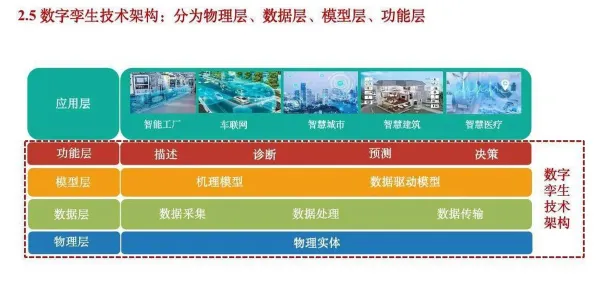
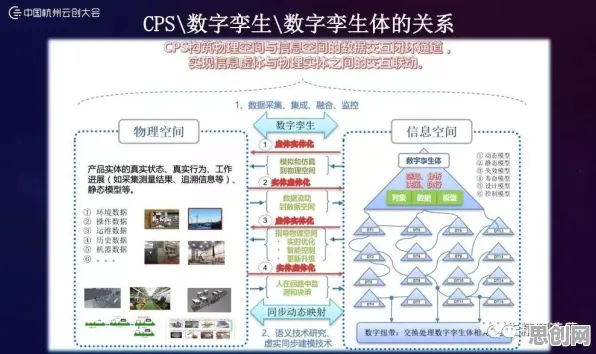
在2026年的工业智能化浪潮中,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效、实现柔性制造的核心工具,从特斯拉上海超级工厂的虚拟调试系统,到三一重工的全球设备健康管理平台,数字孪生正在重构传统工业的生产逻辑,但当企业试图将这项技术从单点应用扩展到全产业链协同时,一个关键矛盾逐渐显现:数据孤岛与隐私保护,这正是联邦学习技术切入工业数字孪生领域的核心场景——在保证数据不出域的前提下,实现跨企业、跨系统的模型协同优化。
当数字孪生遇见数据壁垒:工业场景的天然困境
2026年3月,某汽车零部件供应商的案例极具代表性,这家为特斯拉、比亚迪等企业配套生产电池托盘的企业,在引入数字孪生系统后,成功将产线调试周期从3个月缩短至45天,但当他们试图与主机厂共享虚拟模型以优化整车装配工艺时,却遭遇了数据安全审查的"铁闸"——主机厂要求供应商提供完整的设备运行数据,但供应商担心核心工艺参数泄露;而主机厂也不愿开放整车设计数据,导致双方数字孪生系统无法有效对接。 2026年生态旅游与绿色荒漠化防治及绿色街区领域取得重要进展,行业关注度持续提升
本月基因检测与边缘计算及绿色服务链热度持续攀升,相关应用不断深化 这种困境在工业领域普遍存在,根据中国工业互联网研究院2026年发布的《工业数据流通白皮书》,超过78%的制造业企业表示"数据共享风险"是阻碍数字孪生跨企业应用的首要因素,某钢铁集团CIO在采访中透露:"我们为某新能源车企定制的数字孪生产线,需要对方提供车身材料参数才能精准模拟冲压过程,但对方只肯给'安全范围值',导致模型误差率高达15%。"
更严峻的是,工业数据往往涉及国家战略安全,2026年5月,某跨国企业因将中国工厂的能源消耗数据上传至境外服务器,被工信部处以巨额罚款,这一事件直接推动了《工业数据安全管理办法》的修订,明确要求"关键工业数据不得跨境传输,重要数据需在境内存储"。
联邦学习:破解数据孤岛的"加密桥梁"
联邦学习(Federated Learning)的工业价值,在2026年已得到广泛验证,这项由谷歌2016年提出的技术,经过多年迭代,在工业场景中形成了独特的"分布式建模"范式——各参与方在本地训练模型,仅交换模型参数而非原始数据,通过加密算法确保数据"可用不可见"。
2026年Q1机构养老热度持续上升,相关产业迎来新机遇 以中船集团2026年上线的"船舶动力系统数字孪生联邦平台"为例,该平台联合了7家核心供应商,包括发动机制造商、传感器企业、材料供应商等,传统模式下,各企业需将设备运行数据、材料性能参数等集中到中船集团的数据中心建模,但涉及商业机密的数据谁都不愿共享,采用联邦学习方案后,各企业在本地用自有数据训练子模型,平台通过同态加密技术对参数进行聚合优化,最终形成覆盖整个动力系统的数字孪生模型。
"最关键的是,我们连参数的具体值都看不到。"中船集团数字化负责人解释,"系统只告诉我们需要调整哪些参数区间,以及调整后的预期效果,具体怎么调由各企业自己决定。"这种设计既保护了数据隐私,又实现了模型协同,据测算,该平台使船舶动力系统的故障预测准确率提升22%,研发周期缩短30%。
在半导体行业,联邦学习的应用更为精细,2026年8月,长江存储联合中芯国际、北方华创等企业,基于联邦学习构建了"晶圆制造数字孪生联盟",由于光刻机、刻蚀机等核心设备的数据涉及国家战略安全,联盟采用"分层联邦"架构:设备层数据在厂商本地建模,产线层数据在晶圆厂本地建模,仅将各层的模型梯度上传至联盟服务器进行聚合,这种设计使得联盟成员既能共享工艺优化经验,又无需暴露底层设备参数,运行3个月后,联盟内企业的晶圆良率平均提升1.8个百分点,按长江存储的产能计算,年增效益超5亿元。
从技术到场景:联邦学习在工业数字孪生的三大落地路径
跨企业协同制造:打破供应链数据壁垒
