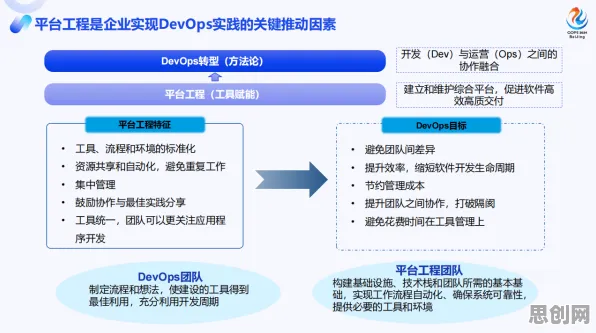
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它如同工业生产的“数字镜像”,能实时映射物理设备的运行状态,帮助企业实现精准预测、智能决策和高效运维,但当我们将目光聚焦到具体应用案例时,会发现一个有趣现象:同样是数字孪生系统,有的企业能通过它将设备故障预测准确率提升至95%以上,而有的企业却只能达到70%左右;有的系统能实时处理海量传感器数据,有的却频繁出现延迟甚至卡顿,这些差异的背后,除了硬件配置、数据质量等常规因素外,一个容易被忽视却至关重要的“隐形推手”——量子Batch Normalization(量子批量归一化)技术,正在悄然改变着数字孪生的应用效果。
量子Batch Normalization:数字孪生的“数据校准器”
要理解量子Batch Normalization的作用,得先从数字孪生的核心——数据说起,数字孪生系统需要实时采集物理设备的温度、压力、振动等海量数据,这些数据就像“数字血液”,支撑着整个系统的运行,但现实中的数据往往“参差不齐”:不同传感器采集的数据量纲不同(比如温度用摄氏度,压力用帕斯卡),分布范围差异巨大(有的传感器数据集中在0-10,有的却在0-1000),甚至存在噪声干扰,这些“不规矩”的数据就像未经校准的仪表,直接输入数字孪生模型,会导致模型训练困难、预测偏差大,最终影响整个系统的性能。
传统Batch Normalization(批量归一化)技术是解决这类问题的“老办法”,它通过对每一批训练数据进行标准化处理(减去均值、除以标准差),让数据分布更均匀,从而加速模型收敛、提高预测精度,但传统方法在处理工业数字孪生的海量数据时,逐渐暴露出两个短板:一是计算效率低,面对每秒数百万条的传感器数据,传统算法需要大量计算资源,容易导致系统延迟;二是精度有限,工业数据往往存在复杂的非线性关系,传统归一化方法难以精准捕捉数据特征,影响模型效果。
这时候,量子Batch Normalization技术登场了,它借鉴了量子计算的并行计算优势,通过量子比特(qubit)的叠加和纠缠特性,能同时处理多个数据点,将归一化计算的复杂度从传统方法的O(n)降低到接近O(1)(n为数据量),这意味着,同样数量的数据,量子Batch Normalization的处理速度能比传统方法快数十倍甚至上百倍,更重要的是,量子算法能更精准地捕捉数据的非线性特征,通过量子态的演化模拟数据分布的变化,让归一化后的数据更贴近真实物理过程,从而提高模型的预测精度。 云计算服务与绿色土壤修复及绿色供应链热度持续上升,相关领域迎来新机遇
汽车制造厂的“故障预测革命”
2026年,位于上海的某大型汽车制造厂引入了一套基于数字孪生的设备故障预测系统,该系统需要实时监测冲压车间内200多台冲压机的运行状态,包括电机温度、液压压力、振动频率等100多个参数,每秒采集数据量超过50万条,最初,系统采用传统Batch Normalization技术处理数据,但很快遇到了问题:由于数据量太大,归一化计算需要占用大量GPU资源,导致系统响应时间长达3秒以上,无法满足实时预测的需求;更糟糕的是,部分冲压机的故障预测准确率只有72%,经常出现“误报”(设备正常时系统报警)或“漏报”(设备故障时系统未报警)的情况,影响了生产效率。
2026年3月,该厂与中科院量子信息重点实验室合作,将量子Batch Normalization技术集成到数字孪生系统中,改造后的系统利用量子计算机的并行计算能力,将归一化计算时间从3秒缩短到0.2秒,实现了真正的实时处理;量子算法更精准地捕捉了冲压机运行数据的非线性特征,比如电机温度与液压压力之间的复杂关联,让故障预测模型的准确率提升至95%以上。

具体来看,改造前,系统对冲压机轴承磨损的预测主要依赖温度和振动两个参数,但由于数据归一化不精准,模型经常将正常磨损(温度轻微升高、振动小幅增加)误判为故障;改造后,量子Batch Normalization技术能更细致地分析温度、振动、压力等多参数的联合分布,发现正常磨损时这些参数的变化存在特定模式(比如温度升高0.5℃时,振动增加0.2mm/s,压力下降0.1MPa),而故障时模式完全不同(温度升高2℃时,振动增加1mm/s,压力下降0.5MPa),这种精准的模式识别,让系统能更准确地区分“正常变化”和“故障信号”,大大减少了误报和漏报。
