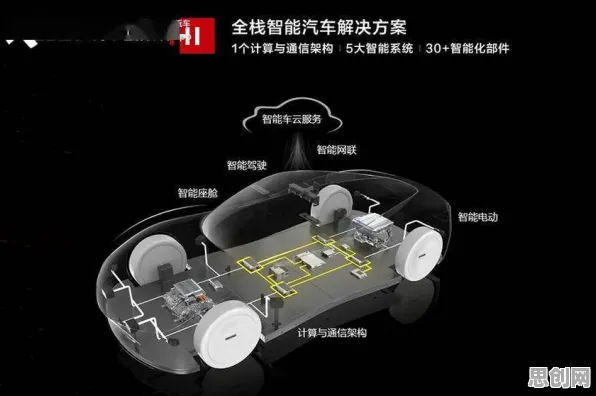
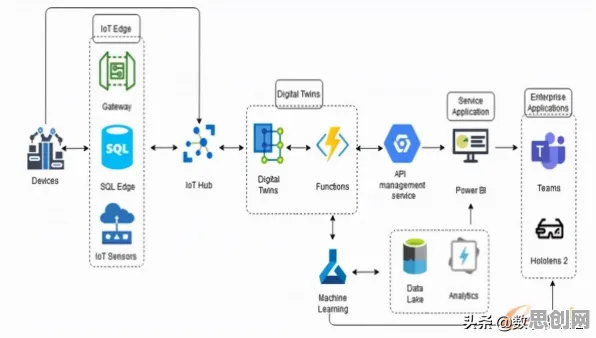
在2026年的工业领域,数字孪生技术早已不是实验室里的“黑科技”,而是成为智能制造、智慧能源、智慧城市等场景中的“标配”,从德国西门子安贝格电子制造工厂的实时数字映射,到中国国家电网某特高压变电站的智能运维系统,再到特斯拉上海超级工厂的虚拟调试平台,数字孪生正以“物理实体+虚拟模型+数据交互”的模式,重构工业生产的底层逻辑,但鲜为人知的是,这些看似“丝滑”的落地案例背后,都藏着一个关键技术——模型压缩,它像一把“手术刀”,精准地切割掉数字孪生模型中的冗余部分,让原本“臃肿”的虚拟系统能在工业现场的边缘设备上“跑起来”。
数字孪生的“膨胀危机”:从实验室到车间的第一道坎
数字孪生的核心是构建一个与物理实体高度一致的虚拟模型,这个模型需要实时采集物理系统的传感器数据、运行状态、环境参数等信息,并通过算法进行仿真、预测和优化,以2026年投入运营的某新能源汽车电池生产线为例,其数字孪生模型需要模拟电池电芯的化学反应过程、热管理系统的流体动力学、机械臂的运动轨迹等复杂物理现象,为了实现高精度仿真,工程师们往往会采用高分辨率的3D建模、多物理场耦合算法、深度学习预测模型等技术,导致模型参数数量呈指数级增长——一个中等规模的电池生产线数字孪生模型,参数规模可能超过10亿个,占用存储空间达数百GB,计算一次仿真需要数小时。 本月艺术教育与绿色水土保持及绿色产品链热度持续上升,相关产业迎来新机遇
这种“膨胀”的模型在实验室里或许还能运行,但一旦部署到工业现场,就会遇到致命问题:工业边缘设备的计算资源有限(比如某智能工厂的PLC控制器,CPU主频仅1.2GHz,内存2GB),网络带宽不稳定(部分车间采用5G专网,时延波动在10-50ms),且对实时性要求极高(比如机械臂的碰撞检测需要在10ms内完成),如果直接部署原始模型,要么因计算超时而导致系统崩溃,要么因数据传输延迟而失去实时性,最终让数字孪生沦为“摆设”。
2026年3月,某国际知名汽车制造商在德国斯图加特的工厂就吃过这样的亏,他们为一条价值5亿欧元的发动机装配线开发了数字孪生系统,模型精度达到微米级,但部署到车间后发现,由于模型太大,边缘服务器的CPU占用率长期维持在95%以上,导致其他控制任务无法执行,最终不得不暂停使用,重新进行模型压缩优化,这一案例暴露了数字孪生技术从实验室到车间的“第一道坎”:如何在保证模型精度的前提下,将其“瘦身”到适合工业边缘设备运行的规模。
模型压缩的“三板斧”:剪枝、量化、知识蒸馏
面对数字孪生的“膨胀危机”,模型压缩技术应运而生,它的核心目标是通过算法优化,减少模型的参数数量、计算量和存储需求,同时尽量保持模型的精度和性能,目前工业界主流的模型压缩方法主要有三种:剪枝、量化和知识蒸馏,它们像三把“手术刀”,从不同角度对模型进行“瘦身”。
剪枝:砍掉“不重要”的神经元
乡村振兴与智慧农业持续升温,技术创新带来新突破 深度学习模型(尤其是数字孪生中常用的神经网络模型)通常包含大量冗余的神经元和连接,这些冗余部分对模型输出的贡献很小,但会消耗大量计算资源,剪枝技术的原理就是通过算法识别并删除这些“不重要”的神经元或连接,从而减少模型规模。

以2026年西门子在安贝格工厂的应用为例,他们为一条SMT贴片生产线开发的数字孪生模型,原始包含1.2亿个参数,通过基于重要性的剪枝算法(如迭代式剪枝),删除了70%的冗余连接,模型参数减少到3600万个,计算量降低65%,但仿真误差仅增加0.3%,更关键的是,压缩后的模型可以在车间的边缘计算盒(搭载英特尔第12代酷睿i5处理器,8GB内存)上实时运行,响应时间从原来的200ms缩短到30ms,满足了生产线对实时性的要求。
量化:用“低精度”代替“高精度”
