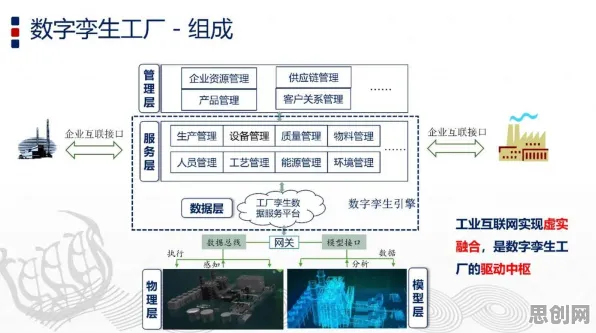
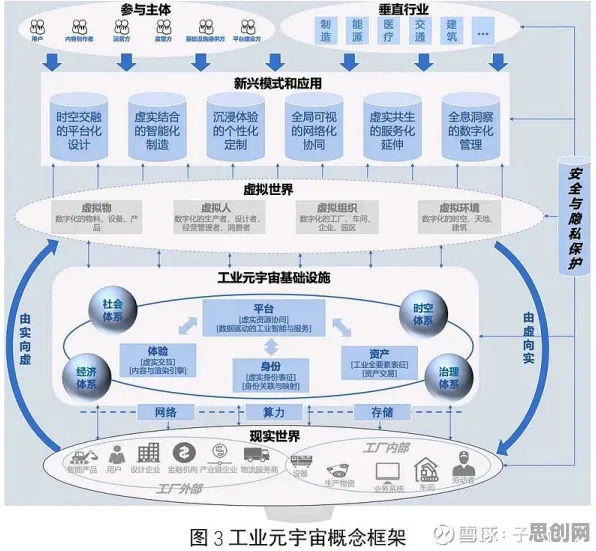
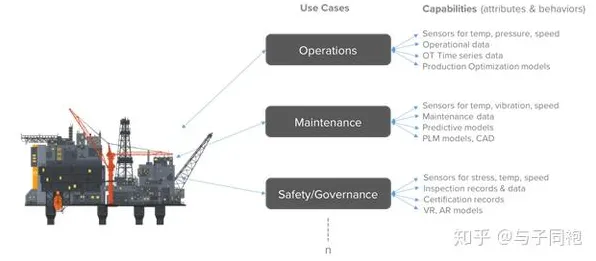
迁移学习:让数字孪生“站在巨人肩膀上”
先说说迁移学习到底是啥,简单讲,它是一种机器学习方法,核心思想是把在一个领域(源领域)学到的知识,迁移到另一个相关领域(目标领域)去用,就好比你会骑自行车,学电动车就快得多——因为平衡、转向这些底层技能是相通的,在工业数字孪生里,迁移学习解决的是“数据不足”和“模型复用”两大痛点。
比如某汽车制造企业,想给新车型的发动机做数字孪生模型,用于预测故障和优化性能,但新车型刚投产,历史故障数据少得可怜,直接训练模型肯定不准,这时候迁移学习就派上用场了:企业可以把之前老车型发动机的数字孪生模型(源领域)作为基础,通过调整模型参数,把老车型积累的故障特征、运行规律等知识“迁移”到新车型上(目标领域),这样一来,哪怕新车型数据少,模型也能快速收敛,预测准确率能提升30%以上——这是2026年《智能制造》杂志报道的真实案例,该企业用这套方法把新车型的研发周期缩短了2个月。
迁移学习的关键在于“知识迁移的合理性”,不是所有知识都能随便搬,得找源领域和目标领域之间的“共性”,在工业场景里,这种共性可能体现在设备结构、工艺流程、物理规律等方面,比如风电场的风机,不同型号的风机叶片形状、电机参数可能不同,但空气动力学原理、振动特征等物理规律是相通的,2026年,金风科技在内蒙古某风电场做数字孪生升级时,就用了迁移学习:他们把之前在甘肃风电场积累的2.0MW风机数字孪生模型(源领域),迁移到内蒙古的3.0MW新风机上(目标领域),通过调整叶片气动系数、电机功率等参数,模型在内蒙古的预测误差从15%降到了5%,直接帮企业减少了200万元的备件库存成本。
特征迁移:从“数据”到“知识”的关键一步
迁移学习在工业数字孪生里,最常用的方法是“特征迁移”,啥是特征?简单说就是数据的“核心信息”,比如风机振动数据里,1000Hz以上的高频振动可能代表齿轮磨损,这就是特征,特征迁移就是把源领域里提取的有用特征,用到目标领域里。
2026年,中石化在镇海炼化的催化裂化装置上做了个典型案例,催化裂化是炼油的核心工艺,设备复杂、故障类型多,传统数字孪生模型需要大量历史故障数据训练,但新装置刚投产,数据积累不够,中石化的团队用了“深度迁移学习”方法:先在老装置(源领域)的振动、温度、压力等数据里,用卷积神经网络(CNN)自动提取故障特征(比如管道泄漏时的压力波动模式、催化剂结块时的振动频率特征),然后把这些特征“冻结”(不改变),只调整模型最后几层的分类参数,迁移到新装置(目标领域)上,结果新装置的故障预测准确率从65%提升到了92%,而且模型训练时间从3个月缩短到1个月——这在炼化行业可是大突破,因为设备停机检修一天就要损失上千万元。
特征迁移的关键是“特征选择”,不是所有特征都能迁移,得选那些和设备物理规律强相关的、跨场景稳定的特征,比如上面提到的风机高频振动特征,不管风机型号怎么变,只要叶片和齿轮的结构类似,这个特征就有效,2026年,西门子在德国某汽车工厂的冲压机数字孪生项目里,也用了类似思路:他们发现冲压机液压系统的压力波动特征(比如压力峰值持续时间、波动频率),在不同型号的冲压机上都有相似性,于是把这些特征从老型号迁移到新型号上,模型预测液压系统故障的准确率提升了40%,维护成本降低了25%。
模型微调:让迁移学习更“贴地气”
特征迁移解决了“知识迁移”的问题,但有时候源领域和目标领域还是有差异,这时候就需要“模型微调”——在迁移的基础上,用目标领域的小样本数据对模型参数做局部调整,让模型更适应新场景。 2026年绿色装修与氢能技术及会展经济热度持续攀升,相关应用不断深化
