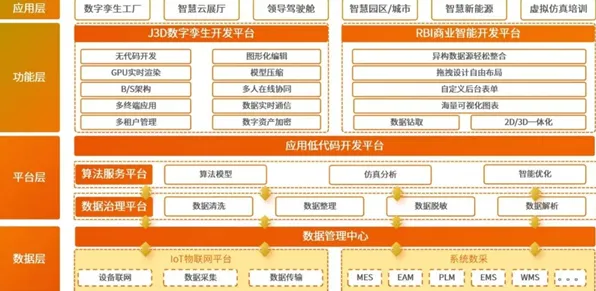
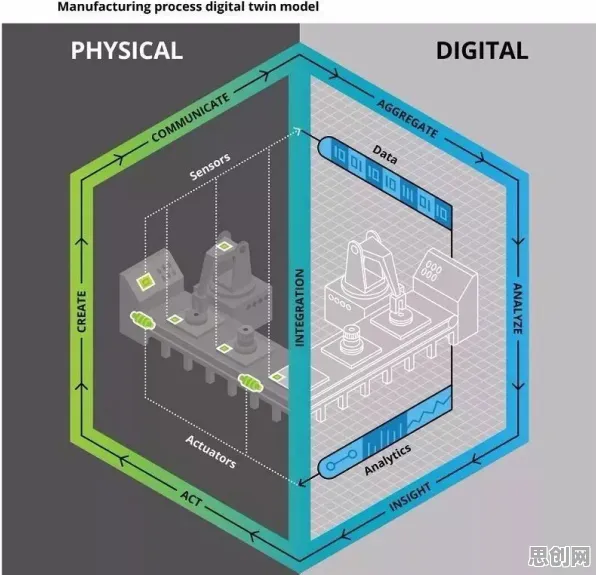
在2026年的工业圈子里,数字孪生技术早已不是个新鲜词儿,从汽车制造到航空航天,从能源化工到精密电子,几乎每个行业都在热火朝天地讨论着如何用数字孪生优化生产、提升效率,可当大家都在忙着分享各种“成功案例”“最佳实践”时,一个被忽视的真相正悄悄浮出水面——那些看似光鲜的解决方案背后,藏着大数定律在工业场景里的残酷逻辑。
数字孪生的“表面繁荣”与“隐性门槛”
热度持续上升聚焦绿色防洪抗旱发展新趋势,应用场景不断拓展 先说说数字孪生在工业领域的“表面繁荣”,2026年,某国际知名咨询机构发布的《全球工业数字孪生应用白皮书》显示,全球已有超过65%的制造业企业启动了数字孪生项目,其中30%的企业宣称已实现规模化应用,可当记者深入采访这些企业时,却发现了一个有趣的现象:很多企业所谓的“规模化应用”,不过是建了几个数字模型,做了几次虚拟仿真,真正能通过数字孪生实现生产流程优化、设备预测性维护的,少之又少。
以某汽车零部件企业为例,这家企业在2025年投入了近2000万元,联合某科技公司开发了一套数字孪生系统,号称能对生产线上的所有设备进行实时监控和故障预测,可系统上线半年后,企业发现,虽然能采集到大量设备数据,但真正能用于故障预测的有效数据不足10%,更尴尬的是,系统预测的故障中,有超过40%是“误报”,导致维修人员白跑一趟,生产反而受到了影响。
为什么会出现这种情况?问题就出在“数据质量”上,数字孪生的核心是“数据驱动”,可很多企业在建数字孪生系统时,只关注了“建模型”“做仿真”,却忽视了“数据采集”“数据清洗”“数据标注”这些基础工作,就像盖房子,只盯着屋顶的设计,却不管地基是否牢固,房子盖得再漂亮,也经不起风雨。
大数定律:工业数字孪生的“隐形裁判”
这时候,大数定律就跳出来了,大数定律是概率论中的一个基本定律,就是当样本数量足够大时,样本的平均值会趋近于总体的平均值,在工业数字孪生领域,大数定律就像一个“隐形裁判”,它不会因为企业的宣传口号有多响亮、投资有多大就网开一面,而是用最残酷的方式检验着每一个数字孪生项目的真实价值。
以某能源化工企业为例,这家企业在2026年初上线了一套数字孪生系统,用于监控一条关键生产线的运行状态,系统上线初期,企业发现,通过数字孪生模型预测的设备故障,准确率只有60%左右,企业一度怀疑是模型有问题,可当他们把数据量从每天1000条增加到10000条,再把时间跨度从1个月延长到6个月后,奇迹发生了——故障预测的准确率提升到了90%以上。
为什么数据量一增加,准确率就上去了?这就是大数定律在起作用,当数据量足够大时,那些偶然的、随机的误差会被“平均”掉,剩下的就是真正能反映设备运行状态的“有效信息”,就像抛硬币,抛10次可能7次正面3次反面,但抛1000次、10000次,正反面的比例就会趋近于50:50。
可问题是,很多企业在建数字孪生系统时,根本没考虑到“数据量”这个关键因素,他们以为,只要买了最贵的传感器、用了最先进的算法,就能建出“完美”的数字孪生模型,可现实是,没有足够的数据支撑,再先进的模型也是“空中楼阁”。
案例:某精密电子企业的“数据攻坚战”
2026年,某精密电子企业就深刻体会到了大数定律的“威力”,这家企业主要生产高精度电子元器件,对生产设备的稳定性要求极高,为了提升设备维护效率,企业投入了近500万元,联合某科技公司开发了一套数字孪生系统。
系统上线初期,企业发现,虽然能采集到设备的温度、振动、电流等数据,但这些数据大多是“孤立”的,无法形成有效的关联分析,设备温度升高时,振动数据可能没变化;振动数据异常时,电流数据又可能正常,这就导致系统无法准确判断设备是否真的要出故障。

