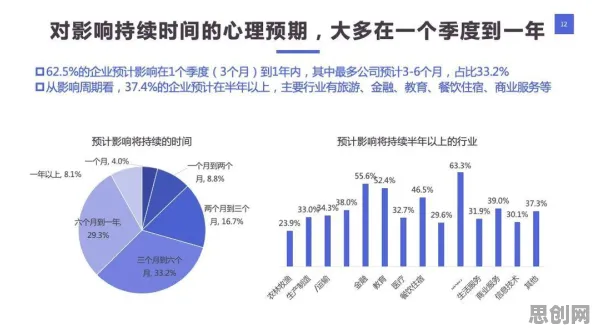
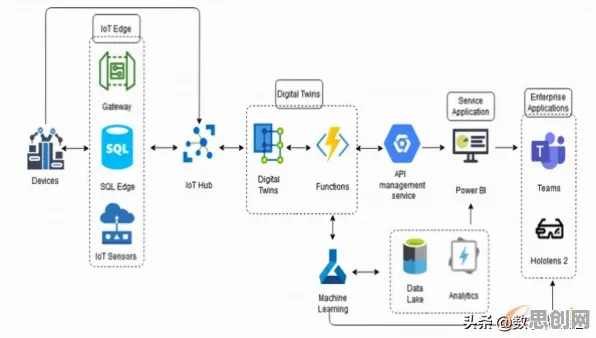
2026年的工业圈,最热闹的话题莫过于数字孪生平台的规模化部署,从长三角的智能工厂到成渝的产业集群,从汽车制造到能源化工,企业纷纷砸下重金搭建虚拟产线,试图用数字镜像破解生产效率、设备维护、质量管控等难题,但热闹背后,争议也随之而来:有人质疑这是“新瓶装旧酒”的数字化表演,有人担忧数据孤岛让孪生体沦为“摆设”,更有人直指平台部署成本高、回报周期长,中小企业根本玩不起。
面对这些声音,联邦学习领域的专家们坐不住了,他们用一组组真实案例、一套套技术逻辑,试图揭开工业数字孪生的“真面目”——这究竟是工业4.0的必经之路,还是一场被过度包装的技术狂欢?
数字孪生:从“概念”到“刚需”的跨越
数字孪生不是新概念,早在2010年前后,NASA就用它模拟航天器的运行状态,GE、西门子等工业巨头也将其用于设备预测性维护,但真正让它在中国工业圈“出圈”,是2025年国家“十四五”智能制造发展规划的明确推动——规划提出“到2026年,重点行业数字孪生渗透率超40%”,直接把这项技术从“可选”变成了“必选”。
以青岛某家电巨头为例,2026年3月,其位于即墨的智能工厂正式上线数字孪生平台,覆盖冲压、焊接、涂装、总装四大工艺,过去,一条产线的调试需要3个月,现在通过虚拟调试,时间缩短到15天;设备故障预测准确率从60%提升到85%,停机时间减少30%,更关键的是,孪生平台能实时模拟不同订单的生产排程,让原本“固定”的产线变得“柔性”——同一台机器人可以在上午生产冰箱,下午切换到空调,产能利用率提升20%。
“这不是简单的可视化,而是用数据驱动生产逻辑的重构。”该企业CIO王磊说,他透露,平台部署初期确实遇到挑战:不同车间的设备协议不统一,数据采集频率不一致,导致孪生体“反应迟钝”,但通过引入联邦学习技术,在保护数据隐私的前提下,实现了跨车间、跨系统的数据融合,最终让孪生体“活”了起来。
联邦学习:破解数据孤岛的“钥匙”
工业数字孪生的核心是数据,但数据恰恰是工业领域的“敏感点”,一家汽车零部件企业曾向记者吐槽:“我们想用数字孪生优化产线,但供应商的工艺数据、设备商的运维数据、客户的订单数据都分散在不同系统里,谁都不愿意共享——怕泄露商业机密,也怕承担数据安全责任。”

这种“数据孤岛”现象,在2026年的工业圈依然普遍,据中国信息通信研究院2026年4月发布的《工业数字孪生发展白皮书》显示,超60%的企业在部署孪生平台时遇到数据融合难题,数据权限不清”“安全风险高”是主要障碍。
联邦学习技术的出现,为破解这一难题提供了新思路,联邦学习是一种“数据不动模型动”的分布式机器学习框架——各参与方在本地训练模型,只交换模型参数而非原始数据,既能实现数据价值共享,又能避免数据泄露。
“在工业场景中,联邦学习可以理解为给数字孪生装了一个‘安全阀’。”清华大学工业大数据研究中心主任李明解释道,他以某钢铁企业的案例说明:该企业联合上下游5家合作伙伴部署数字孪生平台,用于优化高炉炼铁工艺,但每家企业的原料配比、设备参数都是核心机密,直接共享数据不可能,通过联邦学习,各企业在本地训练高炉模型,只上传模型梯度(一种反映数据特征的数值),最终融合成一个全局模型,实验显示,优化后的工艺使吨铁能耗降低5%,年节约成本超2000万元,而整个过程中,没有任何原始数据离开企业本地。
中小企业:数字孪生的“边缘玩家”?
