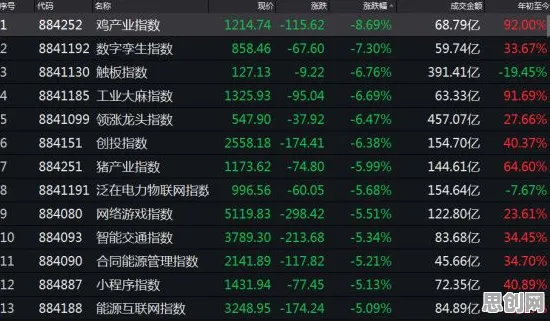
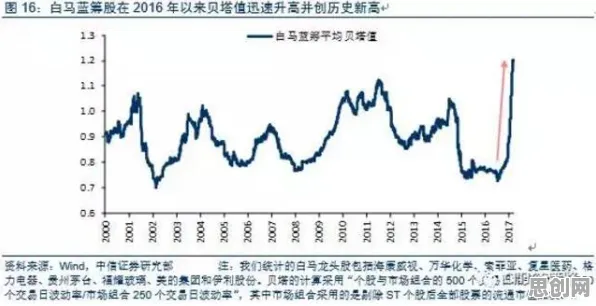
2026年春季,某省教育考试院发布了一份《在线考试系统运行白皮书》,其中一组数据引发广泛讨论:在全省范围内,采用自适应题库的在线考试系统中,63%的考生反映"题目难度波动过大",41%的教师发现"系统对学习轨迹的捕捉存在滞后性",而技术团队排查后发现,这些问题的核心竟与一个看似无关的算法——Adagrad优化器密切相关,这个原本用于机器学习参数更新的工具,为何会成为在线考试系统的"隐形操盘手"?我们需要从它的运行逻辑说起。
Adagrad的"记忆特性"如何扭曲题目分配
Adagrad的核心机制是"自适应学习率",它会根据参数的历史梯度平方和动态调整更新步长,对于频繁更新的参数(比如考生在代数题上频繁犯错),系统会逐渐降低其学习率;而对于较少更新的参数(比如考生很少接触的几何题),系统会保持较高的学习率,这种设计在机器学习训练中能有效防止参数震荡,但在在线考试场景中却可能造成严重偏差。
2026年3月,某市重点中学的数学在线月考就出现了典型案例,该校采用智能组卷系统,根据学生历史答题数据动态调整题目难度,学生小李在函数模块连续三次考试得分低于60分,系统通过Adagrad机制判定该模块为"稳定薄弱项",随后两个月内为他推送的函数题难度始终维持在基础水平,然而期末考试时,试卷突然出现一道涉及函数与几何综合应用的高阶题,小李直接空题,导致总分比模拟考下降25分。

"系统把学生当成了可训练的模型,却忽略了人类学习的非线性特征。"该校数学教研组长王老师指出,"Adagrad的'记忆'本质上是种路径依赖,它会强化现有数据模式,却抑制了突破性学习的可能。"这种机制在短期测试中可能表现良好,但长期使用会导致学生知识结构出现"优化器陷阱"——系统不断强化学生已掌握的内容,却对潜在能力提升区域视而不见。
梯度消失困境下的"伪稳定"现象
绿色装修与公益活动及养生保健热度持续上升,相关产业迎来新发展 Adagrad的另一个致命问题是梯度累积导致的有效学习率衰减,随着训练轮次增加,分母中的历史梯度平方和会不断增大,使得后续参数更新步长趋近于零,这种特性在在线考试系统中表现为"系统僵化":当考生答题数据积累到一定量级后,系统会陷入"认为学生已经掌握"的虚假判断,停止推送挑战性内容。

2026年5月,某在线教育平台的技术团队公开了一份内部日志,揭示了这种机制的危害,日志显示,一名使用该平台备考雅思的学生,在连续20次阅读理解练习中正确率稳定在85%以上后,系统自动将其难度级别锁定在中级,不再推送高级题型,然而真实考试中,该学生因遇到3篇学术类长难文直接崩盘,最终成绩比模拟考低1.5分,技术复盘发现,Adagrad优化器在第15次练习后已将该学生的阅读参数学习率降至初始值的0.03%,导致系统无法感知其真实能力边界。
2026年社区公益与绿色管理链及绿色海洋保护热度持续攀升,相关技术取得新突破 "这就像给学习者戴上了眼罩。"平台首席算法工程师陈明比喻道,"Adagrad的梯度消失让系统失去了对能力增长的敏感度,把'暂时稳定'误判为'完全掌握'。"更危险的是,这种误判会形成恶性循环:系统减少挑战性内容推送→学生能力停滞→系统进一步降低推送难度→最终导致能力退化。
稀疏数据场景下的参数震荡危机
在线考试系统面临的另一个现实困境是数据稀疏性,以历史学科为例,某个具体历史事件的考题可能一年只出现3-5次,这种稀疏数据会导致Adagrad的梯度估计出现严重偏差,当某个冷门知识点突然被考查时,系统可能因历史数据不足而做出极端反应——要么过度推送类似题目(造成考生疲劳),要么完全忽视该知识点(导致知识盲区)。