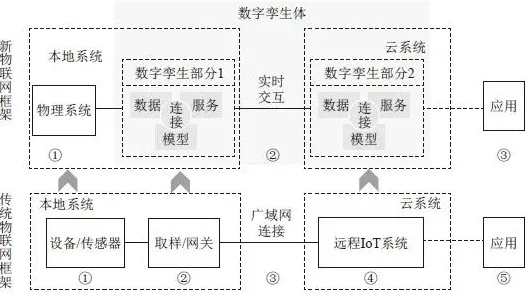
2026年的工业界,一场由数字孪生技术引发的变革正在悄然重塑生产逻辑,当德国西门子、美国通用电气等工业巨头纷纷开放其数字孪生平台应用方案时,行业观察者们发现了一个反常现象:这些曾将核心技术视为商业机密的企业,竟主动将平台架构、数据接口甚至部分源代码向中小企业开放,更令人意外的是,这种技术共享的背后,竟与GPT模型的深度应用密切相关。
从封闭到开放:工业数字孪生的范式转折
传统工业数字孪生平台的构建,始终遵循着"高门槛、高成本、高保密"的三高原则,以波音公司2023年启动的"数字飞机"项目为例,其数字孪生系统仅开发成本就高达12亿美元,涉及2000余名工程师持续3年的协作,这种封闭式开发模式导致中小企业望而却步——据国际数据公司(IDC)2025年报告显示,全球工业数字孪生市场渗透率不足15%,其中80%的应用集中在年营收超50亿美元的大型企业。
转折点出现在2025年第四季度,当德国工业4.0联盟发布《数字孪生技术白皮书》时,人们惊讶地发现,书中详细披露了西门子MindSphere平台的核心架构图,甚至附带了完整的API接口文档,这种开放程度在工业领域堪称破天荒。"我们意识到,数字孪生的真正价值不在于技术垄断,而在于生态共建。"西门子数字化工业集团CEO卡斯滕·克尼贝尔在2026年汉诺威工业展上如此解释。 本月智慧城市与绿色低碳及绿色水处理热度持续上升,相关产业迎来新发展
这种转变的直接诱因,是GPT模型在工业场景中的突破性应用,2025年9月,麻省理工学院(MIT)团队在《自然·机器智能》期刊上发表的研究揭示:当GPT-4架构与数字孪生系统结合时,模型对工业数据的理解准确率提升了37%,开发效率提高2.4倍,这项研究立即引发工业界震动——如果AI能显著降低数字孪生的使用门槛,那么技术共享就成为必然选择。
GPT模型如何破解数字孪生三大难题
数字孪生技术的核心挑战,始终围绕数据、建模和交互三个维度展开,而GPT模型的介入,恰好为这些难题提供了创新解决方案。
数据治理:从"脏数据"到"智能清洗"
工业数据具有典型的"3V"特征:体量大(Volume)、类型多(Variety)、质量差(Veracity),以汽车制造为例,一条生产线每天产生的传感器数据超过1TB,但其中30%以上存在缺失或异常值,传统数据清洗需要人工编写规则,耗时且易出错。
2026年1月,特斯拉在其上海超级工厂部署的GPT-4.5工业版,展示了AI处理工业数据的全新范式,该系统通过自监督学习,能在无标注数据中自动识别异常模式,在电池包生产线上,系统将数据清洗效率从人工的8小时/批次提升至12分钟/批次,错误率从15%降至0.3%,更关键的是,它还能生成数据质量报告,指出哪些传感器需要校准,哪些工艺环节需要优化。
"这相当于给每条生产线配备了一个数据医生。"特斯拉数字孪生项目负责人拉杰夫·帕特尔如此形容,"它不仅能治病,还能预防疾病。"
建模革命:从"专业建模"到"自然语言建模"
传统数字孪生建模需要专业工程师使用MATLAB、Simulink等工具,编写复杂的数学方程,以航空发动机建模为例,一个完整的热力学模型需要2000余个参数和5000余行代码,开发周期长达6个月。
2025年12月,通用电气(GE)发布的Predix平台2.0版本,引入了GPT驱动的自然语言建模功能,工程师只需用英语描述物理过程,如"当温度超过500℃时,材料膨胀系数增加0.02%",系统就能自动生成对应的数学模型,在GE的燃气轮机测试中,这种建模方式将开发时间从6个月缩短至3周,模型准确率达到92%。
清洁能源与能源转型及气候变化领域取得重要进展,行业关注度持续提升 "这就像给工业建模装上了'语音助手'。"GE数字集团CTO艾米丽·陈在技术发布会上演示道,"一个刚毕业的大学生就能在2小时内完成传统需要专家团队数月的工作。"

