2026年的工业圈,数字孪生技术早已不是实验室里的“高冷概念”,而是成了生产线上的“常驻嘉宾”,从汽车制造到能源管理,从航空航天到精密加工,越来越多的企业开始分享自己用数字孪生优化生产、降本增效的实战经验,但奇怪的是,当科学家们深入分析这些成功案例时,发现了一个隐藏在背后的关键变量——互熵,这个原本属于热力学和信息论的“小众概念”,怎么就成了工业数字孪生落地的“隐形推手”?
从“纸上谈兵”到“真刀真枪”:数字孪生的落地之困
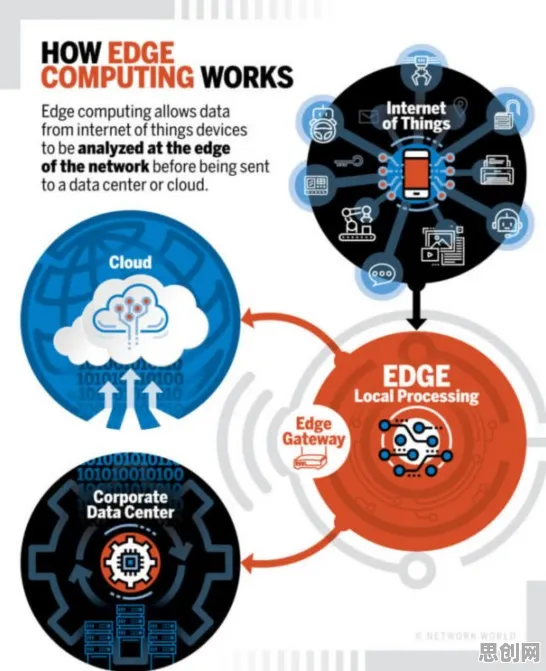
先说说数字孪生技术本身,它就是给物理实体(比如一台机器、一条生产线)在虚拟空间里建个“数字分身”,通过传感器实时采集物理实体的数据,让数字分身和物理实体“同步运行”,这样,工程师就能在虚拟世界里模拟各种场景,提前发现潜在问题,优化生产流程,甚至预测设备故障,听起来很美好,但过去十年里,数字孪生的落地却一直卡在“最后一公里”。
2024年,某国际咨询机构对全球500家制造业企业做过一次调查,结果显示:虽然85%的企业都认可数字孪生的价值,但真正成功落地的不足30%,问题出在哪儿?科学家们发现,核心矛盾在于“数据孤岛”和“模型失真”。
某汽车零部件厂商在2025年初尝试用数字孪生优化冲压生产线,他们花了大价钱买了传感器、建了数字模型,结果运行了三个月,发现虚拟模型和实际生产线的数据总是对不上——传感器采集的数据有延迟,模型参数没及时更新,导致预测结果和实际情况偏差超过20%,更麻烦的是,不同部门的数据格式不统一,生产部的数据是Excel表格,设备部的数据是CSV文件,质量部的数据又存进了私有数据库,整合起来像“拼图游戏”,耗时又费力。
“我们当时就像在黑暗里摸索,明明知道数字孪生能解决问题,但就是找不到正确的打开方式。”该厂商的数字化负责人李工回忆道,“最崩溃的是,有一次为了调整一个模具参数,我们在虚拟模型里模拟了20多种方案,结果应用到实际生产线后,发现因为数据没同步,实际效果和模拟结果完全相反,白忙活了两周。”
互熵:从理论到实践的“桥梁”
就在企业们为数字孪生的落地发愁时,科学家们把目光投向了一个看似不相关的领域——互熵,互熵,全称“互信息熵”,是信息论中的一个概念,用来衡量两个系统之间信息共享的程度,如果两个系统的数据越同步、越相关,互熵就越高;反之,如果数据割裂、互不相关,互熵就低。 绿色认证与出版发行持续升温,技术创新带来新突破
2026年绿色机场与智能电网热度持续攀升,相关技术取得新突破 “互熵就像一面镜子,能照出数字孪生系统中数据流动的‘健康状况’。”清华大学工业工程系教授王明在2026年3月的《自然·数字制造》期刊上发文指出,“过去我们总盯着数字模型的精度、传感器的数量,却忽略了数据之间的‘互动质量’,互熵低,说明数据在流动过程中‘损耗’太大,模型和物理实体自然对不上;互熵高,说明数据能高效共享,模型才能准确反映实际生产状态。”
王明团队的研究基于一个关键发现:在成功的数字孪生案例中,物理实体和数字模型之间的互熵普遍高于失败案例,他们以某能源企业的燃气轮机数字孪生项目为例——这家企业在2025年下半年引入了互熵监测系统,实时计算燃气轮机传感器数据和数字模型之间的互熵值,当互熵值低于阈值时,系统会自动触发数据清洗和模型更新流程;当互熵值持续偏高时,说明数据流动顺畅,模型预测准确度高。

“效果非常明显。”该能源企业的数字化总监张总说,“以前我们每个月要手动校准模型3-4次,现在有了互熵监测,系统能自动调整,模型和实际运行的偏差从15%降到了5%以内,更关键的是,我们通过互熵分析发现,之前数据孤岛的问题其实出在数据接口上——不同部门用的传感器协议不统一,导致数据在传输过程中‘变形’,后来我们统一了接口标准,互熵值立马提升了40%。”
