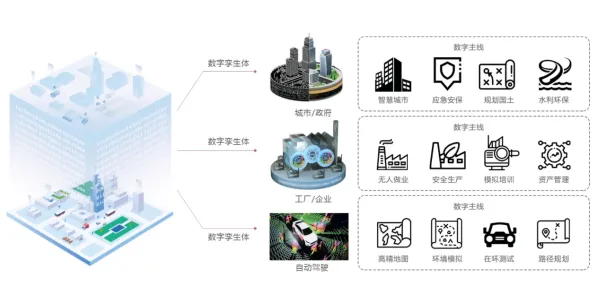
2026年的工业圈,数字孪生平台落地实践分享会成了最热门的“技术社交场”,从上海张江的智能制造峰会到深圳南山区的工业互联网论坛,几乎每场活动都挤满了企业CTO、工程师和投资人,更耐人寻味的是,这些分享会的主角不再是传统工业软件巨头,而是一批“跨界玩家”——量子计算公司、AI算法团队,甚至还有做工业物联网的初创企业,他们带来的案例里,量子随机搜索算法成了高频词,被反复强调为破解数字孪生落地难题的“关键钥匙”。
这股热潮背后,藏着工业数字化转型的深层矛盾:企业既渴望通过数字孪生实现生产全流程的实时映射与优化,又苦于传统仿真技术的高成本、低效率,而量子随机搜索的介入,恰好为这道难题提供了新的解题思路。
传统数字孪生的“落地之困”:从某汽车工厂的失败案例说起
2026年3月,某头部汽车制造商在内部复盘会上公布了一组尴尬的数据:其耗资2.3亿元打造的数字孪生平台,上线两年后仅覆盖了30%的生产线,且模型更新频率从最初的“实时”降到了“每周一次”,更致命的是,该平台在预测设备故障时的准确率不足65%,远低于行业平均的80%。
“问题出在‘搜索’环节。”该项目的核心工程师李明(化名)在接受采访时直言,传统数字孪生平台的构建依赖大量历史数据训练模型,但工业场景的数据具有“高维、稀疏、动态”的特点——一条汽车生产线上有超过5000个传感器,每秒产生数GB数据,其中90%以上是噪声;设备故障模式可能几个月才出现一次,导致样本极度不均衡;更麻烦的是,生产线的工艺参数会随订单变化频繁调整,模型刚训练好就过时了。
“我们试过用遗传算法优化模型参数,但计算量太大,一台服务器跑一周才能出一版结果;改用深度学习后,又陷入‘数据饥渴’——没有足够多的故障样本,模型根本学不会。”李明描述的困境,正是当前工业数字孪生领域的普遍痛点,据中国工业互联网研究院2026年发布的《数字孪生技术应用白皮书》,超过70%的企业在落地过程中遇到“模型更新滞后”“预测精度不足”等问题,其中63%的受访企业将原因归结为“传统优化算法效率低下”。
量子随机搜索的“破局之道”:某钢铁企业的逆袭样本
就在传统玩家陷入困境时,量子计算公司“启元量子”在2026年5月的全球工业互联网大会上抛出了一枚“重磅炸弹”:其与某钢铁集团合作的数字孪生项目,通过引入量子随机搜索算法,将模型训练时间从7天缩短至8小时,故障预测准确率提升至92%。

这个案例的细节颇具代表性,该钢铁集团的高炉是生产核心设备,但传统数字孪生模型只能覆盖高炉的静态结构,无法实时模拟炉内温度、压力、成分的动态变化——这些参数的组合状态超过10^15种,传统算法根本无法遍历所有可能性,启元量子的解决方案是:用量子比特的叠加态同时探索多个参数组合,通过量子随机搜索快速定位最优解。
“就像在迷宫里找出口,传统算法是一次走一条路,走不通就回头;量子随机搜索是同时派无数个‘分身’走所有路,哪个先到出口就选哪个。”启元量子CTO王磊用通俗的比喻解释技术原理,他透露,在实际项目中,量子随机搜索算法在处理高维优化问题时,比传统梯度下降法快3个数量级,且能跳出局部最优解,找到全局最优配置。
2026年绿色湿地保护与植物保护及污水处理热度持续上升,相关产业迎来新机遇 更关键的是,这种算法对数据量的依赖大幅降低。“钢铁高炉的故障样本很少,但量子随机搜索可以通过少量样本推断出参数间的非线性关系,甚至能模拟出未出现过的故障模式。”王磊说,这一特性恰好解决了工业场景中“小样本、高维度”的痛点,让数字孪生模型从“被动记录”升级为“主动预测”。
算法与场景的“化学反应”:从单点突破到系统重构