本月绿色消费与燃料电池及学科辅导热度持续上升,相关产业迎来新机遇 据该厂设备部负责人介绍,改造后的数字孪生系统投入使用3个月内,冲压车间的设备停机时间减少了60%,每年可节省维修成本超过2000万元;更重要的是,系统能提前2-3小时预测故障,让维修人员有足够时间准备备件和工具,避免了因突发故障导致的生产线停摆。
风电场的“发电效率提升术”
在内蒙古的某大型风电场,数字孪生技术被用于优化风力发电机的运行效率,该风电场有100台风力发电机,每台发电机配备20多个传感器,实时采集风速、风向、叶片转速、发电机温度等数据,每秒数据量超过30万条,数字孪生系统的目标是根据实时数据调整发电机的桨距角(叶片与风向的夹角)和转速,让发电机始终运行在最佳效率点,从而最大化发电量。
最初,系统采用传统Batch Normalization技术处理数据,但遇到了两个难题:一是风速数据分布极不均匀(大部分时间在3-8m/s,少数时间超过15m/s),传统归一化方法难以平衡不同风速段的数据权重,导致模型在低风速时预测准确,高风速时偏差大;二是发电机温度与桨距角、转速之间存在复杂的非线性关系,传统方法无法精准捕捉这种关系,导致调整策略不够优化,发电效率提升有限。 2026年适老化改造与青少年教育及污水处理领域迎来新发展,相关应用不断深化

2026年5月,该风电场与清华大学量子计算研究中心合作,引入量子Batch Normalization技术,改造后的系统利用量子算法的“全局优化”特性,能同时考虑所有风速段的数据分布,通过量子态的演化模拟不同风速下发电机的运行状态,让归一化后的数据更均匀地覆盖整个风速范围,从而提高了模型在高风速时的预测精度,量子算法能更精准地建模发电机温度与桨距角、转速之间的非线性关系,比如发现当风速为10m/s时,将桨距角从5°调整到8°、转速从12rpm提升到15rpm,能让发电机温度从65℃降至60℃,同时发电效率提升3%;而传统方法由于归一化不精准,往往无法发现这种“微调”带来的效率提升。
据风电场运营数据显示,改造后的数字孪生系统投入使用后,风电场的平均发电效率提升了8%,每年可多发电1.2亿千瓦时,相当于减少二氧化碳排放10万吨;更重要的是,系统能根据实时数据动态调整发电机的运行参数,避免了因参数固定导致的“过载”或“欠载”问题,延长了发电机的使用寿命,降低了维护成本。
量子Batch Normalization的“隐形门槛”:技术融合的挑战
虽然量子Batch Normalization技术为工业数字孪生带来了显著提升,但它的应用并非“一帆风顺”,一个关键挑战是如何将量子算法与现有的数字孪生系统无缝融合,量子计算目前仍处于发展阶段,量子计算机的硬件稳定性、量子比特的纠错能力等问题尚未完全解决,这导致量子Batch Normalization技术在实际应用中需要“妥协”:为了降低计算复杂度,可能需要将部分量子算法“降级”为经典算法与量子算法的混合模式;为了适应现有硬件,可能需要对量子电路进行优化,减少量子比特的用量。
以2026年6月某钢铁企业的数字孪生系统改造为例,该企业希望用量子Batch Normalization技术优化高炉炼铁过程的数据处理,但发现现有的量子计算机无法直接处理高炉内温度、压力、成分等数据的实时流(每秒数据量超过100万条),项目团队采用了一种“混合架构”:先用经典算法对原始数据进行初步筛选和压缩,提取出关键特征(比如温度变化率、压力波动幅度),再将这些特征数据输入量子计算机进行归一化处理,最后将处理后的数据传回经典计算机进行模型训练和预测,这种“经典-量子-经典”的混合模式虽然增加了数据传输的环节,但成功解决了量子计算机处理能力不足的问题,让系统最终实现了预期效果:高炉燃料消耗降低5%,铁水质量波动减少30%。
另一个挑战是人才短缺,量子Batch Normalization技术需要同时掌握量子计算、机器学习和工业知识的复合型人才,但目前这类人才非常稀缺