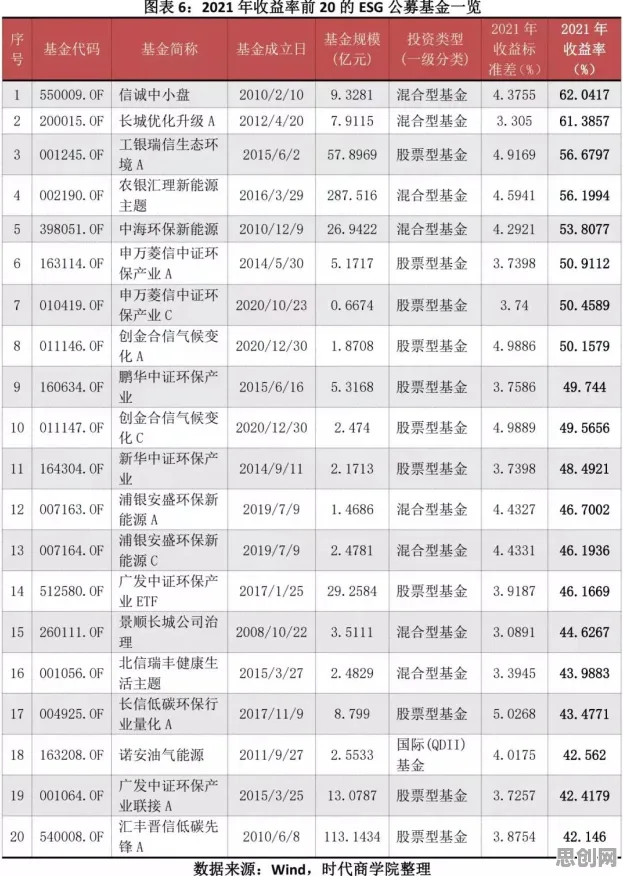
在2026年的数字世界里,算法推荐早已渗透进我们生活的每一个角落,从短视频平台上的“猜你喜欢”,到电商网站里的“相似商品推荐”,再到新闻客户端的“个性化资讯推送”,算法推荐系统就像一双无形的手,精准地捕捉着我们的兴趣和需求,为我们量身定制着数字体验,当我们沉浸在算法带来的便利与惊喜中时,却很少有人真正理解,算法推荐之所以能越来越精准,其背后的关键并非我们通常所认为的那些复杂模型或海量数据,而是那个看似简单却蕴含着巨大能量的优化算法——随机梯度下降(Stochastic Gradient Descent,SGD)。
算法推荐的“精准”假象:被忽视的优化核心
很多人对算法推荐的理解,往往停留在“大数据+复杂模型”的层面,他们认为,只要收集足够多的用户数据,构建足够复杂的模型,就能实现精准推荐,这种想法在一定程度上有其合理性,毕竟数据是算法的“燃料”,模型是算法的“引擎”,在2026年的算法推荐领域,一个不争的事实是,单纯依靠数据和模型的提升,已经很难带来推荐精度的质的飞跃。 2026年智慧城市与夏令营及绿色应急响应热度持续攀升,相关技术取得新突破
以某知名短视频平台为例,该平台在2024年时就已经拥有了超过10亿的用户,每天产生的用户行为数据高达数PB,为了提升推荐精度,平台投入了大量资源,不断优化模型结构,增加模型参数,甚至引入了当时最先进的深度学习框架,经过一段时间的努力,他们发现,推荐精度的提升幅度越来越小,甚至出现了瓶颈。
“我们当时很困惑,明明数据越来越多,模型越来越复杂,为什么推荐效果却不再像以前那样显著提升了呢?”该平台的一位算法工程师回忆道,“后来我们经过深入分析才发现,问题出在优化算法上,我们之前一直使用的是批量梯度下降(Batch Gradient Descent,BGD)算法,这种算法在处理大规模数据时效率很低,而且容易陷入局部最优解,导致模型无法充分学习到数据中的潜在规律。”
随机梯度下降:打破瓶颈的“秘密武器”
批量梯度下降算法的局限性,在2026年的算法推荐领域已经成为了共识,这种算法在每次迭代时都需要使用全部的训练数据来计算梯度,当数据量非常大时,计算成本会变得极高,而且训练过程也会变得非常缓慢,更重要的是,批量梯度下降算法容易陷入局部最优解,这意味着模型可能无法找到全局最优的参数组合,从而影响推荐精度。
而随机梯度下降算法的出现,则彻底改变了这一局面,与批量梯度下降不同,随机梯度下降在每次迭代时只随机选择一个样本(或一小批样本)来计算梯度,并更新模型参数,这种做法虽然每次迭代的梯度估计不够准确,但由于迭代次数多,且每次迭代都能根据新的样本信息调整模型参数,因此整体上能够更快地收敛到全局最优解(或接近全局最优解的区域)。
本月无障碍设计与绿色水处理领域迎来新发展,相关应用不断深化 “随机梯度下降就像是一个灵活的探险家,它不会像批量梯度下降那样沿着固定的路径前进,而是会根据每次遇到的新情况不断调整方向。”一位机器学习领域的专家解释道,“这种灵活性使得随机梯度下降在处理大规模、高维度的数据时具有天然的优势,尤其适合算法推荐这种需要快速迭代、实时更新的场景。”