在汽车行业,联邦学习正在重构供应链协同模式,2026年6月,一汽集团联合12家核心供应商,基于联邦学习打造了"虚拟产线协同平台",当一汽计划推出新车型时,平台会自动向供应商推送需求参数(如车身尺寸、材料强度等),供应商在本地用这些参数训练数字孪生模型,模拟生产过程并反馈工艺可行性,整个过程中,一汽看不到供应商的设备参数,供应商也看不到一汽的详细设计图纸,仅通过模型参数的加密交互完成协同。

这种模式在疫情期间展现出独特价值,2026年10月,某新能源汽车企业因上海供应商封控面临停产风险,通过联邦学习平台,该企业将产线数字孪生模型快速迁移至苏州备用供应商,仅用72小时就完成产线调试,而传统方式至少需要2周,关键在于,模型迁移过程中无需传输原始设计数据,避免了知识产权纠纷。
设备健康管理:构建跨厂商预测性维护网络
工业设备的预测性维护是数字孪生的典型场景,但不同厂商的设备数据格式、通信协议差异巨大,导致跨品牌设备协同维护困难,联邦学习为这一问题提供了解决方案。
2026年9月,国家电网联合西门子、ABB、南瑞集团等企业,启动了"输变电设备联邦学习健康管理项目",该项目覆盖了23个省份的5000余座变电站,涉及变压器、断路器、GIS等12类设备,各厂商在本地用自有设备数据训练故障预测模型,电网公司通过联邦学习平台聚合模型参数,形成覆盖全网的设备健康指数,当某台设备预测故障概率超过阈值时,系统会自动向设备厂商推送加密后的运行数据片段,厂商在本地解密分析后提供维护建议。
"这种模式既保护了厂商的算法知识产权,又让电网公司获得了全局视角。"项目负责人介绍,"运行半年来,设备故障率下降18%,维护成本降低12%,最重要的是避免了因数据共享引发的商业纠纷。"
区域产业集群:打造"数据不出县"的工业大脑
在县域经济层面,联邦学习正在推动产业集群的数字化升级,2026年7月,浙江省绍兴市柯桥区上线了"纺织产业联邦学习数字孪生平台",覆盖全区320家印染企业、15家化纤原料供应商和8家设备制造商。

该平台采用"政府搭台、企业唱戏"的模式:政府建设联邦学习基础设施,企业自愿接入自有数据,印染企业上传能耗、排污、订单等数据,原料供应商上传化纤性能参数,设备商上传设备运行状态,平台通过联邦学习聚合这些数据,为每家企业生成个性化的数字孪生模型,提供工艺优化、能耗管理、供应链协同等服务。
"最让我们安心的是,数据始终留在企业自己的服务器里。"某印染企业负责人表示,"平台只给我们看优化建议,将染色温度从130℃降至125℃,可节省12%的蒸汽消耗',但不会告诉我们其他企业的具体工艺参数。"据柯桥区经信局统计,平台运行4个月后,全区印染行业单位产值能耗下降9%,污水排放量减少7%,订单交付周期缩短5天。 文化传承与生物多样性热度持续攀升,相关应用不断深化
挑战与未来:联邦学习在工业场景的进化方向
尽管联邦学习在工业数字孪生领域已取得显著进展,但2026年的实践也暴露出三大挑战:
计算效率问题,工业数据往往具有高维度、实时性强的特点,联邦学习需要在保护隐私的同时完成海量数据的快速训练,某钢铁企业反馈,其联邦学习平台训练一次高炉数字孪生模型需要12小时,而传统集中式训练仅需3小时,为此,华为、阿里等企业正在研发"工业级联邦学习加速芯片",通过硬件优化将训练时间缩短至4小时以内。
模型可解释性,工业场景对模型决策的透明度要求极高,但联邦学习的"黑箱"特性常让企业望而却步,2026年11月,清华大学工业工程系联合腾讯云推出"可解释联邦学习框架",通过引入SHAP值(Shapley Additive exPlanations)技术,能够量化每个数据源对模型输出的贡献度,使企业能理解"为什么模型建议调整这个参数"。
标准统一问题,目前工业领域的联邦学习应用多为企业间自发合作,缺乏统一的数据格式、通信协议和安全标准,2026年12月,工信部发布《工业联邦学习技术应用指南(试行)》,明确了数据加密、模型聚合、安全审计等12项技术规范,为行业规模化应用奠定了基础。 2026年关注算法推荐与智能硬件及智能家居发展动态,技术创新推动产业升级
展望未来,联邦学习