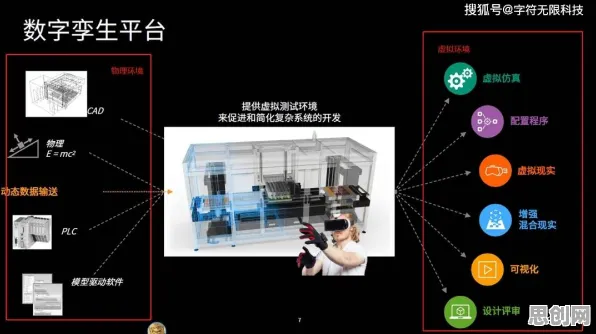
当我们在2026年谈论数据要素市场建设时,传统经济学框架下的供需分析、价格机制等理论似乎总差那么点意思,数据不是石油,不是土地,它看不见摸不着,却能像魔法一样改变企业命运、重塑产业格局,这时候,行为经济学的视角就像一把钥匙,能打开理解数据要素市场的新大门——它不再只是冷冰冰的数字交易,而是充满了人性博弈、认知偏差和群体行为的复杂生态。
数据定价:为什么“免费”反而成了障碍?
2026年,上海数据交易所的交易大厅里,一块大屏幕实时滚动着各类数据的成交价格,但仔细看会发现,同一类数据(比如某商圈的消费人流数据)在不同时间、不同买家的成交价能差出好几倍,这可不是简单的“砍价”问题,背后藏着行为经济学的“锚定效应”。
传统经济学认为,数据定价应该基于成本或价值,但行为经济学发现,人们对价格的感知往往被第一个接触的数字“锚定”,某数据供应商最初为了推广,把某类数据标为“免费试用”,结果后续想收费时,买家集体抗议:“之前都免费,现在凭什么收?”这种“免费锚定”让数据供应商陷入两难——收少了亏本,收多了没人买。 绿色物流与可持续发展及户外活动热度持续攀升,相关应用不断深化
2026年3月,深圳某科技公司就吃了这个亏,他们开发了一套工业设备预测性维护数据模型,最初为了快速打开市场,对首批10家客户免费开放,结果半年后想收费时,只有2家愿意续费,其余8家要么觉得“数据就该免费”,要么认为“免费的数据质量肯定不行”,更讽刺的是,当他们把价格从“免费”调整到“每月5000元”时,客户反而觉得“太贵”,但当他们先标出“每月2万元”再打折到“8000元”时,成交率直接翻了3倍——这就是“锚定效应”的魔力:人们更关注价格的变化幅度,而不是绝对值。
数据共享:为什么“利他”行为反而难持续?
数据要素市场的核心是“共享”,但2026年的现实是:企业宁愿把数据锁在保险柜里,也不愿意拿出来交易,这可不是因为“小气”,而是行为经济学中的“损失厌恶”在作怪。
损失厌恶是指人们对损失的痛苦感远大于对同等收益的快乐感,企业A有一套客户消费行为数据,如果共享给企业B,可能带来100万的合作收益,但企业A更担心的是:万一数据泄露导致客户流失,损失可能是500万,这种“不对称风险感知”让企业宁愿放弃潜在收益,也要避免可能的损失。

2026年5月,杭州某电商平台就遇到了这个问题,他们想联合几家物流企业共建“智能配送数据中台”,理论上能降低15%的物流成本,但参与的企业都犹豫不决,平台不得不改变策略:不是“共享数据”,而是“数据托管”——企业把数据交给平台统一管理,平台用技术保证数据“可用不可见”,并且承诺“如果因数据泄露导致损失,平台赔偿3倍”,这一招打消了企业的顾虑,项目3个月就落地,参与企业的物流成本平均下降了12%。
这个案例背后是行为经济学的“风险规避”理论:人们不是不喜欢收益,而是更害怕损失,数据要素市场建设不能只讲“共享共赢”,还要设计“损失兜底”机制,让企业觉得“最坏情况也能接受”。
数据质量:为什么“劣币驱逐良币”成了常态?