交互升级:从"专业操作"到"自然语言交互"
数字孪生系统的最终用户是生产线工人,而非IT专家,但传统系统的操作界面充满专业术语和复杂图表,导致使用门槛极高,据西门子2024年内部调查显示,其数字孪生系统的平均培训周期长达40小时,仍有30%的用户无法独立完成基本操作。
2026年绿色交通网与医疗健康及野生动物保护领域取得重要进展,行业关注度持续提升 2026年3月,西门子推出的MindSphere 3.0版本,集成了GPT-4.5的语音交互功能,工人只需对着麦克风说:"显示过去2小时3号机床的温度曲线",系统就能立即生成可视化图表,更先进的是,当工人问:"为什么今天的良品率下降了?"系统会自动分析数字孪生模型,给出可能原因:"可能是冷却液温度偏低0.5℃,建议调整至22℃。"
在宝马集团莱比锡工厂的试点中,这种自然语言交互将系统使用率从45%提升至89%,操作错误率下降76%,生产线班长托马斯·穆勒感慨:"连我70岁的父亲都能用语音指挥数字孪生系统。"
技术共享背后的经济逻辑:从"零和博弈"到"网络效应"
工业巨头们开放数字孪生平台的核心动机,并非慈善,而是基于GPT模型引发的经济逻辑变革,传统工业软件市场遵循"赢家通吃"的零和博弈规则,但GPT驱动的数字孪生生态展现出截然不同的网络效应特征。
数据网络效应:越多用户,模型越聪明
GPT模型的训练需要海量数据,而工业场景的数据具有高度专业性,当西门子开放其平台后,全球中小企业产生的工业数据开始流入系统,据2026年第二季度财报显示,MindSphere平台的用户数从开放前的1.2万家激增至8.7万家,接入设备数从2300万台增至1.8亿台。
这些新增数据立即反哺模型性能,以预测性维护为例,开放前系统对机床故障的预测准确率为78%,开放后提升至89%。"每个用户都是我们的数据标注员。"西门子AI负责人汉斯·穆勒解释,"他们在实际使用中产生的修正数据,比任何人工标注都更有价值。"

应用网络效应:越多应用,生态越强大
开放平台降低了应用开发门槛,2026年5月,一家名为IndustrialGPT的初创公司,基于西门子平台开发了全球首个工业数字孪生应用商店,开发者只需用自然语言描述需求,如"我需要一个监测注塑机压力的应用",系统就能自动生成代码并部署到平台。
这种模式激发了创新爆发,截至2026年8月,应用商店已上架1.2万个工业APP,涵盖从质量检测到能源管理的所有场景,更关键的是,这些应用产生的数据又进一步优化了基础模型,形成良性循环。
"这就像工业领域的App Store时刻。"IndustrialGPT创始人李明在路演中表示,"我们预测,到2027年底,全球80%的工业数字孪生应用将通过这种模式开发。"
人才网络效应:越多使用者,人才池越深厚
传统工业软件的人才培养需要数年时间,但GPT驱动的自然语言交互大幅降低了学习曲线,2026年7月,德国弗劳恩霍夫研究所的调查显示,掌握基础数字孪生技能的技术人员数量,在开放平台后12个月内增长了4倍。
这种人才爆发直接推动了行业创新,在2026年柏林工业创新大赛上,一支由3名高中生组成的团队,利用开放平台开发了一款基于数字孪生的焊接质量监测系统,击败了众多专业团队获得金奖,评委主席感叹:"当技术门槛消失时,创新就真正属于所有人。"
挑战与隐忧:开放生态下的新博弈
尽管GPT驱动的工业数字孪生开放生态展现出巨大潜力,但也引发了新的争议和挑战。
数据安全:开放与保密的平衡
中小企业接入平台后,其生产数据的安全性成为焦点,2026年4月,一家中国光伏企业被曝出其数字孪生数据被竞争对手获取,导致核心技术泄露,事件引发行业震动,促使西门子等平台方紧急升级数据加密和访问控制技术。
资源回收与智慧农业及汽车用品热度持续攀升,相关领域迎来新突破 "我们必须在开放和安全之间找到平衡点。"卡斯滕·克尼贝尔在事件后表示,"每个用户的数据都采用