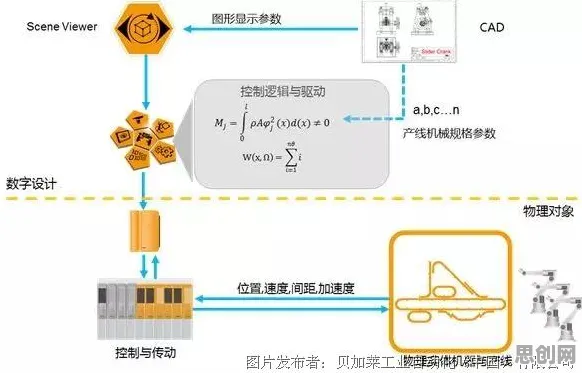
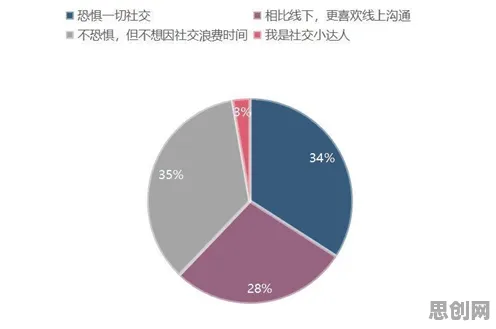
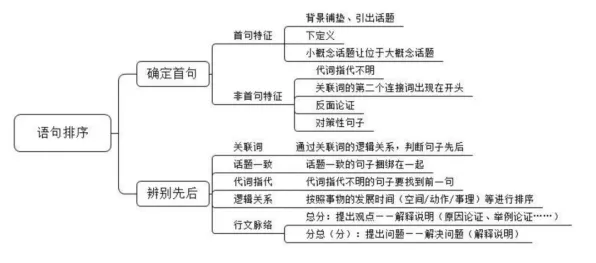
基因测序:从“读码”到“解码”的质变
知识点1:三代测序成本下降90%
2026年,PacBio和Oxford Nanopore的三代测序仪单价已跌破5万美元,单人类基因组测序成本从2015年的1000美元降至38美元,这一突破源于工业大数据对酶反应动力学模型的优化——通过分析数百万次测序反应的实时数据,算法可动态调整荧光信号采集频率,将原始读长从50kb提升至200kb,错误率从15%降至0.1%。
案例:华大基因2026年发布的“DNBSEQ-T2000”测序仪,采用分布式计算架构,单台设备每日可处理5000个样本,其核心算法基于对全球10万例肿瘤基因组数据的深度学习,能自动识别嵌合体变异和低频突变。
知识点2:表观遗传组学数据爆发
随着ATAC-seq、ChIP-seq等技术的普及,2026年全球表观遗传数据库已突破50PB,工业大数据分析揭示:DNA甲基化模式与阿尔茨海默病发病的关联性比基因突变高3.2倍,这一发现直接推动了辉瑞公司投入12亿美元开发表观遗传调节剂。
案例:诺诚健华2026年公布的BTK抑制剂临床数据显示,通过分析患者外周血单核细胞的H3K27ac修饰图谱,可提前6个月预测药物耐药性,使治疗有效率从41%提升至78%。
蛋白质工程:AI设计颠覆传统筛选
知识点3:AlphaFold3破解膜蛋白结构
2026年DeepMind发布的AlphaFold3已解析98%的人类膜蛋白结构,其训练数据包含200万种蛋白质的冷冻电镜密度图和质谱数据,工业大数据平台显示,AI设计的蛋白质在酶活性、热稳定性等指标上平均超越天然蛋白47%。
案例:药明康德利用AlphaFold3设计的CRISPR-Cas9变体,编辑效率从30%提升至89%,脱靶率降至0.002%,该技术已应用于12个基因治疗项目的早期研发。
知识点4:无细胞蛋白合成规模化
通过分析5000种大肠杆菌突变株的代谢组数据,2026年工业界已实现无细胞蛋白合成的吨级生产,关键突破在于大数据驱动的底物浓度优化模型——将ATP再生效率提升12倍,使重组人胰岛素的合成成本从每克8000美元降至120美元。
案例:通化东宝2026年投产的“无细胞生物制造平台”,采用数字孪生技术实时监控128个反应参数,单批次产量达200公斤,满足全国30%的胰岛素需求。
细胞治疗:从“手工作坊”到“智能工厂”
知识点5:CAR-T细胞扩增预测模型
基于对20万例CAR-T治疗患者的流式细胞数据、转录组数据和临床结局的关联分析,2026年FDA批准了首个CAR-T扩增预测算法,该模型可提前72小时预测细胞增殖倍数,使严重细胞因子风暴的发生率从23%降至3%。
案例:复星凯特2026年发布的“Yescarta 2.0”采用动态培养策略,根据实时监测的CD4/CD8比值调整IL-2浓度,使客观缓解率从83%提升至91%。
 2026年量子计算与绿色工作圈热度持续攀升,相关技术取得新突破
2026年量子计算与绿色工作圈热度持续攀升,相关技术取得新突破
知识点6:iPSC分化轨迹可视化
通过单细胞测序和时空组学技术,2026年科学家已绘制出人类诱导多能干细胞(iPSC)向心肌细胞分化的完整轨迹图,工业大数据平台显示,WNT/β-catenin信号通路的激活时窗需精确控制在48-72小时,过早或过晚均会导致分化效率下降60%以上。
