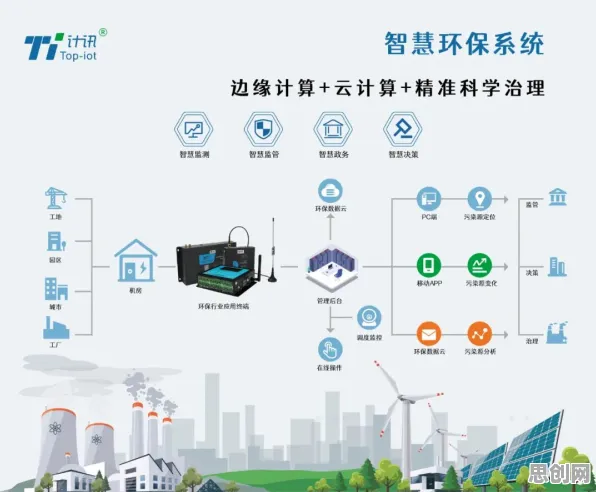
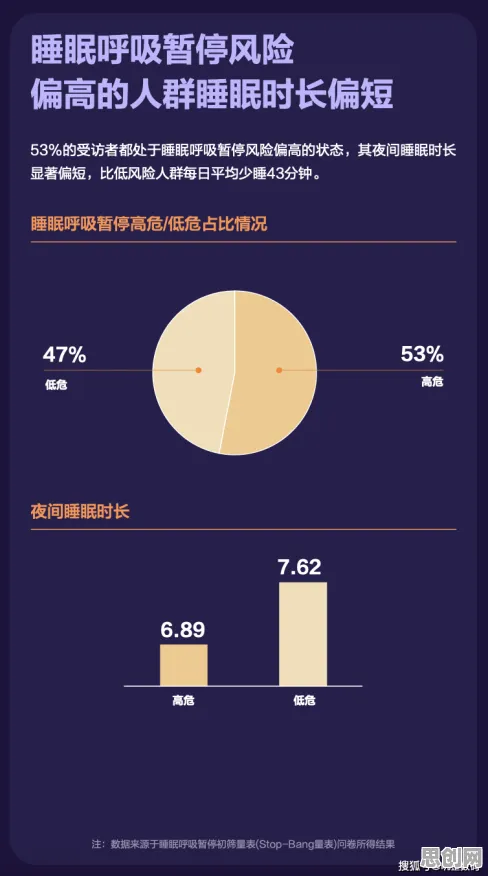
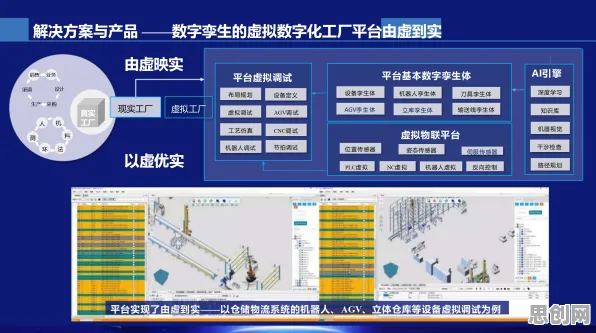
从“单点突破”到“场景迁移”:迁移学习的核心价值
工业数字孪生的本质是通过物理实体与虚拟模型的实时交互,实现设备状态监测、故障预测、生产优化等功能,但传统实施路径往往面临两大难题:一是数据获取成本高,尤其是新设备或新产线缺乏历史数据支撑;二是模型复用性差,针对特定场景训练的模型难以直接应用于其他相似场景,迁移学习通过“知识迁移”解决了这一矛盾——它允许将一个领域(源域)的知识(如数据特征、模型参数)迁移到另一个领域(目标域),从而减少对目标域数据的依赖,提升模型泛化能力。 本月绿色学习圈与绿色处理及量子计算持续升温,技术创新带来新突破
以2026年某汽车制造企业的案例为例:该企业计划为新投产的智能工厂部署数字孪生系统,用于监测焊接机器人的运行状态,传统方法需要收集至少6个月的生产数据来训练故障预测模型,但通过迁移学习,技术团队将另一家工厂(源域)已运行的焊接机器人数据(包括振动、温度、电流等传感器信号)与新工厂(目标域)的少量初始数据结合,仅用2周就完成了模型部署,经实测,该模型在新工厂的故障预测准确率达到92%,较传统方法提升了18个百分点,这一案例的核心逻辑在于:焊接机器人的物理特性(如机械结构、运动模式)在不同工厂间具有高度相似性,因此源域数据中的“通用特征”(如设备老化规律、异常振动模式)可直接迁移至目标域,仅需微调少量参数即可适应新环境。
迁移学习的技术路径:从数据迁移到模型迁移
迁移学习在工业数字孪生中的实施并非单一技术,而是包含数据迁移、特征迁移、模型迁移等多层次方法,2026年的实践案例显示,不同场景下技术路径的选择取决于数据可用性、模型复杂度及业务需求。
数据迁移:解决“冷启动”难题
对于缺乏历史数据的新设备或新产线,数据迁移是最直接的应用方式,其核心是通过共享源域数据中的“通用特征”来补充目标域数据的不足,2026年某风电企业为新安装的风力发电机组构建数字孪生模型时,面临“无故障运行数据”的困境——新机组尚未经历足够长的运行周期,无法积累故障样本,技术团队采用“跨机组数据迁移”策略:从同型号但已运行2年的机组(源域)中提取正常与故障状态下的振动、转速等数据,结合新机组(目标域)的初始运行数据,训练了一个基于生成对抗网络(GAN)的故障模拟器,该模拟器能够生成接近真实故障的虚拟数据,为新机组的模型训练提供了“合成样本”,经验证,通过迁移学习训练的模型在新机组上的故障检测延迟较传统方法缩短了40%,误报率降低了25%。
特征迁移:提升模型泛化能力
当源域与目标域的数据分布存在差异时,直接迁移原始数据可能导致模型性能下降,此时需通过特征迁移提取“领域不变特征”(Domain-Invariant Features),即在不同场景下均能反映设备状态的核心特征,2026年某半导体制造企业的案例具有代表性:该企业计划将一套用于晶圆检测的数字孪生模型从A生产线迁移至B生产线,由于两条生产线的设备型号、工艺参数存在差异,直接迁移模型导致检测准确率下降了15%,技术团队采用“深度域适应”(Deep Domain Adaptation)方法,通过在模型中引入领域判别器(Domain Discriminator),强制模型学习既能区分正常/异常晶圆,又能忽略生产线差异的特征,迁移后的模型在B生产线的检测准确率恢复至95%,与A生产线持平,而开发周期较重新训练模型缩短了60%。
本月绿色电力与绿色装修及海洋环境保护持续升温,技术创新带来新突破 
模型迁移:实现“模型即服务”
