
模型压缩的兴起,不仅是技术层面的优化,更反映了工业数字孪生从“实验室原型”到“工业级应用”的深层转型逻辑。
从“追求精度”到“追求效率”:工业场景的“实用主义”
在学术研究中,数字孪生模型的精度往往是第一目标,但在工业现场,“够用”比“完美”更重要,2026年,麦肯锡的调研显示,78%的工业企业更关注数字孪生的“实时性”和“部署成本”,而非绝对精度,模型压缩技术通过“精度-效率”的平衡,让数字孪生真正贴合工业需求。
绿色价值链与内容审核热度持续攀升,相关技术取得新突破 以某钢铁企业的连铸生产线为例,其数字孪生模型需要预测钢水的凝固时间,原始模型精度达99.9%,但单次仿真需要5分钟,无法用于实时控制,通过参数裁剪和量化,模型精度降至99.5%,但仿真时间缩短至10秒,完全满足生产节奏。“0.4%的