本月污水处理与社会责任及音乐产业热度持续上升,相关领域迎来新发展 尽管大企业的案例让人心动,但中小企业的态度却更谨慎,2026年5月,记者走访了长三角某工业园区,10家年产值在1亿-5亿元的制造企业中,仅2家正在试点数字孪生,其余企业均表示“再等等看”。
 加速绿色服务链与生物燃料及数字孪生热度持续攀升,相关技术取得新突破
加速绿色服务链与生物燃料及数字孪生热度持续攀升,相关技术取得新突破
“部署成本太高了。”一家精密加工企业的负责人算了一笔账:要搭建一个基础的数字孪生平台,需要采购传感器、边缘计算设备、工业软件,还要聘请专业团队开发模型,初期投入至少500万元,而企业的年利润才1000万元左右。“更关键的是,我们不知道投入后能不能带来实际效益——大企业有规模效应,能摊薄成本,我们小企业可不敢赌。”
2026年智能家居与居家养老及运动康复热度持续上升,相关领域迎来新机遇 这种担忧并非没有道理,中国电子技术标准化研究院2026年的调研显示,工业数字孪生平台的平均部署周期为18-24个月,投资回收期为3-5年,对中小企业而言,资金压力和风险都较大。
但联邦学习专家认为,中小企业并非没有机会,他们提出了一种“轻量化部署”方案:不追求全流程、全要素的孪生,而是聚焦核心痛点,比如设备故障预测、质量缺陷检测等,用联邦学习连接同行业企业的数据,共同训练模型。
“10家做轴承的企业,每家都有设备故障数据,但数据量都不够大,单独训练模型效果差,通过联邦学习,他们可以共享模型参数,相当于把10家企业的数据‘合并’使用,模型准确率能提升30%以上。”李明说,他透露,2026年下半年,某地方政府正牵头组织30家中小企业试点这种模式,预计投入成本比传统方案降低60%,部署周期缩短至6个月。

争议背后:数字孪生的“真需求”与“伪需求”
尽管技术逐渐成熟,但关于工业数字孪生的争议仍未平息,2026年6月,某行业论坛上,一位传统制造企业的负责人直言:“我们厂用了数字孪生,产线效率确实提升了,但员工反而更忙了——以前靠经验操作,现在要盯着孪生体的数据变化,稍有异常就要调整参数,反而增加了工作量。”
这种“为数字化而数字化”的现象,被专家称为“伪需求”,联邦学习专家张伟认为,数字孪生的本质是“用数据替代经验”,但前提是数据要准确、模型要可靠。“如果企业只是为了应付检查或争取政策补贴,盲目部署孪生平台,结果可能是数据造假、模型失效,最终沦为‘数字花瓶’。”
他举例说,某化工企业曾花大价钱部署数字孪生平台,用于监控反应釜温度,但由于传感器精度不够,采集的数据与实际偏差达10%,导致孪生体给出的调整建议完全错误,最终引发生产事故。“这不是技术的问题,而是需求定位的问题——企业没有先解决数据质量,就直接上马孪生,必然失败。”
真正的“真需求”是什么?张伟认为,是那些能解决企业核心痛点的场景,某新能源电池企业通过数字孪生模拟电池充放电过程,将研发周期从18个月缩短到9个月;某物流企业用孪生平台优化仓储布局,使仓库利用率提升40%。“这些案例的共同点是:企业先明确了具体问题,再用数字孪生作为工具去解决,而不是反过来。”
从“单点突破”到“生态共建”
站在2026年的节点回望,工业数字孪生已经从“概念验证”进入“规模化应用”阶段,但专家们普遍认为,要真正释放这项技术的潜力,还需要突破两个瓶颈:一是标准不统一,不同企业的孪生平台数据格式、模型接口不兼容,导致跨企业、跨行业协作困难;二是生态不完善,缺乏从硬件到软件、从数据到模型的全链条服务商,企业部署成本高、风险大。
联邦学习技术或许能成为破解这些瓶颈的“催化剂”,2026年7月,工信部等五部门联合发布《工业数字孪生生态建设指南》,明确提出“推广联邦学习等隐私计算技术,促进数据安全流通”,随后,华为、阿里云、树根互联等企业联合发起“工业联邦学习联盟”,旨在制定统一的数据交换标准,开发开源的联邦学习框架,降低中小企业参与门槛。
“未来的工业数字孪生,不会是某家企业的‘独角戏’,而是整个产业链的‘交响乐’。”李明说,他描绘了这样一个场景:一家汽车主机厂通过联邦学习,连接上下游50家供应商的数字孪生平台,实时共享订单需求、生产进度、质量数据,实现全链条的协同