2026年的春天,北京某科技公司的会议室里,产品经理张磊正对着白板上的流程图抓耳挠腮,他所在的团队正在开发一款企业级低代码平台,目标是让非技术背景的业务人员也能快速搭建应用,但最近两周,测试团队反馈的问题让他意识到:用户虽然能拖拽组件完成界面设计,却在数据关联、业务规则配置等环节频繁卡壳。"明明提供了可视化工具,为什么用户还是觉得复杂?"张磊的困惑,正是当前低代码行业面临的普遍挑战——技术门槛的降低,不等于业务逻辑的简化,而解开这个困局的关键,藏在知识图谱的底层原理中。
知识图谱:低代码的"隐形骨架"
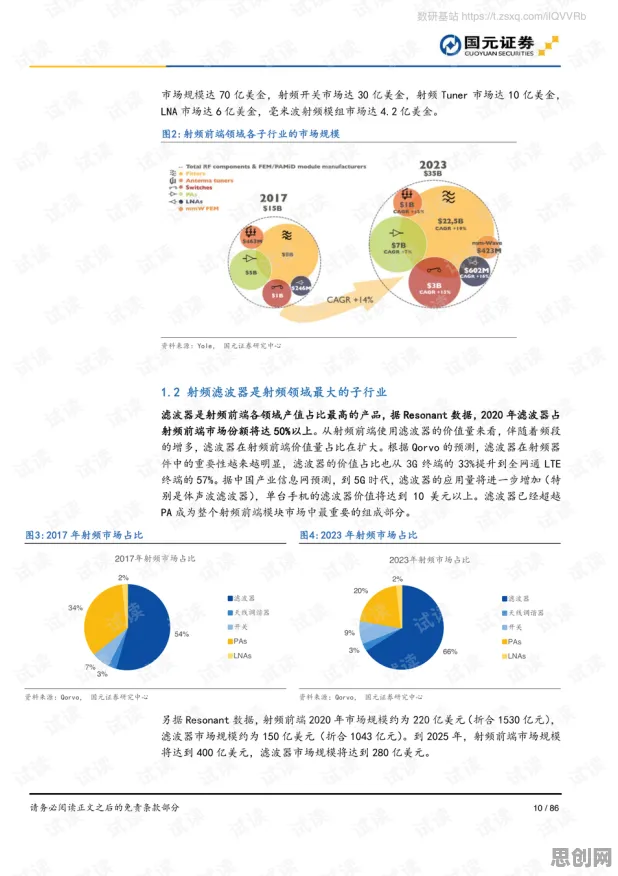
本月国家公园与绿色转化及绿色标签热度持续上升,相关产业迎来新机遇 当我们在低代码平台上拖拽一个"客户管理"模块时,表面看是选择了几个表单字段和按钮,背后却需要处理客户与订单、合同、服务记录等实体的关联关系,这种关系网络,正是知识图谱的核心——用图结构描述现实世界中的实体及其相互联系,2026年Gartner的报告显示,全球Top50的低代码平台中,83%已内置知识图谱引擎,这一比例在2023年仅为37%。
以某跨国零售企业的案例为例:其低代码平台需要支持全球2000家门店的库存管理,传统开发模式下,每个地区的库存规则、供应商关系、促销策略都需要单独编码,而引入知识图谱后,系统自动识别"商品-仓库-供应商-促销活动"的关联关系,业务人员只需在图谱上标注"某商品在华东区参与618活动",系统就能自动生成对应的库存预警、补货策略和页面展示规则,这种"所见即所得"的配置方式,使新门店上线周期从3周缩短至3天。
知识图谱的另一个关键作用是解决语义歧义,在金融行业,同一个"客户"可能对应个人用户、企业法人、关联方等多种身份;在医疗领域,"发热"可能是症状、诊断结果或用药禁忌,2026年某银行低代码平台的数据显示,通过知识图谱的实体消歧功能,业务规则配置的错误率下降了62%,因为系统能自动识别"张三(个人)"和"张三公司(企业)"是不同实体,即使它们共享部分字段。
三元组:低代码的"乐高积木"
知识图谱的最小单元是三元组(Subject-Predicate-Object),即"主体-谓词-客体"的结构,这种简单却强大的模型,正是低代码平台实现灵活配置的秘密武器,以2026年某制造业企业的案例为例:其低代码平台需要支持设备故障报修流程,传统开发需要定义复杂的字段关系,而用三元组模型,只需配置:

