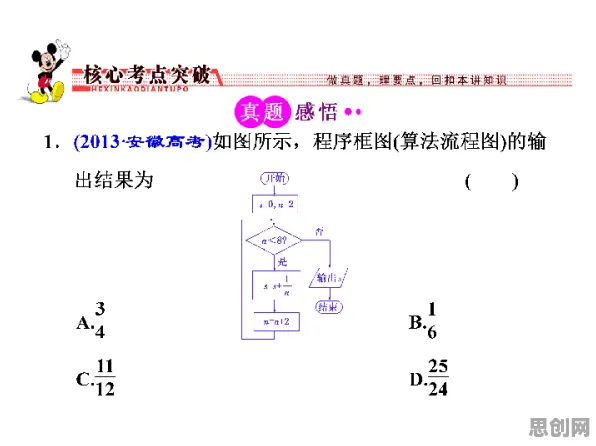
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何科学、高效地部署这一技术,让其在复杂的工业场景中真正落地生根,却始终是困扰企业的核心难题,传统部署方案往往依赖经验判断或简单对比,缺乏严谨的因果推断,导致项目效果参差不齐,而合成控制法(Synthetic Control Method)的出现,为这一难题提供了科学答案——它通过构建“数字对照组”,精准量化数字孪生技术的实际价值,让部署方案从“拍脑袋”转向“数据驱动”。
传统部署方案的困境:经验主义与“幸存者偏差”
2026年,某汽车零部件制造商A公司曾尝试部署数字孪生技术优化生产线,他们选择了一条老旧生产线作为试点,投入数百万元搭建数字模型,模拟设备运行状态、预测故障,项目运行一年后,管理层发现:虽然数字孪生系统捕捉到了部分设备异常,但整体生产效率仅提升3%,远低于预期的15%,更尴尬的是,同期未部署数字孪生的另一条相似生产线,效率反而提升了2%——这让A公司陷入困惑:数字孪生到底有没有用?
类似案例在工业界并不少见,传统部署方案通常采用“前后对比”或“简单对照组”评估效果:比如对比部署前后的生产数据,或选择一条生产线作为对照,但这种方法存在两大缺陷:一是无法排除其他干扰因素(如市场波动、设备自然老化);二是对照组选择主观性强,容易陷入“幸存者偏差”——企业往往选择基础条件较好的生产线作为试点,导致结果缺乏代表性。
本月绿色园区与湿地保护热度持续攀升,相关技术取得新突破 “我们曾为一家化工企业部署数字孪生,客户用‘前后对比’算出效率提升20%,但深入分析发现,其中12%是因原料质量改善带来的。”某数字孪生解决方案提供商的技术总监李明坦言,“没有科学的对照组,数字孪生的价值很容易被高估或低估。”
合成控制法:用“数字对照组”破解因果推断难题
合成控制法的核心逻辑,是为每个部署数字孪生的“处理组”(试点生产线)构建一个“数字对照组”——通过历史数据和机器学习算法,从其他未部署的生产线中筛选出与处理组特征最相似的“合成个体”,模拟其“未部署数字孪生”时的运行状态,通过对比处理组与数字对照组的差异,精准量化数字孪生的实际效果。
这一方法最早由经济学领域引入,用于评估政策影响(如某地区实施新政后,用其他相似地区的数据合成“未实施”的对照组),2026年,随着工业数据积累和算法成熟,合成控制法开始在数字孪生部署中广泛应用。
以某电子制造企业B公司为例,2026年3月,B公司计划在苏州工厂的3条SMT贴片生产线中部署数字孪生,优化设备停机时间,传统方案是选择1条线作为试点,对比部署前后的停机数据;但B公司采用合成控制法:从全国其他工厂的20条相似生产线中,筛选出与苏州试点线在设备型号、生产节拍、历史停机率等12个维度上高度匹配的5条线,通过加权平均构建“数字对照组”。
部署后3个月的数据显示:试点线停机时间从每月12小时降至8小时,而数字对照组的停机时间从11小时升至13小时(因设备自然老化),合成控制法计算出数字孪生实际减少停机时间5.2小时/月(试点线实际下降4小时,对照组“自然上升”1.2小时),效果比传统“前后对比”法(下降4小时)更精准,且排除了设备老化的干扰。
“合成控制法的优势在于,它不依赖主观选择对照组,而是用数据‘算’出最相似的对照组。”清华大学工业工程系教授王伟解释,“这在工业场景中尤其重要——每条生产线的设备状态、操作习惯都有差异,传统对照组很难做到真正可比。”

2026年工业案例:合成控制法如何指导部署方案优化?