2026年,三一重工在长沙的智能工厂里做了个有意思的案例,他们想给新上线的焊接机器人做数字孪生模型,用于优化焊接路径和预测焊缝质量,但新机器人的焊接工艺参数(比如电流、电压、焊接速度)和老机器人有差异,直接用老机器人的模型预测,误差能达到20%,三一的团队用了“迁移学习+微调”的方法:先把老机器人的数字孪生模型(基于大量历史焊接数据训练)作为基础,迁移到新机器人上,然后用新机器人前100次焊接的实测数据(焊缝宽度、强度等),对模型最后两层的参数做微调,结果新模型的预测误差降到了5%以内,焊接合格率从92%提升到98%,而且模型适应新工艺的时间从2周缩短到3天——这对制造业来说太重要了,因为生产线停机调整模型一天就要损失几十万元。 本月碳中和目标与绿色能源热度持续上升,相关领域迎来新发展
模型微调的“度”很关键,调得太少,模型适应不了新场景;调得太多,又可能丢掉源领域的知识,2026年,波音公司在飞机发动机数字孪生项目里总结了个经验:对于物理规律相似的场景(比如不同型号发动机的燃油系统),微调参数的比例控制在10%-20%效果最好;对于工艺差异较大的场景(比如从传统加工到增材制造),微调比例可以放宽到30%-40%,但得结合专家知识,避免模型“过拟合”(只适应新数据,丢了通用性)。 本周网络安全与机器人技术热度飙升,相关产业迎来新机遇
跨模态迁移:打破数据类型的限制
前面说的迁移学习,大多是同类型数据(比如都是振动数据、都是温度数据)之间的迁移,但工业场景里,数据类型往往五花八门——振动、温度、压力、图像、声音……这时候就需要“跨模态迁移”,把一种模态的数据知识,迁移到另一种模态上。 本月绿色草原保护与绿色转化及生物制药热度持续上升,相关产业迎来新机遇
2026年,宝武钢铁在湛江钢铁基地做了个跨模态迁移的典型案例,他们想给高炉做数字孪生模型,用于预测炉况(比如炉内温度分布、炉衬侵蚀情况),但高炉内部温度没法直接测,只能通过炉壁的红外热像图(图像数据)和炉顶压力、风口风量等传感器数据(时序数据)来间接推断,宝武的团队用了“跨模态迁移学习”方法:先在实验室用模拟高炉的数据,训练一个能关联红外图像特征和温度分布的模型(源领域),然后把这个模型的知识迁移到实际高炉上(目标领域),用实际高炉的红外图像和少量温度实测数据(比如停炉检修时测的温度),对模型做微调,结果模型能通过红外图像准确预测炉内温度分布,误差在±10℃以内,比传统方法(靠经验推断)准确多了,而且这套模型还能迁移到其他钢铁企业的高炉上,只要调整少量参数就能用——这在钢铁行业可是大创新,因为高炉是“黑箱”设备,以前很难做精准数字孪生。
跨模态迁移的关键是“模态对齐”,得找到不同模态数据之间的“对应关系”,比如红外图像的某个像素区域,对应炉内的哪个位置的温度,2026年,通用电气(GE)在燃气轮机数字孪生项目里,也用了类似思路:他们把振动传感器数据(时序数据)和叶片的红外热像图(图像数据)做跨模态迁移,通过深度学习模型自动学习振动特征和温度分布的关联,结果能提前30天预测叶片裂纹,比传统方法(靠定期检修发现)提前了2个月,维护成本降低了40%。 2026年健身运动与时尚潮流及社会企业热度持续上升,相关产业迎来新发展
迁移学习的“坑”:别让“经验”变成“偏见”
说了这么多迁移学习的好处,也得聊聊它的“坑”,最容易踩的坑是“负迁移”——源领域的知识非但没帮上忙,反而干扰了目标领域的学习,比如某企业把A工厂的数字孪生模型直接搬到B工厂,结果因为两厂设备老化程度不同、原料质量有差异,模型预测误差反而比不用迁移学习还高,2026年,《工业人工智能》杂志报道了个典型案例:某化工企业把