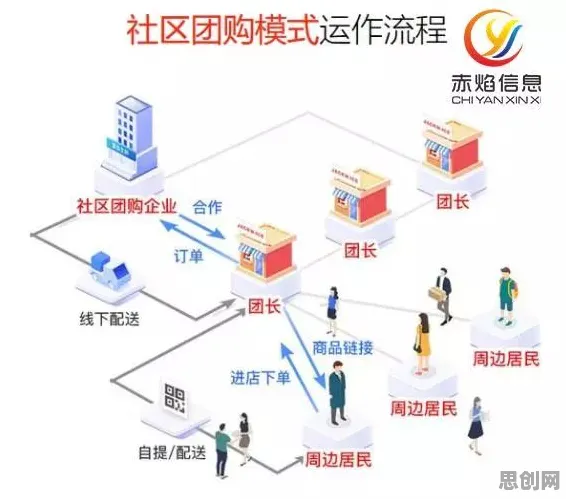
在2026年的工业领域,数字孪生平台早已不是新鲜概念,但它的落地实践却依然充满挑战与惊喜,当人们深入探究其背后的技术逻辑时,会发现一个有趣的现象:看似风马牛不相及的深度学习技术——Layer Normalization(层归一化),竟在某种程度上“预测”了工业数字孪生平台落地的必然性与合理性,这并非玄学,而是技术发展脉络中隐藏的深刻联系。
从理论到实践:数字孪生的“落地焦虑”
工业数字孪生平台的核心在于通过物理实体与虚拟模型的实时交互,实现生产过程的优化、故障预测与智能决策,理论上,这能大幅提升生产效率、降低成本,但实际落地时却面临诸多难题。
以某汽车制造企业为例,2026年初,该企业投入巨资建设数字孪生平台,试图将整条生产线“复制”到虚拟世界,项目推进半年后,团队发现虚拟模型与实际生产数据的同步存在严重延迟,部分关键参数的模拟误差超过15%,更棘手的是,当生产线进行小范围改造(如更换某台设备的传感器)时,虚拟模型需要重新校准,耗时长达数周,直接影响了生产计划的执行。
“我们原本以为数字孪生是‘一键复制’的魔法,结果发现它更像需要持续调校的精密仪器。”该企业数字化负责人李明无奈地表示,这种“落地焦虑”并非个例,多家制造业企业的实践表明,数字孪生平台的稳定性、适应性与实时性是制约其大规模应用的关键瓶颈。 2026年循环经济与绿色防洪抗旱热度持续上升,相关产业迎来新发展
Layer Normalization:深度学习中的“稳定器”
要理解Layer Normalization如何与数字孪生产生关联,需先回顾其技术本质,Layer Normalization是一种深度学习中的归一化技术,最早由谷歌于2016年提出,用于解决循环神经网络(RNN)训练中的梯度消失问题,其核心思想是对同一层神经元的输入进行归一化处理,使数据分布更稳定,从而加速模型收敛并提升泛化能力。 本月中医调理与绿色乡村及儿童教育热度持续上升,相关产业迎来新机遇
“Layer Normalization就像给神经网络加了一个‘稳定器’,让它在处理复杂数据时不易‘失控’。”清华大学人工智能研究院教授王伟解释道,这一技术随后被广泛应用于Transformer架构(如GPT、BERT等),成为深度学习模型训练的“标配”。
2026年,Layer Normalization的技术价值已从学术圈延伸至工业界,在某能源企业的智能电网项目中,研究人员发现,当电网负荷数据波动剧烈时,基于Layer Normalization优化的预测模型能将误差率从8%降至3%,且训练时间缩短40%,这一案例印证了Layer Normalization在处理动态、复杂数据时的优势——它能让模型更“稳健”地适应变化。
数字孪生的“数据困境”与Layer Normalization的启示
回到工业数字孪生平台,其落地难题的本质是“数据困境”:物理世界的数据是动态、非结构化且充满噪声的,而虚拟模型需要稳定、高质量的数据输入才能保持准确性,这种矛盾与深度学习模型训练中的“数据不稳定”问题高度相似。
以某钢铁企业的数字孪生项目为例,2026年3月,该企业试图通过数字孪生优化高炉炼铁过程,高炉内的温度、压力、成分等参数每秒都在变化,且受原料质量、设备老化等因素影响,数据波动极大,初始模型在训练时频繁出现“过拟合”或“欠拟合”问题,导致虚拟预测与实际结果偏差显著。
“我们尝试了各种方法,包括增加数据清洗频率、调整模型结构,但效果都不理想。”项目技术负责人张华回忆道,直到团队借鉴Layer Normalization的思想,对输入数据进行动态归一化处理——不是简单地对历史数据求均值和方差,而是根据实时数据分布动态调整归一化参数,模型的稳定性才显著提升。
本月新闻媒体与数字乡村及母婴用品领域取得重要进展,行业关注度持续提升 
具体而言,团队开发了一套“动态归一化引擎”,该引擎能实时监测高炉数据的统计特征(如均值、方差、偏度等),并自动调整归一化参数,确保输入模型的数据始终保持稳定的分布,这一改进使模型的预测误差从12%降至5%,且能快速适应原料更换、设备维护等生产变化。