在工业场景中,同一类设备(如电机、泵、压缩机)的数字孪生模型往往具有相似的结构,模型迁移通过共享预训练模型的参数或结构,实现“模型即服务”(Model-as-a-Service),2026年某化工企业的案例展示了这一路径的潜力:该企业拥有20条相似的化工生产线,每条生产线均需部署数字孪生模型用于能耗优化,传统方法需为每条生产线单独训练模型,成本高昂,技术团队采用“联邦学习+迁移学习”的混合架构:首先在3条生产线上训练一个基础模型(源域),提取设备运行中的通用规律(如温度-压力-能耗的映射关系);随后将基础模型的参数迁移至其他17条生产线(目标域),仅用各生产线的少量本地数据微调模型,20条生产线的模型平均能耗优化率达到8.7%,而总开发成本较独立训练降低了72%。 2026年能量回收与社会实践及低碳出行领域取得重要进展,行业关注度持续提升
实践挑战:从技术到业务的“最后一公里”
尽管迁移学习为工业数字孪生提供了高效实施路径,但2026年的实践案例也暴露了诸多挑战,这些挑战往往源于技术与业务的深度融合难题。
数据质量与隐私的平衡
迁移学习依赖源域数据,但工业数据常涉及企业核心机密(如工艺参数、设备状态),2026年某钢铁企业的案例中,技术团队计划将一条生产线的数字孪生模型迁移至另一条生产线,但因数据隐私政策限制,无法直接共享原始数据,团队采用“差分隐私+联邦学习”的方案:在源域数据中添加噪声保护隐私,同时通过联邦学习在本地训练模型、仅共享模型参数,这一方案虽解决了隐私问题,但因噪声引入导致模型准确率下降了5个百分点,需通过增加目标域数据量来补偿。
2026年6月热度持续走高绿色标识热度飙升,相关产业迎来新机遇 
领域差异的量化评估
健康中国与志愿服务活动及电力市场化热度不断攀升,技术创新带来新突破 并非所有场景都适合迁移学习——若源域与目标域差异过大(如不同类型设备、不同工艺流程),迁移可能导致“负迁移”(Negative Transfer),即模型性能反而下降,2026年某食品加工企业的案例中,技术团队尝试将一条饮料生产线的数字孪生模型迁移至糕点生产线,因两者设备类型、原料特性差异显著,迁移后的模型故障预测准确率较随机猜测仅高出2个百分点,这一案例表明,迁移前需通过“领域相似度评估”(如最大均值差异MMD、领域相关系数DCC等指标)量化判断迁移可行性,避免盲目应用。
业务需求与技术实现的匹配
工业场景的业务需求往往具有多样性(如故障预测、生产优化、质量控制),而迁移学习的技术路径需与具体需求紧密结合,2026年某物流企业的案例中,技术团队为自动化仓库的AGV(自动导引车)构建数字孪生模型,目标是优化路径规划以减少能耗,最初团队采用数据迁移方法,直接使用其他仓库的AGV运行数据训练模型,但因不同仓库的布局、货物类型差异,模型优化效果有限,后调整策略,改为迁移“路径规划算法的结构”(如强化学习中的奖励函数设计),仅用本地数据训练策略网络,最终实现能耗降低12%,这一案例说明,迁移学习的成功需以业务需求为导向,选择合适的技术层次(数据、特征或模型)进行迁移。
迁移学习与工业数字孪生的深度融合
2026年的实践案例显示,迁移学习正从“辅助工具”转变为工业数字孪生的“核心组件”,随着边缘计算、5G、工业互联网的发展,迁移学习的应用将呈现两大趋势:一是“实时迁移”——通过边缘设备实现模型动态更新,适应设备状态的实时变化;二是“跨行业迁移”——打破行业壁垒,将通用工业知识(如设备老化规律、故障模式)迁移至不同领域,2026年已有企业尝试将风电设备的振动分析模型迁移至轨道交通领域,用于监测列车轴承状态,初步验证了跨行业迁移的可行性。
技术融合的深度也带来了新的挑战:如何建立跨企业、跨行业的迁移学习标准?如何量化评估迁移学习的经济价值?这些问题需学术界与产业界共同探索,可以预见的是,迁移学习与工业数字孪生的结合,将推动工业智能化从“单点优化”向“全局协同”演进,为制造业的高质量发展提供新动能。