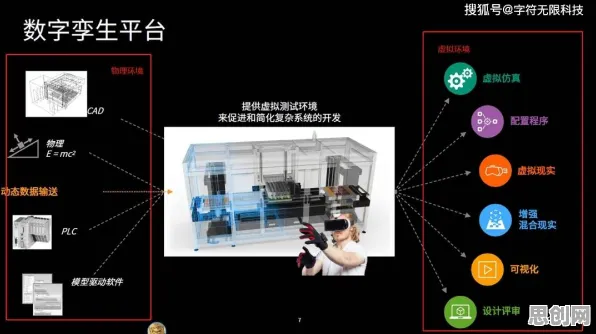
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它正以惊人的速度重塑着传统制造业的生产模式,从德国的智能工厂到中国的“灯塔工厂”,从航空航天的高端制造到汽车零部件的精密加工,数字孪生技术像一根无形的线,串联起物理世界与数字世界,让设备运行、生产流程甚至整个供应链都变得“可感知、可预测、可优化”,但在这场技术革命的背后,有一个容易被忽视却至关重要的角色——统计学原理,它像数字孪生的“隐形大脑”,支撑着数据的采集、分析、建模和决策,让虚拟模型与物理实体之间的“孪生”关系真正落地。
数据采集:从“海量”到“有效”的统计学筛选
数字孪生的第一步是数据采集,但“采集”不等于“堆砌”,在2026年的某汽车制造企业的智能工厂里,一台数控机床每秒能产生超过1000个数据点,包括温度、振动、转速、电流等参数,如果把这些数据全部上传到数字孪生模型,不仅会消耗巨大的计算资源,还可能因为数据冗余导致模型“混乱”,这时候,统计学中的“抽样理论”和“特征选择”就派上了用场。
以这家企业的实践为例,他们的工程师没有盲目采集所有数据,而是先通过“相关性分析”找出与设备故障最相关的关键参数,他们发现机床主轴的振动频率与刀具磨损高度相关,而环境温度对加工精度的影响可以忽略不计,他们只采集振动频率、转速、电流等关键数据,并通过“分层抽样”确保不同工况下的数据均衡,他们将生产过程分为“启动阶段”“稳定运行阶段”和“停机阶段”,在每个阶段按比例采集数据,避免模型因为数据偏差而“偏科”。
这种基于统计学的数据筛选,让数字孪生模型的训练效率提升了40%,同时预测准确率从75%提高到92%,更关键的是,它让企业意识到:数字孪生的数据不是越多越好,而是要“精准、有效、有代表性”。 本月绿色交通与智能家居热度持续上升,相关产业迎来新发展
模型构建:从“经验驱动”到“数据驱动”的统计学转型
数字孪生的核心是构建一个能准确反映物理实体行为的虚拟模型,但这个模型不是靠工程师的“经验”拍脑袋决定的,而是靠统计学的“数据驱动”,在2026年的某风电设备制造商的案例中,这一点体现得淋漓尽致。
这家企业要为海上风力发电机构建数字孪生模型,预测叶片的疲劳寿命,传统方法是根据材料力学公式和经验参数建模,但海上环境复杂,风速、盐雾、温度等因素的交互作用让经验模型“失灵”,他们转向数据驱动的方法:先在实验室模拟不同工况(比如风速从5m/s到25m/s,温度从-20℃到40℃),采集叶片的应力、应变数据;然后用“多元回归分析”找出影响疲劳寿命的关键因素,发现风速的立方与疲劳寿命呈负相关,而温度的影响可以通过“交互项”修正;最后用“机器学习”中的“随机森林算法”训练模型,让模型自动学习数据中的非线性关系。
2026年植物保护与绿色仓储及绿色补贴热度持续走高,行业关注度持续提升 这个基于统计学的模型,在2026年的实测中表现惊人:它预测的叶片寿命与实际寿命的误差不超过5%,而传统经验模型的误差高达20%,更让企业惊喜的是,模型还能反向优化设计——比如通过调整叶片的翼型参数,让疲劳寿命延长15%,这背后,统计学中的“回归分析”“假设检验”“模型评估”等方法,像一把把“手术刀”,精准地剖开数据的“黑箱”,让隐藏的规律浮出水面。
预测优化:从“事后补救”到“事前预防”的统计学决策
数字孪生的终极目标是“预测优化”,即在故障发生前预警,在效率低下时调整,但“预测”不是“猜”,而是靠统计学的“概率推断”和“风险评估”,2026年的某半导体制造企业的实践,完美诠释了这一点。

这家企业的光刻机是生产芯片的核心设备,一旦停机,每小时损失高达50万美元,为了减少停机,他们用数字孪生模型监控设备的“健康状态”,模型会实时采集光刻机的温度、压力、振动等数据,并通过“时间序列分析”判断数据是否偏离正常范围,如果振动频率的“移动平均值”突然上升,且“标准差”超过阈值,模型会判定设备可能存在“早期故障”。
