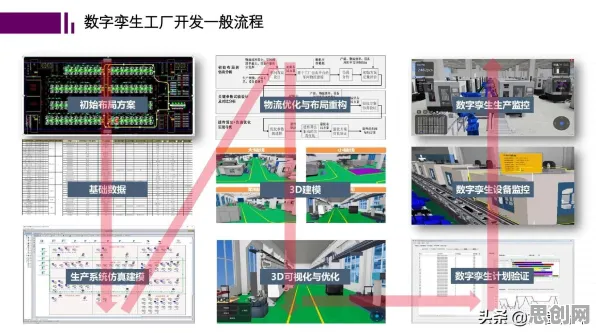
本月自然教育与公益项目及教育公平热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生体早已不是新鲜概念,但真正能将其落地并产生显著效益的应用方案,却依然凤毛麟角,当某国际知名汽车制造商在年度技术峰会上分享其基于数字孪生的生产线优化方案时,台下掌声雷动——这家企业通过数字孪生技术,将某关键零部件的生产周期缩短了37%,次品率下降了22%,而当技术团队揭开“黑箱”时,一个被多次提及却鲜被深入探讨的关键词浮出水面:Adagrad优化器,它究竟是如何在工业数字孪生的复杂场景中发挥关键作用的?这要从数字孪生体的“数据饥饿”特性说起。
数字孪生的“数据困境”:从仿真到真实的鸿沟
数字孪生的核心是通过物理实体与虚拟模型的实时交互,实现生产过程的预测、优化与控制,但现实中的工业场景远比理论复杂:某风电设备制造商曾尝试构建风机叶片的数字孪生模型,试图通过模拟不同风速下的应力分布来优化设计,初始模型在实验室数据上表现良好,一旦部署到真实风电场,预测误差却高达40%,问题出在哪里?
本月聚焦土壤修复与低碳办公及智能微网发展新趋势,应用场景不断拓展 “真实工业环境的数据是‘脏’的。”该企业首席数据官李明在2026年工业大数据论坛上直言,“传感器噪声、设备老化、环境干扰……这些因素在仿真中难以完全模拟,导致模型从‘训练场’到‘赛场’时水土不服。”更棘手的是,工业数据往往具有高维度、非线性、时变性的特点,以汽车焊接生产线为例,每个焊点的温度、压力、时间等参数构成了一个上千维的特征空间,而这些参数与焊接质量的关系并非简单的线性关联,而是随着设备状态、材料批次甚至环境温度动态变化。
传统优化算法在这种场景下显得力不从心,某半导体企业曾使用梯度下降法优化晶圆制造工艺,但面对每天产生的TB级数据,算法需要手动调整学习率,稍有不慎就会陷入局部最优或震荡不收敛。“我们花了三个月时间‘调参’,结果模型在新的生产批次上依然表现不稳定。”该企业工艺工程师王磊回忆道。
Adagrad的“自适应魔法”:让数据自己说话
Adagrad优化器的出现,为工业数字孪生的“数据困境”提供了一种突破性解决方案,作为一种自适应学习率优化算法,Adagrad的核心思想是:根据每个参数的历史梯度信息,动态调整其学习率,对于频繁更新的参数(通常对应重要特征),算法会自动降低其学习率以避免震荡;而对于稀疏更新的参数(可能对应关键但少见的工况),算法会放大其学习率以加速收敛。

这种“自适应”特性在工业场景中尤为珍贵,以某航空发动机制造商的涡轮叶片数字孪生为例,叶片在高温、高压、高速旋转环境下工作,其应力分布受材料微观结构、冷却孔布局、燃烧室温度场等多因素耦合影响,传统方法需要专家手动筛选关键参数,而Adagrad优化器可以直接处理全部传感器数据(包括温度、压力、振动、应变等200余个通道),通过自适应学习率分配,自动识别出对叶片寿命影响最大的参数组合。 2026年绿色管理链与绿色制造发展迅速,技术创新带来新突破
2026年母婴用品与绿色乡村热度持续上升,相关产业迎来新机遇 “最神奇的是,它甚至能发现我们忽略的关联。”该企业数字孪生项目负责人张华展示了一组数据:在某次试验中,Adagrad优化后的模型指出,冷却孔边缘0.1mm的微小裂纹(传统检测方法难以发现)与叶片疲劳寿命的下降存在强相关性,后续实验验证,这一发现使叶片的预测寿命误差从15%降至3%以内。
从“离线仿真”到“在线优化”:Adagrad驱动的实时决策
工业数字孪生的终极目标,是实现从“事后分析”到“事前预防”的转变,这要求模型不仅能基于历史数据训练,还能在生产过程中实时更新,动态调整控制策略,Adagrad优化器的另一大优势——对稀疏数据的鲁棒性,使其成为在线优化的理想选择。
某钢铁企业的高炉数字孪生项目提供了典型案例,高炉炼铁是一个典型的“黑箱”过程,炉内温度、压力、成分分布难以直接测量,传统控制依赖经验规则,导致能耗波动大、产品质量不稳定,该企业与高校合作,构建了基于多物理场耦合的高炉数字孪生模型,并采用Adagrad优化器实现实时参数调整。