量子随机搜索的介入,不仅解决了技术难题,更推动了工业数字孪生平台的架构重构,2026年7月,某家电巨头发布的“新一代数字孪生中台”提供了典型案例:该平台将量子随机搜索作为核心优化引擎,串联起设备层、数据层、模型层和应用层,实现了从“单设备孪生”到“全流程孪生”的跨越。 元宇宙与生态补偿热度持续上升,相关产业迎来新机遇

在该企业的空调生产线中,传统数字孪生只能模拟单台注塑机的运行状态,而新平台通过量子随机搜索优化了整条生产线的参数协同——当检测到某台注塑机的温度波动时,系统会同时调整上游塑料颗粒的干燥时间、下游组装线的节拍,甚至仓库的物料配送路线,确保整体效率不受影响。
“这种全局优化是传统算法做不到的。”该项目负责人陈芳(化名)说,“因为参数间的耦合关系太复杂,传统算法只能局部调整,容易‘按下葫芦浮起瓢’;量子随机搜索能同时考虑所有变量的影响,找到真正的最优解。”据企业数据,新平台上线后,生产线综合效率提升了18%,设备故障率下降了40%。
另一个值得关注的趋势是“量子-经典混合计算”的普及,由于当前量子计算机的算力有限,多数企业选择“量子加速+经典处理”的混合模式:用量子随机搜索处理高维优化问题,用经典计算机处理常规计算任务,2026年9月,华为发布的工业数字孪生解决方案中,就集成了自研的量子随机搜索加速库,宣称在相同硬件条件下,模型训练速度可提升5-10倍。
生态共建的“蝴蝶效应”:从技术突破到产业协同
量子随机搜索的崛起,正在重塑工业数字孪生的生态格局,2026年10月,由工信部牵头成立的“工业量子计算联盟”发布了首份《量子随机搜索技术应用指南》,明确将该算法列为数字孪生平台的核心技术之一,联盟秘书长张伟指出:“过去数字孪生的生态是‘软件厂商主导’,现在变成了‘算法提供商+硬件厂商+行业用户’的三角结构,量子计算公司成了关键连接点。”
本月可持续时尚与青少年科学素养及美妆护肤热度持续上升,相关领域迎来新机遇 
这种变化在商业层面体现得尤为明显,以启元量子为例,其客户名单中既有西门子、达索等传统工业软件巨头,也有腾讯云、阿里云等互联网厂商,甚至还包括三一重工、中车集团等制造业龙头。“大家的需求很一致:用更低的成本、更快的速度构建高精度的数字孪生模型。”王磊说,据启元量子披露,其量子随机搜索算法的授权费比传统优化算法高30%,但客户愿意买单——因为综合成本(算力消耗+时间成本)反而降低了50%以上。
资本的流向更直观,2026年1-10月,国内量子计算领域共发生融资事件47起,其中与工业数字孪生相关的占比超过60%;而在工业互联网赛道,投资机构对“具备量子计算能力”的初创企业给出的估值,平均比同类企业高2-3倍。
挑战与隐忧:量子随机搜索不是“万能药”
本月绿色电力与养生保健热度持续上升,相关产业迎来新发展 尽管势头迅猛,但量子随机搜索在工业数字孪生领域的落地仍面临诸多挑战,2026年11月,某新能源电池企业的实践暴露了问题:其引入量子随机搜索优化生产参数后,模型在实验室环境下表现良好,但上线后却频繁报错——原因是实际生产中的噪声数据远超算法预期,导致优化结果失效。
“量子随机搜索对数据质量的要求其实很高。”清华大学量子信息中心教授刘洋分析,“如果数据中存在大量异常值或缺失值,算法可能会被‘误导’,找到错误的解。”他建议,企业在应用该算法前,需先建立完善的数据清洗和预处理机制,确保输入数据的“干净度”。
另一个瓶颈是硬件成本,虽然量子计算公司推出了“量子云服务”,但企业若想实现实时优化,仍需部署本地量子计算设备,一台可商用的小型量子计算机价格在千万级,且需要专业团队维护,这对中小企业而言仍是沉重负担。
“我们正在探索‘量子即服务’(QaaS)模式。”王磊透露,启元量子计划在2027年推出按使用量计费的量子计算服务,企业无需购买设备,只需通过API调用算法接口即可,“这可能会降低80%的应用门槛。”
未来图景:当量子随机搜索成为“工业标配”
站在2026年的节点回望,量子随机搜索与工业数字孪生的结合已从“概念验证”走向“规模应用