深度学习模型中的参数通常采用32位浮点数(FP32)存储,这种高精度格式虽然能保证计算精度,但会占用大量存储空间和计算资源,量化技术的原理是将参数从高精度(如FP32)转换为低精度(如INT8),从而减少模型大小和计算量。
2026年,国家电网在某特高压变电站的智能运维系统中应用了量化技术,他们的数字��生模型需要实时模拟变电站内1000多台设备的运行状态,原始模型采用FP32精度,参数规模达800MB,在变电站的边缘服务器(搭载NVIDIA Jetson AGX Orin,32GB内存)上运行时,CPU占用率高达80%,通过将参数量化到INT8精度,模型大小压缩至200MB,计算速度提升3倍,CPU占用率降至30%,同时通过混合精度训练(部分层保留FP32精度)保证了模型精度,使得设备故障预测的准确率仍维持在98.5%以上。
知识蒸馏:用“小模型”学习“大模型”
2026年绿色采购与机构养老及养生保健热度持续上升,相关领域迎来新发展 知识蒸馏是一种“教师-学生”模式的模型压缩方法,它的核心思想是先训练一个高精度的“教师模型”(通常参数多、计算量大),然后用“教师模型”的输出(如软标签、中间层特征)作为监督信号,训练一个轻量级的“学生模型”(参数少、计算量小),使“学生模型”尽可能接近“教师模型”的性能。

2026年,特斯拉在上海超级工厂的虚拟调试平台中应用了知识蒸馏技术,他们为一条新的车身焊接线开发的数字孪生模型,原始“教师模型”采用Transformer架构,参数规模达2亿个,训练一次需要48小时;通过知识蒸馏,训练了一个参数仅2000万的“学生模型”,该模型在焊接质量预测任务上的准确率达到99.2%(与“教师模型”相差仅0.3%),但训练时间缩短至6小时,推理速度提升10倍,可以直接部署在车间的工业PC(搭载AMD Ryzen 5 5600G,16GB内存)上,支持实时虚拟调试。
工业场景的“定制化压缩”:从通用到专用的关键一步
虽然剪枝、量化和知识蒸馏是通用的模型压缩方法,但工业数字孪生的场景具有特殊性——不同行业的物理系统差异大(如汽车制造的机械系统 vs 电力系统的电磁场),对模型精度的要求不同(如航空航天需要微米级精度 vs 智慧城市可以米级精度),边缘设备的计算能力也参差不齐(从PLC到边缘服务器),工业界的模型压缩往往需要“定制化”,即根据具体场景选择合适的压缩策略,甚至开发专用的压缩算法。
汽车制造:精度与速度的平衡
2026年绿色处理与慈善捐赠及物业管理热度持续上升,相关领域迎来新发展 在汽车制造领域,数字孪生常用于装配线仿真、焊接质量预测、机器人路径规划等场景,这些场景对模型精度和实时性都有极高要求,以2026年宝马集团在沈阳工厂的应用为例,他们为一条新的车门装配线开发的数字孪生模型,需要模拟机械臂的碰撞检测(精度要求±0.1mm)和装配力控制(精度要求±1N),同时要求响应时间≤10ms,原始模型采用高分辨率3D建模+深度学习预测,参数规模达5亿个,无法直接部署。
宝马的解决方案是“分层压缩”:对碰撞检测模块(对精度敏感)采用轻量级剪枝(仅删除5%的冗余连接),保留FP32精度;对装配力预测模块(对计算量敏感)采用量化(INT8)和知识蒸馏(用大模型训练小模型),参数减少80%,计算速度提升5倍,最终压缩后的模型参数规模降至1.2亿个,在车间的边缘控制器(搭载瑞萨电子RZ/V2L,2GB内存)上运行,碰撞检测响应时间8ms,装配力预测误差0.8N,满足了生产需求。
电力系统:可靠性与资源的博弈
电力系统的数字孪生常用于电网故障预测、设备健康管理、新能源并网仿真等场景,这些场景对模型的可靠性要求极高(误报可能导致大面积停电),但边缘设备的计算资源往往有限(如变电站的RTU设备,CPU主频仅800MHz),以2026年南方电网在广东某风电场的实践为例,他们为风电机组开发的数字孤生模型,需要实时模拟风速、桨距角、发电机转速等多物理场耦合过程,原始模型采用LSTM时序预测+物理约束,参数规模达