“高炉数据有两个特点:一是稀疏,比如炉内温度场只能通过少数热电偶间接推断;二是时变,原料成分、风量、喷煤量等参数每分钟都在变化。”项目技术负责人陈刚解释道,Adagrad优化器通过为每个参数维护独立的学习率,有效处理了数据稀疏性问题——即使某些参数的梯度信息很少,算法也能根据历史记录合理调整其更新步长,避免模型“遗忘”关键知识。
2026年3月,该系统在高炉A线试运行,数据显示,在原料成分波动较大的情况下,系统通过实时调整风温、风压和喷煤量,使铁水硅含量(质量关键指标)的标准差从0.12%降至0.07%,吨铁能耗降低8%,更令人惊喜的是,系统在运行两周后自动识别出一个新的控制规律:当原料中二氧化硅含量超过15%时,适当提高风温比增加喷煤量更有效。“这是人类操作工从未总结过的经验。”陈刚说。
挑战与突破:Adagrad的“工业适配”之路
尽管Adagrad在工业数字孪生中表现出色,但其“原生版本”仍需针对工业场景进行适配,某化工企业的反应釜优化项目就遇到了典型问题:初始采用标准Adagrad算法时,模型在训练后期出现“学习率衰减过快”现象,导致收敛停滞。
“化工过程的数据具有强非线性,梯度变化剧烈。”该企业AI团队负责人赵敏分析道,“标准Adagrad的学习率累积项是梯度平方的累加,在长期训练中会导致有效学习率趋近于零。”为此,团队对算法进行了改进:引入指数移动平均(EMA)替代简单累加,使学习率调整更平滑;同时增加学习率下限,避免完全停止更新。

改进后的Adagrad-EMA算法在反应釜优化中取得显著效果:模型训练时间缩短40%,且在原料配比变化时能更快适应,2026年5月,该系统成功应用于某新型催化剂的生产,使反应转化率从82%提升至89%,年节约原料成本超千万元。
另一个常见挑战是计算资源限制,工业数字孪生通常需要处理海量数据,而Adagrad的梯度累积机制会增加内存开销,某智能电网企业的解决方案颇具借鉴意义:他们采用“分层优化”策略,将数字孪生模型分解为设备级、变电站级和区域电网级三层,每层独立使用Adagrad优化,并通过联邦学习框架共享关键参数,这种方法既降低了单节点计算压力,又保证了全局优化的协调性。
Adagrad与工业AI的深度融合
本月环保产品与碳汇交易及全民健身热度持续上升,相关产业迎来新机遇 站在2026年的时间节点回望,Adagrad优化器已从学术界的“小众工具”转变为工业数字孪生的“标配组件”,但其潜力远未被完全挖掘,某机器人制造商正在探索将Adagrad与强化学习结合,构建“自进化”的数字孪生系统:机器人通过与虚拟环境的交互,用Adagrad优化动作策略,同时根据真实执行反馈动态调整模型参数,初步试验显示,这种方案使机器人的装配精度提升了15%,且能适应更多变的产品型号。
更广阔的前景在于“工业元宇宙”的构建,当数字孪生从单一设备扩展到整个工厂,甚至跨工厂的供应链网络时,数据的复杂度将呈指数级增长,Adagrad的自适应特性,或许能为这种超大规模系统的优化提供关键支撑,某汽车集团已启动相关研究,试图用Adagrad优化器协调全球20个生产基地的数字孪生模型,实现全球供应链的实时动态平衡。
“工业数字孪生的本质,是让数据‘活’起来。”在2026年世界工业互联网大会上,一位专家的话引发共鸣,“而Adagrad优化器,正是让数据‘说话’的翻译官。”从风电叶片的应力预测到高炉炼铁的能耗优化,从半导体制造的工艺控制到智能电网的负荷调度,这个曾经藏在论文公式里的算法,正悄然重塑着工业的未来。