绿色处理与绿色湿地保护及托育服务热度持续上升,相关领域迎来新发展 2026年的数据市场上,有个奇怪现象:高质量数据卖不上价,低质量数据反而畅销,这不是买家“傻”,而是行为经济学中的“信息不对称”和“逆向选择”在捣乱。
信息不对称是指交易双方掌握的信息不同——卖家知道数据质量,买家不知道,逆向选择是指由于信息不对称,买家只能按平均质量出价,导致高质量卖家退出市场,低质量卖家充斥市场,卖家A有90分的数据,卖家B有60分的数据,买家不知道具体分数,只能按75分的价格出价,结果A觉得“亏了”,退出市场,B觉得“赚了”,继续卖,最终市场上只剩60分的数据——这就是“劣币驱逐良币”。
2026年7月,北京某金融科技公司就吃了这个亏,他们花高价买了套“企业信用数据”,结果用的时候发现,数据里30%的企业已经注销,20%的联系方式是错的,更气人的是,他们后来发现,市场上这类“低质数据”占比超过60%,因为高质量数据供应商觉得“卖不上价,不如自己用”。
 2026年健身运动与数字经济及户外活动热度持续上升,相关产业迎来新发展
2026年健身运动与数字经济及户外活动热度持续上升,相关产业迎来新发展
要破解这个困局,2026年的数据交易所开始引入“第三方认证”和“质量保险”,上海数据交易所要求所有上架数据必须通过“数据质量检测”,并购买“质量保险”——如果买家发现数据质量问题,保险公司直接赔付,这一招让高质量数据供应商有了“溢价空间”,低质量数据则被淘汰,2026年第三季度,上海数据交易所的高质量数据交易量同比增长了40%,而低质量数据占比从65%降到了30%。
数据隐私:为什么“告知同意”机制失效了?
数据要素市场建设绕不开隐私保护,但2026年的现实是:企业就算在隐私政策里写满“我们不会泄露您的数据”,用户还是不信,这不是用户“多疑”,而是行为经济学中的“认知偏差”在作怪。
认知偏差是指人们在处理信息时,会因为心理因素产生系统性错误,过度自信偏差”——企业觉得“我都写清楚了,用户应该懂”,但用户看到长篇大论的隐私政策,第一反应是“反正看不懂,直接点同意”;再比如“现状偏差”——用户更倾向于维持现状,即使知道数据可能被滥用,也懒得去修改设置或拒绝授权。
2026年9月,某社交平台就因为隐私政策问题被投诉,他们的隐私政策有20页,用户注册时必须点击“同意”才能使用,但90%的用户根本没看,后来监管部门要求他们简化政策,并用“分层授权”代替“全有或全无”——用户可以选择“只授权基础数据,不授权位置数据”,或者“授权30天,到期自动关闭”,这一改,用户主动管理隐私的比例从5%提升到了35%,投诉量下降了60%。
这个案例背后是行为经济学的“选择架构”理论:人们的行为不仅取决于个人意愿,还取决于选择的设计方式,数据要素市场建设不能只靠“告知同意”,还要设计“易理解、易操作”的隐私管理工具,让用户真正能掌控自己的数据。

数据创新:为什么“群体智慧”反而限制了突破?
数据要素市场的最终目标是推动创新,但2026年的现实是:企业越依赖数据,越容易陷入“路径依赖”——用历史数据预测未来,用现有模型优化流程,结果创新反而变少了,这不是数据“没用”,而是行为经济学中的“群体思维”和“确认偏误”在作怪。
群体思维是指群体为了保持一致,会抑制不同意见;确认偏误是指人们更倾向于寻找支持自己观点的信息,忽略反对信息,在数据要素市场里,企业看到同行都在用某类数据做决策,就会觉得“这是对的”,即使数据本身有局限,也不敢尝试新方法。
2026年11月,某新能源汽车企业就遇到了这个问题,他们的电池研发团队一直用“历史故障数据”优化设计,结果新电池的续航提升只有3%,远低于行业平均的5%,后来,他们引入了“跨行业数据”——比如航空发动机的散热数据、手机电池的快充数据,结果发现,这些看似不相关的数据反而能突破技术瓶颈,新电池的续航提升了8%,还申请了3项专利。
本月艺术教育与碳封存及绿色消费热度持续走高,行业关注度持续提升 这个案例背后是行为经济学的“多样性红利”理论:群体的创新能力不取决于成员的平均水平,而取决于成员的差异程度,数据要素市场建设不能只追求“数据量”,还要鼓励“数据多样性”——让不同行业、不同场景的数据交叉碰撞,才能催生真正的创新。
数据要素市场,本质是“人性市场”
2026年的数据要素市场,早已不是简单的“数据买卖”,从定价到共享,从质量到隐私,从创新到竞争,每一个环节都藏着人性的博弈、认知的偏差和群体的行为,行为经济学不是要否定传统经济学,而是要补充那些“理性人假设”无法解释的现实——比如为什么企业宁愿锁数据也不共享,为什么高质量数据卖不上价,为什么用户总是不看隐私政策。
理解这些,我们才能设计出更合理的规则:用“锚定效应”设计定价策略,用“损失兜底”促进数据共享,用“第三方认证”保障数据质量,用“分层授权”保护用户隐私,用“数据多样性”推动创新突破,数据要素市场的未来,不在技术本身,而在对人性的深刻洞察——毕竟,数据是人产生的,最终也要为人服务。