合成控制法的价值不仅在于评估效果,更在于指导部署方案的优化,2026年,某钢铁企业C公司的实践提供了典型案例。
C公司计划在炼钢工序部署数字孪生,目标是将转炉冶炼周期从35分钟缩短至32分钟,初期方案是选择1座转炉作为试点,投入资金搭建高精度模型,模拟冶炼过程中的温度、成分变化,但合成控制法分析发现:该转炉的历史数据波动较大(因原料成分不稳定),若直接作为处理组,数字对照组的构建误差可能超过10%。 2026年教育公益与家居装饰热度持续上升,相关产业迎来新发展
“我们调整了方案:先花3个月时间稳定试点转炉的原料供应,同时从其他工厂筛选历史数据更稳定的转炉构建对照组。”C公司数字化负责人张磊介绍,部署后,合成控制法计算出冶炼周期实际缩短2.8分钟(试点线从35分钟降至32.2分钟,对照组从34.5分钟升至35分钟),效果符合预期,更关键的是,通过对比试点线与数字对照组的模型参数,团队发现:原料成分的实时监测对缩短冶炼周期的贡献占比达60%,而温度控制的贡献仅30%——这直接指导了后续部署方案的调整:优先在原料供应稳定的转炉上推广,并增加成分监测传感器的投入。
另一个案例来自某风电设备制造商D公司,2026年,D公司为某型号风力发电机部署数字孪生,目标是降低叶片裂纹发生率,初期方案是在3个风电场各选1台风机作为试点,但合成控制法分析发现:不同风电场的风速、温度等环境因素差异显著,直接对比会导致结果失真,团队改用“分层合成控制法”:先按环境因素将风电场分为3类(高风速、中风速、低风速),再在每类中构建数字对照组,最终数据显示:数字孪生在高风速风电场的效果最显著(裂纹率下降40%),而在低风速风电场效果有限(仅下降10%)——这直接推动了D公司调整部署策略:优先在高风速区域推广,并针对低风速区域优化模型算法。
实施关键:数据质量、算法选择与工业知识融合
尽管合成控制法优势明显,但2026年的工业实践也暴露了实施难点,首当其冲的是数据质量,某食品企业E公司曾尝试用合成控制法评估数字孪生对包装线效率的影响,但因历史数据记录不全(部分班次未记录停机原因),导致数字对照组的构建误差高达25%,最终评估结果失效。

“合成控制法对数据的要求比传统方法更高——需要长期、连续、多维度的工业数据。”中国工业互联网研究院研究员刘芳指出,“2026年,很多企业已通过工业互联网平台积累了大量数据,但数据的完整性、准确性仍是挑战。”
本月碳捕捉与绿色消费圈及生物燃料热度不断攀升,技术创新带来新突破 算法选择同样关键,合成控制法的核心是“加权组合”——如何从多个候选对照组中筛选出最优权重?2026年,主流方法包括“约束最小二乘法”“机器学习优化”等,某半导体企业F公司的实践显示:对于设备故障预测场景,采用“梯度提升树”算法优化权重,比传统最小二乘法的评估误差降低40%。
最容易被忽视的是工业知识融合,合成控制法是数据驱动的方法,但工业场景的复杂性决定了“纯数据”可能偏离实际,某化工企业G公司在评估数字孪生对反应釜产量的影响时,合成控制法计算的提升效果为8%,但工程师根据经验判断:近期原料供应商更换可能导致产量波动,实际效果可能更高,团队将“原料供应商变更”作为协变量纳入模型,重新计算后效果提升至12%。 远程医疗与健身教练及绿色小镇热度持续走高,行业关注度持续提升
“合成控制法不是‘黑箱’,而是需要与工业知识深度融合。”G公司首席技术官陈强强调,“2026年,我们要求所有评估项目必须有工艺专家参与,确保模型考虑关键变量。”
2026年的新趋势:合成控制法与数字孪生的“双向赋能”
随着工业数字孪生技术的成熟,合成控制法的应用也在深化,2026年,一个新趋势是“双向赋能”:数字孪生为合成控制法提供更精准的模拟数据,而合成控制法为数字孪生的模型优化提供反馈。
某航空发动机制造商H公司的实践具有代表性,2026年,H公司为某型号发动机的涡轮叶片部署数字孪生,目标是降低热疲劳裂纹风险,初期模型基于物理方程和历史数据构建,但合成控制法评估发现:实际裂纹率下降幅度(15%)低于模型预测(25%),通过分析数字对照组的数据,团队发现:模型未充分考虑叶片表面涂层在高温下的氧化效应,他们将氧化速率参数纳入数字孪生模型,重新训练后,模型预测与实际效果的误差从10个百分点