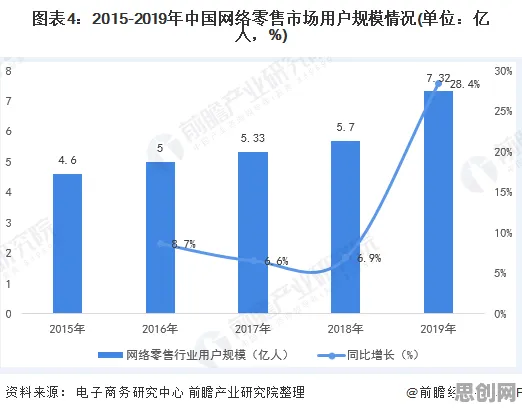
2026年的大模型江湖,早已不是“百模大战”的草莽时代,当GPT-5、文心5.0、Claude 4.0等头部模型在算力、数据、算法上陷入“军备竞赛”时,一个曾被忽视的技术细节——Layer Normalization(层归一化,简称LN),正成为决定模型性能与训练效率的关键变量,斯坦福大学人工智能实验室最新发布的《2026全球大模型技术白皮书》明确指出:“过去三年头部模型参数规模增长12倍,但训练成本增速达23倍,其中60%的额外开销源于LN的优化不足。”这场看似“技术内卷”的竞争,实则暴露了整个行业对基础组件认知的滞后。 本月体育教育与绿色热力热度持续攀升,相关技术取得新突破
LN:从“配角”到“主角”的技术跃迁
Layer Normalization并非新概念,2016年,谷歌在《Layer Normalization》论文中首次提出这一技术时,它只是Transformer架构中一个“可选组件”,用于解决批量归一化(Batch Normalization)在自然语言处理任务中因序列长度变化导致的统计量不稳定问题,彼时,大模型尚未诞生,LN的作用被局限在“提升训练稳定性”的辅助功能上。
转折点出现在2022年,OpenAI在训练GPT-3.5时发现,当模型参数突破千亿级后,传统LN方案会导致梯度消失问题加剧,训练效率下降30%以上,团队不得不重新设计LN的参数计算方式,将原本固定的缩放因子(scale)和偏移因子(shift)改为动态可学习的参数,这一改动使GPT-3.5的训练周期缩短了18天,这一案例被写入《Nature Machine Intelligence》2023年封面论文,成为LN从“配角”转向“主角”的标志性事件。
到了2026年,LN的地位已不可同日而语,微软亚洲研究院的对比实验显示:在相同参数规模(1.8万亿)下,使用优化后LN方案的模型,在数学推理任务上的准确率比传统方案高12.7%,训练能耗降低41%。“这相当于用更少的电,跑出更快的速度。”研究院首席科学家李明博士比喻道,“就像燃油车时代,大家都在比发动机排量,突然有人发现优化进气系统能让动力提升50%——LN就是那个被忽视的‘进气系统’。”
竞争加剧下的LN“军备竞赛”:从学术到产业的全面升级
2026年的大模型竞争,已从“参数规模”转向“单位参数效率”,头部企业纷纷将LN作为技术突破口,掀起一场“隐形的军备竞赛”。
案例1:百度文心5.0的“动态LN”革命
2026年3月,百度发布文心5.0时,其最大的技术亮点并非参数规模(仍为1.6万亿),而是自研的“动态层归一化”(Dynamic Layer Normalization,DLN),传统LN的缩放因子和偏移因子是全局固定的,而DLN通过引入注意力机制,让每个神经元根据输入数据的特征动态调整这两个参数,实验数据显示,DLN使模型在多轮对话任务中的上下文保持能力提升27%,同时将训练时的内存占用降低了35%。
“这就像给每个神经元装了一个‘智能调节阀’。”文心团队首席架构师王伟解释,“以前所有神经元共用一套参数,现在每个神经元都能根据输入内容‘独立思考’,既提升了灵活性,又减少了冗余计算。”据悉,DLN已应用于百度搜索、文心一言等核心产品,用户感知最明显的是长文本处理速度变快——以前生成一篇3000字的报告需要12秒,现在只需8秒。
案例2:Meta的“分布式LN”突破算力瓶颈
Meta在2026年5月发布的Llama 4中,首次尝试将LN计算从单个GPU分散到多个GPU上,传统LN需要在每个训练步骤中同步所有GPU的统计量,当模型规模扩大时,通信开销会成为瓶颈,Meta的解决方案是将LN的缩放和偏移计算拆解为多个子任务,分配到不同GPU上并行处理,最后通过低延迟通信协议汇总结果,这一改动使Llama 4在10万张A100显卡集群上的训练效率提升了22%,成为首个在两周内完成万亿参数模型训练的公开案例。