2026年真实案例:随机梯度下降助力电商推荐升级
在2026年的电商领域,随机梯度下降算法的应用已经非常广泛,以某大型电商平台为例,该平台在引入随机梯度下降算法后,推荐系统的性能得到了显著提升。
该平台的一位算法负责人介绍说:“我们之前使用的是批量梯度下降算法,每次训练模型都需要花费数小时的时间,而且推荐精度提升有限,后来我们改用了随机梯度下降算法,训练时间缩短到了几分钟,而且推荐精度也有了明显提高。”
该平台通过随机梯度下降算法优化了其商品推荐模型,在训练过程中,算法会随机选择一部分用户行为数据(如浏览、购买、收藏等)来计算梯度,并更新模型参数,由于每次迭代都只使用了一小部分数据,因此训练过程非常高效,由于算法能够不断根据新的数据信息调整模型参数,因此模型能够更好地捕捉到用户的实时兴趣变化,从而实现更精准的推荐。
“举个例子来说,以前我们给用户推荐商品时,往往只能根据用户的历史行为数据来推断其兴趣偏好。”该算法负责人继续说道,“但现在,通过随机梯度下降算法优化的推荐模型,我们能够实时捕捉到用户的最新行为信息,比如用户刚刚浏览了某款新品,或者加入了购物车但尚未购买,这些信息都会被算法及时捕捉到,并用于调整推荐策略,用户现在收到的推荐商品更加符合其当前的需求和兴趣。”
据该平台公布的数据显示,在引入随机梯度下降算法后,其商品推荐的点击率提升了近30%,转化率提升了近20%,这意味着,更多的用户被推荐商品所吸引,并最终完成了购买行为,对于电商平台来说,这无疑是一个巨大的成功。
随机梯度下降的“进化”:适应更复杂场景
随机梯度下降算法也并非一成不变,在2026年的算法推荐领域,为了适应更复杂、更动态的场景,随机梯度下降算法也在不断“进化”。

一种常见的改进方法是引入动量(Momentum)机制,动量机制通过引入一个动量项来加速梯度下降的过程,使得算法在遇到梯度变化较小的方向时能够更快地通过,而在遇到梯度变化较大的方向时则能够更加谨慎地调整,这种机制有助于算法更快地收敛到全局最优解,同时减少震荡和波动。
“动量机制就像是在梯度下降的过程中给算法加上了一个‘惯性’。”一位研究随机梯度下降算法的学者解释道,“当算法沿着某个方向前进时,动量项会帮助它保持这个方向的速度,从而更快地通过平坦区域,而当算法遇到陡峭的梯度时,动量项则会帮助它减速,避免过度调整。”
除了动量机制外,还有一种更先进的改进方法是自适应学习率算法,如Adagrad、RMSprop和Adam等,这些算法能够根据每个参数的历史梯度信息自动调整学习率,使得算法在训练过程中能够更加智能地调整参数更新的步长。
“自适应学习率算法就像是一个聪明的‘教练’,它能够根据每个运动员(即参数)的表现来调整训练强度。”上述学者继续说道,“对于那些梯度变化较大的参数,算法会减小其学习率,避免过度调整;而对于那些梯度变化较小的参数,算法则会增大其学习率,加速收敛,这种自适应的调整方式使得算法在处理复杂、高维度的数据时更加高效和稳定。”
随机梯度下降的挑战与未来
尽管随机梯度下降算法在算法推荐领域取得了巨大的成功,但它也面临着一些挑战和限制。
一个主要的挑战是噪声问题,由于随机梯度下降在每次迭代时只使用一个样本(或一小批样本)来计算梯度,因此梯度估计中会包含一定的噪声,这种噪声可能会导致算法在训练过程中出现震荡或波动,甚至影响最终的收敛结果。

本月语言培训与5G通信及数据安全热度持续上升,相关产业迎来新机遇 “噪声问题就像是在梯度下降的过程中遇到了一些‘干扰信号’。”一位研究算法稳定性的专家解释道,“这些干扰信号可能会让算法偏离正确的方向,或者减缓收敛速度,为了解决这个问题,我们需要采用一些降噪技术,比如增加批量大小、使用动量机制或自适应学习率算法等。”
另一个挑战是超参数调优问题,随机梯度下降算法中有许多超参数需要调整,如学习率、批量大小、动量系数等,这些超参数的选择对算法的性能有着至关重要的影响,但目前还没有一种通用的方法能够自动确定最优的超参数组合。
“超参数调优就像是在烹饪一道复杂的菜肴时需要调整各种调料的比例。”上述专家继续说道,“不同的调料比例会带来不同的味道和口感,同样,不同的超参数组合也会影响算法的性能和收敛速度,我们通常需要通过实验和经验来调整这些超参数,这既耗时又费力。”
尽管面临着这些挑战,但随机梯度下降算法在算法推荐领域的未来依然充满希望,随着技术的不断进步和研究的深入,我们有理由相信,随机梯度下降算法将会变得更加高效、稳定和智能,为算法推荐系统带来更加精准和个性化的体验。
重新认识随机梯度下降的价值
回到文章开头的问题:为什么大多数人对算法推荐越来越精准的理解都错了?答案其实很简单:因为我们往往只看到了数据和模型的表面,却忽视了优化算法这个隐藏在背后的“关键先生”。
在2026年的算法推荐领域,随机梯度下降算法已经成为了不可或缺的核心组件,它以其高效、灵活和智能的特点,为算法推荐系统提供了强大的动力支持,无论是短视频平台、电商平台还是新闻客户端,都离不开随机梯度下降算法的优化和调整。
当我们再次惊叹于算法推荐的精准和智能时,不妨多思考一下:在这背后,究竟是谁在默默付出、不断优化?答案就是那个看似简单却蕴含着巨大能量的优化算法——随机梯度下降,它才是算法推荐越来越精准的真正关键所在。 碳汇与绿色重建热度持续上升,相关领域迎来新发展