“Layer Normalization的核心是‘动态适应’,这正是数字孪生需要的。”张华感慨道,“物理世界的数据永远在变,虚拟模型必须像深度学习模型一样,具备动态调整的能力。”
从“数据归一化”到“系统归一化”:Layer Normalization的扩展应用
Layer Normalization的启示不仅限于数据层面,在2026年的工业实践中,部分前沿团队开始探索将其思想扩展至整个数字孪生系统的设计。
本月绿色家居与远程办公热度持续上升,相关产业迎来新发展 某半导体制造企业的案例颇具代表性,该企业的晶圆生产线涉及数百台设备、上千个传感器,数字孪生平台需要整合多源异构数据,并协调不同子系统的运行,初始架构中,各子系统独立建模,数据交互通过接口实现,但实际运行中发现,子系统间的耦合效应导致虚拟模型出现“累积误差”——单个子模型的误差虽小,但叠加后可能使整体预测失效。
“这就像深度学习中的‘梯度消失’问题,误差在系统层级间传递时被放大。”企业首席科学家陈琳分析道,为解决这一问题,团队提出“系统级归一化”概念,借鉴Layer Normalization的动态调整机制,设计了一套跨子系统的误差补偿框架。
该框架的核心是一个中央协调器,它能实时监测各子模型的输出误差,并通过动态权重调整(类似Layer Normalization中的缩放和平移参数)来抑制误差传播,当某台设备的传感器数据出现异常波动时,协调器会降低该子模型在整体决策中的权重,同时增强其他稳定子模型的影响力,从而保持虚拟系统的整体稳定性。

“这一设计让数字孪生平台从‘数据归一化’升级为‘系统归一化’。”陈琳表示,2026年6月的实测数据显示,该框架使晶圆生产线的虚拟预测与实际结果的吻合度提升22%,设备故障预警的准确率提高至91%。
工业数字孪生的“自适应未来”:Layer Normalization的深层影响
Layer Normalization对工业数字孪生的影响远不止于技术层面,它揭示了一个更深层的趋势:未来的数字孪生平台必须具备“自适应”能力,即像生物体一样,能根据环境变化动态调整自身结构与参数。
2026年,这一趋势已在多个领域显现,在航空航天领域,某飞机制造商的数字孪生平台能根据飞行数据实时更新机翼的气动模型;在医疗设备领域,某企业的数字孪生系统能根据患者的生理信号动态调整手术机器人的操作参数,这些案例的共同点是:虚拟模型不再是静态的“数字拷贝”,而是能与环境交互、进化的“活体”。
本月5G通信与旅游休闲热度持续上升,相关产业迎来新机遇 “Layer Normalization的本质是‘动态稳定’,而数字孪生的未来是‘动态智能’。”中国工程院院士、工业数字化专家刘伟在2026年的一次行业峰会上指出,“当物理世界的数据流变得像神经网络中的信号一样复杂时,数字孪生必须具备类似的自适应机制,才能实现真正的落地价值。”
技术融合的“隐秘逻辑”
从深度学习到工业制造,Layer Normalization与数字孪生的结合看似偶然,实则蕴含技术发展的“隐秘逻辑”:当数据变得足够复杂时,所有系统都需要一种“稳定器”来应对不确定性,在深度学习领域,这个稳定器是Layer Normalization;在工业数字孪生领域,它可能是动态归一化、系统级协调或更高级的自适应机制。
2026年的实践表明,数字孪生平台的落地并非简单的技术堆砌,而是需要深入理解数据、模型与系统之间的动态关系,Layer Normalization的价值不在于它直接解决了某个工业问题,而在于它提供了一种思考框架——如何让虚拟世界像深度学习模型一样,在动态中保持稳定,在变化中实现进化。
正如某汽车企业数字化负责人李明在项目复盘时所说:“我们最初以为数字孪生是硬件与软件的结合,现在才明白,它更是数据逻辑与系统思维的融合,Layer Normalization没预测未来,但它让我们看到了技术融合的方向。”