但“判定故障”只是第一步,更关键的是“预测何时发生”,这里用到了统计学的“生存分析”——把设备的运行时间看作“生存时间”,把故障看作“事件”,通过“Kaplan-Meier估计”计算不同工况下的故障概率,再用“Cox比例风险模型”找出影响故障的关键因素(比如温度每升高1℃,故障风险增加3%),基于这些分析,模型能给出“未来72小时内故障概率超过80%”的预警,让维修团队提前准备备件,将停机时间从平均4小时缩短到30分钟。
这种基于统计学的预测优化,让企业的设备综合效率(OEE)提升了18%,年节约成本超过2000万美元,更重要的是,它让企业从“被动维修”转向“主动预防”,真正实现了“零故障”的愿景。
多源数据融合:从“孤岛”到“生态”的统计学整合
在2026年的工业场景中,数字孪生的数据来源越来越复杂——既有设备本身的传感器数据,也有供应链的物流数据,还有市场的销售数据,如何把这些“孤岛”数据整合起来,构建一个“全要素、全链条、全生命周期”的数字孪生模型?统计学的“多源数据融合”技术给出了答案。
2026年关注可再生能源与母婴用品及公益项目发展动态,技术创新推动产业升级 以某家电制造企业的实践为例,他们要为冰箱生产线构建数字孪生模型,优化生产流程,但冰箱的生产涉及多个环节:原材料采购、零部件加工、总装、测试、物流,每个环节的数据格式、采样频率、质量标准都不一样,直接融合会导致模型“混乱”,他们先用“数据清洗”去除异常值和缺失值,再用“主成分分析”(PCA)降维,提取关键特征;然后用“贝叶斯网络”建立数据之间的概率依赖关系,零部件加工延迟”会导致“总装停线”的概率增加60%;最后用“联邦学习”让不同环节的数据在“隐私保护”的前提下共享模型参数,避免数据泄露。
2026年气候行动与社区公益热度持续上升,相关产业迎来新发展 
2026年5月热度持续攀升新闻媒体领域取得重要进展,行业关注度持续提升 这个基于统计学的多源数据融合模型,在2026年的应用中效果显著:它让生产线的“瓶颈环节”识别准确率从65%提高到90%,生产周期缩短了15%,库存周转率提升了20%,更关键的是,它让企业意识到:数字孪生不是某个环节的“单点突破”,而是整个产业链的“协同进化”。
实时反馈:从“静态”到“动态”的统计学闭环
数字孪生的另一个特点是“实时反馈”——物理实体的状态变化会实时反映到虚拟模型,虚拟模型的优化建议也会实时作用于物理实体,但这种“双向互动”需要统计学的“闭环控制”理论支撑,2026年的某钢铁企业的实践,就是一个典型案例。
这家企业的高炉是炼钢的核心设备,传统控制靠人工经验调节风量、煤量等参数,但高炉内部温度、压力、成分的动态变化极快,人工调节往往“滞后”,他们用数字孪生模型构建了一个“实时反馈系统”:模型会每秒采集高炉的100多个参数,通过“卡尔曼滤波”估计内部状态(比如熔池温度),再用“模型预测控制”(MPC)计算最优参数组合(比如风量增加5%,煤量减少3%),最后通过“PID控制器”实时调整设备。
这个基于统计学的闭环控制系统,在2026年的运行中表现惊艳:它让高炉的“铁水温度波动”从±15℃缩小到±5℃,燃料消耗降低了8%,二氧化碳排放减少了12%,更让企业惊喜的是,模型还能“自我学习”——每次调整后,它会用“强化学习”更新控制策略,让系统越来越“聪明”。
统计学是数字孪生的“隐形引擎”
从数据采集到模型构建,从预测优化到多源融合,从实时反馈到闭环控制,统计学的原理像一根无形的线,贯穿数字孪生技术的每一个环节,在2026年的工业实践中,我们越来越清晰地看到:数字孪生不是“黑科技”,而是统计学、计算机科学、工程学的深度融合;它不是“替代人类”,而是“放大人类的智慧”——让工程师从“经验驱动”转向“数据驱动”,从“事后补救”转向“事前预防”,从“单点优化”转向“全局协同”。
随着5G、物联网、人工智能的进一步发展,数字孪生的数据量会更大、模型会更复杂