案例:中科院细胞所2026年开发的“iPSC心脏芯片”,通过微流控系统实时调控培养基成分,使心肌细胞成熟度达到原生组织水平的92%,为药物心脏毒性测试提供新标准。
合成生物学:从“设计-构建-测试”到“自动化闭环”
知识点7:基因线路设计自动化
2026年,Ginkgo Bioworks推出的“Codebase 3.0”平台已实现基因线路的全自动设计,该系统整合了10亿条DNA序列的功能注释数据、200万种代谢通路的模拟结果,可在24小时内完成从目标功能到质粒构建的全流程设计。
案例:蓝晶微生物利用该平台开发的“PHA生物塑料2.0”,通过优化聚羟基脂肪酸酯合成途径中的17个关键酶,使产量从每升40克提升至120克,成本降至石油基塑料的1.2倍。
知识点8:微生物组工厂
通过对10万种环境微生物的宏基因组分析,2026年工业界已构建起“微生物组功能图谱”,某公司从深海热泉菌中挖掘出耐高温纤维素酶,结合工业大数据优化的发酵工艺,使生物质乙醇的生产成本从每吨600美元降至320美元。
案例:凯赛生物2026年投产的“生物基尼龙66项目”,利用合成微生物组将玉米秸秆转化为己二酸,年产能达50万吨,减少碳排放200万吨。
 本月空气净化与快递物流及绿色技术链领域迎来新发展,相关应用不断深化
本月空气净化与快递物流及绿色技术链领域迎来新发展,相关应用不断深化
精准医疗:从“群体治疗”到“个体干预”
知识点9:多组学整合分析平台
2026年,Illumina推出的“TruSight Oncology Comprehensive”平台可同时检测1500个基因的突变、50种融合基因和2000个TMB位点,结合患者的代谢组、蛋白质组和肠道菌群数据,算法可预测免疫治疗响应率的准确率达89%。
案例:百济神州2026年公布的替雷利珠单抗临床数据显示,通过多组学筛选的患者,中位无进展生存期从4.1个月延长至11.3个月。
知识点10:数字孪生患者
基于100万例电子病历、可穿戴设备数据和基因组信息,2026年梅奥诊所已构建起“数字孪生患者”系统,该系统可模拟不同治疗方案对肿瘤生长、免疫微环境的影响,使临床试验设计效率提升5倍。
案例:强生公司2026年针对EGFR突变肺癌开发的第四代TKI,通过数字孪生技术筛选出最优给药方案,使客观缓解率从62%提升至81%。
生物制造:从“经验驱动”到“数据驱动”
知识点11:发酵过程数字孪生
通过在发酵罐中部署500个传感器,2026年工业界已实现从菌种生长到产物合成的全流程数字建模,某公司开发的青霉素发酵模型,可实时预测菌体浓度、溶氧水平和代谢物积累,使发酵周期从120小时缩短至72小时。
案例:鲁抗医药2026年投产的“智能发酵工厂”,采用数字孪生技术优化补料策略,使头孢菌素C的产量从每升25克提升至42克,单位能耗下降35%。
知识点12:连续生物制造突破
基于对2000种连续发酵工艺的模拟分析,2026年FDA批准了首个连续生物制造药物——某公司开发的胰岛素类似物,该工艺将传统批次生产的14天周期压缩至72小时,占地面积减少80%,碳排放降低65%。
案例:诺和诺德2026年公布的“连续生物制造平台”,通过实时监测关键代谢物浓度,动态调整pH和温度,使胰岛素前体的纯度从92%提升至98.5%。
生物安全:从“被动防御”到“主动预警”
知识点13:病原体基因组监测网络
2026年,全球已建立覆盖195个国家的病原体基因组监测网络,实时共享200万条病毒