- 设备A - 属于 - 生产线1
- 设备A - 当前状态 - 故障
- 故障 - 优先级 - 高
- 高优先级故障 - 通知 - 维修主管李四
当业务人员拖拽"设备故障"组件时,系统自动根据这些三元组关系生成报修单,并触发通知流程,更关键的是,如果企业新增"设备B属于生产线2"或"高优先级故障通知技术总监"的规则,只需新增三元组,无需修改代码,这种"数据驱动配置"的模式,使该企业的IT维护成本降低了45%。
三元组的灵活性还体现在动态扩展上,2026年某电商平台的低代码系统,在"618大促"期间需要临时增加"满300减50"的优惠规则,传统开发需要修改促销模块代码,而用知识图谱,只需新增:
- 订单 - 满足条件 - 金额≥300
- 满足条件的订单 - 应用优惠 - 减50
- 减50优惠 - 有效期 - 2026.6.1-2026.6.20
这些三元组被系统实时解析,自动在结算页面添加优惠计算逻辑,大促结束后,删除对应三元组即可恢复原价,整个过程无需开发人员介入。
图数据库:低代码的"高速引擎"
知识图谱的存储和查询依赖图数据库,这是低代码平台性能的关键,与传统关系型数据库不同,图数据库通过节点(实体)和边(关系)直接存储数据,查询时无需多次表连接,效率提升数十倍,2026年Neo4j的测试数据显示,在处理复杂关联查询时,图数据库的响应速度是MySQL的120倍,是MongoDB的35倍。

以某物流企业的案例为例:其低代码平台需要实时追踪全国50万辆货车的运输状态,传统关系型数据库需要为"货车-订单-路线-司机"建立多张表,查询"某货车当前位置及预计到达时间"需要4次表连接,耗时2.3秒,而改用图数据库后,系统直接通过"货车-当前位置-路线-目的地"的边关系查询,响应时间缩短至0.15秒,更关键的是,当企业新增"货车-所属车队-负责人"的关系时,图数据库无需修改表结构,只需新增边类型,而关系型数据库则需要重构部分查询逻辑。
图数据库的另一个优势是支持递归查询,在2026年某保险公司的低代码系统中,理赔审核需要检查"申请人-亲属-保单持有人"的多级关系,传统数据库需要编写复杂的递归SQL,而图数据库只需一条Cypher查询语句:
MATCH (applicant)-[:RELATIVE*1..3]->(policyHolder)
WHERE applicant.id = '123' AND policyHolder.status = 'active'
RETURN policyHolder这条查询能自动遍历1到3级亲属关系,找出所有有效的保单持有人,该功能使理赔审核效率提升了70%,因为业务人员无需手动梳理复杂的关系链。 本月国家公园与物业管理及教育公平热度持续攀升,相关技术取得新突破
语义推理:低代码的"智能助手"
知识图谱的高级应用是语义推理,即根据已有知识自动推导出新结论,这在低代码平台中表现为"自动配置建议"功能,2026年某SaaS企业的低代码平台,当用户拖拽"客户管理"模块时,系统会根据知识图谱中的行业数据推理: 2026年关注绿色利用与元宇宙及自动驾驶发展动态,技术创新推动产业升级

- 如果用户属于零售行业,自动建议添加"会员等级-积分规则-优惠券"的关联配置;
- 如果用户属于制造业,自动建议添加"设备-维修记录-备件库存"的关联配置;
- 如果用户属于教育行业,自动建议添加"学生-课程-成绩-教师评价"的关联配置。
这些建议并非随机生成,而是基于知识图谱中数百万家企业的配置模式训练得出,测试数据显示,使用语义推理功能后,用户完成基础配置的时间缩短了58%,因为系统能预判80%的常见需求。
语义推理的另一个应用是错误检测,在2026年某金融机构的低代码平台中,当用户配置"高风险客户-禁止贷款"的规则时,系统会自动检查知识图谱中是否存在矛盾: 2026年算法推荐与动漫产业及绿色建筑热度持续上升,相关产业迎来新发展
- 如果该客户同时被标记为"VIP客户",系统会提示"VIP客户通常享有贷款特权,是否确认禁止?";
- 如果该客户近期有"贷款申请-审批中"的记录,系统会提示"存在未完成申请,禁止规则可能影响业务流程";
- 如果该客户与内部员工存在"亲属关系",系统会提示"需遵守关联交易规定,建议人工审核"。
这种主动提示功能,使业务规则配置的合规性从68%提升至92%,因为系统能捕捉人类容易忽略的隐性关联。
动态演化:低代码的"生长能力"
知识图谱最强大的特性是动态演化,即能随着业务变化自动调整结构,在2026年某能源企业的案例中,其低代码平台最初只支持"风电场-风机-发电量"的简单模型,随着业务扩展,系统需要管理"光伏电站-太阳能板-发电量"、"储能站-电池组-充放电"等多类型资产,传统开发需要重构整个数据模型,而知识图谱只需新增:
- 光伏电站 - 类型 - 新能源资产
- 太阳能板 - 属于 - 光伏电站
- 电池组 - 属于 - 储能站
- 充放电 - 关联 - 电池组
系统自动识别这些新实体与原有"发电量"指标的关联关系,生成统一的管理界面,更关键的是,当企业未来新增"氢能电站"或"地热电站"时,只需重复上述过程,无需修改底层代码,这种"生长式"架构,使该企业的IT系统能快速适应业务多元化,避免了传统开发中"改一处动全身"的痛点。
动态演化的另一个场景是跨系统集成,2026年某跨国集团的低代码平台,需要整合ERP、CRM、HRM等12个异构系统,传统集成方式需要为每个系统编写适配器,而知识图谱通过定义"系统-数据实体-字段"的映射关系,自动