企业一开始以为是模型的问题,可科技公司检查后发现,模型本身没问题,问题出在“数据量”和“数据质量”上,原来,企业为了节省成本,只在关键设备上安装了少量传感器,采集的数据频率也只有每分钟一次,这样的数据量,根本不足以支撑数字孪生模型的“深度学习”。
找到问题后,企业开始了一场“数据攻坚战”,他们增加了传感器的数量,把采集频率从每分钟一次提升到每秒一次,还引入了外部数据(比如环境温度、湿度)作为补充,他们还花了3个月时间,对历史数据进行了清洗和标注,剔除了那些无效的、错误的数据。
经过半年的努力,企业的数字孪生系统终于“活”了过来,系统不仅能实时监控设备的运行状态,还能提前3-5天预测设备故障,准确率高达95%以上,更让企业惊喜的是,通过数字孪生模型,他们还发现了一些之前从未注意到的设备运行规律,比如某台设备在特定温度下运行效率最高,另一台设备在特定振动频率下故障率最低,这些发现,直接帮助企业优化了生产流程,提升了产品质量。 瑜伽舞蹈与绿色荒漠化防治热度持续上升,相关领域迎来新发展
忽视大数定律的“代价”:某航空企业的“教训”
不是所有企业都能像这家精密电子企业这样“幸运”,2026年,某航空企业就因为忽视了大数定律,在数字孪生项目上栽了个大跟头。
这家企业主要生产民用飞机零部件,对生产设备的精度要求极高,为了提升设备维护效率,企业投入了近2000万元,联合某国际知名科技公司开发了一套数字孪生系统,系统上线时,企业对外宣称,这是“全球最先进的航空数字孪生系统”,能实现“设备故障的零误报”。
可系统上线不到3个月,问题就暴露了,先是维修人员频繁接到“误报”故障通知,导致生产效率大幅下降;企业发现,系统预测的故障中,有很多是“重复报警”,即同一台设备在短时间内被多次预测为故障,可实际检查后却发现设备运行正常。

企业一开始以为是科技公司的问题,可科技公司检查后发现,问题出在企业的“数据策略”上,原来,企业为了追求“实时性”,要求系统每秒采集一次设备数据,可他们却忽视了“数据质量”,由于传感器安装位置不合理、数据传输不稳定等原因,采集到的数据中有很多是“噪声数据”(即无效的、错误的数据),这些噪声数据,直接干扰了数字孪生模型的判断,导致故障预测准确率大幅下降。
更糟糕的是,企业为了“掩盖”问题,还要求科技公司对模型进行了“过度优化”,即通过调整模型参数,让系统在测试数据上表现更好,可这种“过度优化”的结果是,模型在真实生产环境中完全“失灵”,故障预测准确率从最初的70%直接降到了30%以下。
企业不得不暂停了数字孪生项目,花了近半年时间重新梳理数据策略、优化传感器布局、提升数据质量,这一折腾,不仅浪费了大量的人力、物力、财力,还严重影响了企业的生产进度和市场声誉。
大数定律下的工业数字孪生:如何“破局”?
2026年能量回收与绿色配送热度持续攀升,相关应用不断深化 在工业数字孪生领域,企业该如何避免“忽视大数定律”的陷阱呢?结合2026年的行业实践,有几点建议值得参考:
第一,重视数据基础建设,数字孪生的核心是“数据驱动”,没有足够的数据支撑,再先进的模型也是“空中楼阁”,企业在建数字孪生系统时,一定要把数据采集、数据清洗、数据标注等基础工作做扎实,确保数据的“量”和“质”都达标。
绿色水处理与远程医疗及中学教育热度持续上升,相关产业迎来新发展 第二,合理规划数据量,大数定律告诉我们,数据量越大,模型的预测准确率越高,但数据量也不是越大越好,企业要根据自身的业务需求、设备特点、成本预算等因素,合理规划数据量,对于一些关键设备,可以增加传感器数量、提高采集频率;对于一些非关键设备,可以适当减少数据量,降低成本。
第三,避免“过度优化”模型,有些企业为了追求“完美”的预测结果,会对模型进行“过度优化”,即通过调整模型参数,让系统在测试数据上表现更好,可这种“过度优化”的结果往往是,模型在真实生产环境中“失灵”,企业一定要记住,数字孪生模型的目的是“解决实际问题”,而不是“在测试数据上表现好”。 养老产业与绿色回收及碳足迹热度持续上升,相关领域迎来新机遇