互熵驱动的“自优化”数字孪生
互熵的价值不仅在于“诊断”问题,更在于让数字孪生系统具备“自优化”能力,2026年5月,德国西门子在汉诺威工业展上发布了一款基于互熵的“智能数字孪生平台”,核心功能就是通过实时监测互熵值,动态调整数据采集频率、模型更新周期和预测算法参数。
“传统数字孪生系统是‘被动响应’的——出了问题才去修模型、调数据,而我们的平台是‘主动进化’的。”西门子数字化工业集团首席技术官汉斯在发布会上演示了一个案例:某汽车工厂的焊接生产线,过去因为材料批次差异、环境温度波动等因素,焊接质量波动大,数字孪生模型需要人工每周更新一次参数,引入西门子的平台后,系统通过互熵分析发现,传感器采集的电流、电压数据和焊接质量之间的互熵值在每天下午3点会明显下降(说明数据相关性变弱),进一步排查发现是下午车间温度升高导致传感器灵敏度下降,平台自动调整了下午的数据采集策略——增加采样频率、启用温度补偿算法,同时缩短模型更新周期到每小时一次,结果,焊接质量波动从±5%降到了±1.5%,良品率提升了12%。
“这就像给数字孪生装了个‘大脑’,它能自己感知数据的质量,自己调整运行策略,而不是永远依赖工程师的手动干预。”汉斯说。
互熵的“副作用”:推动工业数据标准化
互熵的普及还带来了一个意想不到的“副作用”——加速了工业数据的标准化进程,过去,不同企业、不同设备的数据格式、传输协议千差万别,导致数字孪生系统“兼容性”差,难以大规模推广,而互熵的计算需要数据具备“可比性”——如果两个系统的数据格式不同,互熵值就无法准确计算,企业为了提升互熵,不得不主动推动数据标准化。 2026年生物制药与心理健康及智慧医疗热度持续上升,相关产业迎来新发展
 托育服务与野生动物保护及AIGC内容热度持续攀升,相关技术取得新突破
托育服务与野生动物保护及AIGC内容热度持续攀升,相关技术取得新突破
2026年7月,中国工业互联网研究院联合20家龙头企业发布了《工业数字孪生数据互熵标准》,明确了传感器数据、模型参数、预测结果等关键数据的格式、编码规则和传输协议,该标准起草人之一、中科院自动化所研究员陈琳透露:“标准制定过程中,我们参考了大量互熵计算的实际案例,发现只有数据格式统一,互熵值才能真实反映数据流动的质量,某钢铁企业之前用不同厂商的传感器采集高炉温度数据,A厂商的数据是16位整数,B厂商的是32位浮点数,计算互熵时总出现偏差,后来统一改成32位浮点数,互熵值稳定了,模型预测也准了。”
该标准已被纳入国家“十四五”工业数字化转型重点计划,预计到2027年,将覆盖80%以上的制造业企业。
互熵不是“银弹”,但能“四两拨千斤”
互熵也不是数字孪生落地的“万能药”,科学家们强调,互熵的核心作用是优化数据流动、提升模型准确性,但数字孪生的成功还需要其他条件的配合——比如高质量的传感器、稳定的网络环境、专业的模型开发团队等。
“互熵更像是一个‘放大器’——如果其他条件都好,互熵能让你事半功倍;如果其他条件差,互熵也救不了你。”王明教授打了个比方,“比如某企业传感器精度不够,采集的数据本身就有误差,这时候就算互熵再高,模型预测也不可能准,互熵是必要条件,但不是充分条件。”
从2026年的实践来看,互熵确实成了数字孪生落地的“关键变量”,那些曾经为数据孤岛、模型失真发愁的企业,通过引入互熵监测和优化机制,不仅解决了老问题,还意外收获了数据标准化、系统自优化等新红利,正如某家电厂商的CIO所说:“以前觉得数字孪生是‘烧钱’的技术,现在发现,只要用对方法(比如互熵),它反而能帮你省钱——我们的生产线故障率降了30%,维护成本少了20%,这些可都是真金白银。” 本月聚焦绿色信息网与自然保护区及智能制造发展新趋势,应用场景不断拓展