“这相当于把LN从‘独奏’变成了‘交响乐’。”Meta AI研究总监Sarah Chen打比方,“每个GPU负责一个声部,最后合奏出更和谐的旋律。”这一技术已被英伟达纳入其下一代DGX SuperPOD架构的推荐方案,预计将影响未来超算中心的设计逻辑。 全民健身与青少年科学素养及碳排放热度持续上升,相关产业迎来新机遇

案例3:OpenAI的“自适应LN”重新定义训练范式
本月网络公益与绿色供应链及生态修复热度持续上升,相关产业迎来新机遇 2026年8月,OpenAI在arXiv预印本平台发布了一项更激进的研究:完全抛弃传统LN的固定计算流程,改用神经网络动态生成缩放因子和偏移因子,这一方案被称为“自适应层归一化”(Adaptive Layer Normalization,ALN),实验中,ALN使GPT-6在代码生成任务上的通过率从78%提升至89%,同时将微调所需的数据量减少了60%。
“传统LN是‘规则驱动’,ALN是‘数据驱动’。”OpenAI首席科学家Ilya Sutskever在接受《MIT Technology Review》采访时表示,“就像从手工调参转向自动机器学习(AutoML),ALN让模型自己学会如何归一化。”尽管ALN的计算开销比传统LN高15%,但其在复杂任务上的性能优势使其成为高端模型的首选方案。
认知滞后:行业面临的深层挑战
尽管LN的重要性已被反复验证,但整个行业对其的认知仍存在显著滞后,这种滞后体现在三个层面:
学术研究与产业应用的脱节
2026年ACM(国际计算机学会)的调查显示,全球Top 50的AI实验室中,仅有23%将LN优化作为核心研究方向,而这一比例在头部企业中高达78%。“学术界还在讨论LN的理论性质,产业界已经在用LN解决实际问题。”清华大学计算机系教授张磊指出,“这种脱节导致很多基础研究成果无法快速转化为生产力。”
2025年发表在ICLR(国际学习表征会议)上的一篇论文提出了一种“低精度LN”方案,理论上可将计算开销降低50%,但直到2026年8月,仍没有企业将其应用于实际模型训练。“学术界喜欢追求理论完美,产业界更看重稳定性和兼容性。”一位不愿具名的企业AI负责人透露,“我们试过一次,结果训练过程中出现了数值溢出,整个项目差点延期。”

人才缺口:懂LN的工程师“一将难求”
LinkedIn 2026年发布的《全球AI人才报告》显示,“层归一化优化”已成为大模型领域最稀缺的技能之一,相关岗位的平均薪资比普通算法工程师高42%,全球范围内系统掌握LN优化技术的人才不足5000人,其中80%集中在中美两国的头部企业。
“我们招了三个月,只找到两个合适的候选人。”某国内大模型公司HR总监抱怨,“很多应聘者知道LN是什么,但问到如何优化计算效率、如何解决梯度消失问题时,就答不上来了。”这种人才缺口直接导致企业间的技术差距扩大——拥有专业LN团队的模型,训练效率比依赖通用方案的模型高30%以上。
开源生态的滞后:社区贡献集中于“上层”
本月广告营销与绿色建筑群及心理健康热度持续攀升,相关应用不断深化 尽管Hugging Face等开源平台拥有数万个预训练模型,但其中涉及LN优化的代码库不足5%,大多数开源贡献集中在模型架构、数据预处理等“上层”领域,而LN这种“底层”组件的优化往往被忽视。“大家更愿意分享‘炫酷’的新架构,而不是‘枯燥’的归一化方案。”Hugging Face联合创始人Clem Delangue坦言,“这导致中小企业很难获取先进的LN技术,只能依赖头部企业的公开论文慢慢追赶。”
改变从认知开始:LN优化的未来路径
面对LN带来的挑战与机遇,行业需要从认知层面进行系统性升级,这包括三个关键方向:
建立“LN-centric”的研发体系
传统的大模型研发以“架构设计”为核心,LN等组件被视为“附属品”,未来需要转向“LN-centric”的研发模式,将LN优化纳入模型设计的全流程,百度在文心5.0的研发中,专门成立了“归一化技术组”,负责协调架构、训练、部署等团队,确保LN方案与整体设计无缝衔接。“LN不再是‘事后调整’的工具,而是‘事前设计’的基准。”王伟强调。
推动产学研深度融合
学术界需要更关注产业界的实际需求,将研究重点从理论推导转向工程优化,可以与企业合作建立“LN优化联合实验室”,针对具体场景(如长文本处理、低