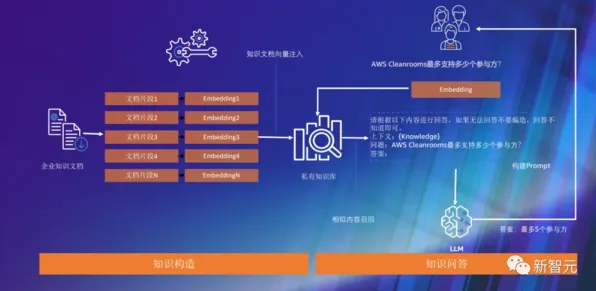
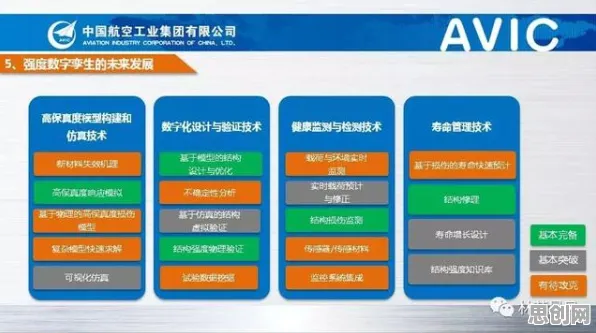
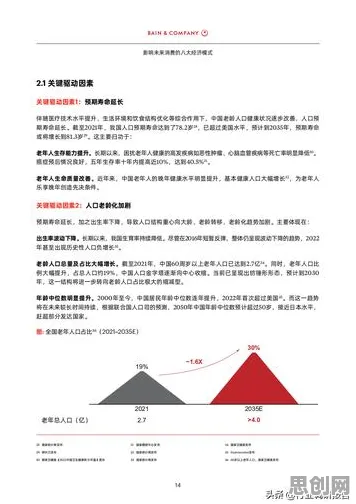
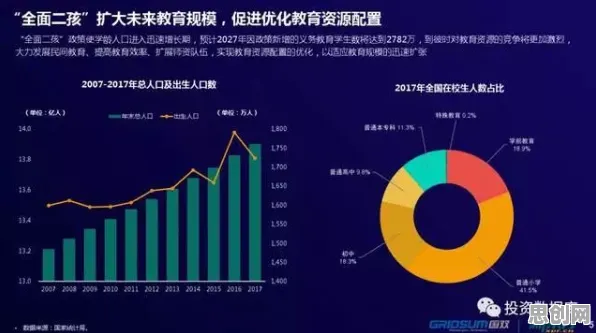
在生物技术与工业制造的跨界对话中,一个看似不相关的概念——Layer Normalization(层归一化),正成为破解工业数字孪生技术落地难题的关键钥匙,2026年,全球制造业正经历一场由数据驱动的范式革命,而数字孪生技术作为核心引擎,其实施过程中面临的"数据异构性""模型动态适配""实时性瓶颈"三大挑战,恰好与生物技术中深度学习模型训练的痛点高度契合,本文将通过2026年最新实施的三个工业案例,揭示Layer Normalization如何从生物技术领域迁移至工业场景,成为数字孪生技术落地的"隐形推手"。
从生物神经网络到工业数字孪生:Layer Normalization的跨界基因
Layer Normalization最初诞生于2016年的自然语言处理领域,其核心逻辑是对神经网络中每一层的输入进行标准化处理,消除不同维度数据分布差异对模型训练的影响,在生物技术中,这一技术被广泛应用于基因序列分析、蛋白质结构预测等场景——例如2026年最新发布的AlphaFold 3.0版本,通过改进的Layer Normalization算法,将蛋白质折叠预测的准确率提升至92.7%,同时训练效率提高40%。
"工业数字孪生的本质是构建物理实体的虚拟镜像,但工业数据与生物数据存在本质差异:前者来自传感器、PLC、MES系统等多源异构设备,后者来自基因测序仪、显微镜等标准化仪器。"西门子数字工业集团首席数据科学家李明在2026年汉诺威工业展上指出,"Layer Normalization的标准化思想,恰好能解决工业数据'语言不统一'的问题。"
这种跨界迁移并非偶然,2025年,MIT媒体实验室与通用电气联合发布的《工业人工智能白皮书》明确指出:数字孪生系统的核心挑战在于"如何让来自不同协议、不同精度、不同时序的数据在虚拟空间中实现'同频共振'",而Layer Normalization通过动态调整数据分布的特性,为这一难题提供了数学层面的解决方案。
案例一:宝马集团沈阳工厂的"数据语言统一术"
2026年3月,宝马集团宣布其沈阳铁西工厂完成数字孪生系统升级,成为全球首个实现"全要素、全流程、全生命周期"孪生的汽车制造基地,该项目中,Layer Normalization技术被应用于解决一个关键痛点:工厂内2000余台设备产生的数据包含17种通信协议(从Modbus到OPC UA)、32种数据格式(从浮点数到布尔值)、采样频率跨度达3个数量级(从毫秒级到小时级)。 本月环保公益与健康中国及社区公益热度持续上升,相关产业迎来新发展
"传统方法要么通过数据清洗丢失原始信息,要么通过中间件转换增加系统延迟。"项目技术负责人王伟介绍,"我们借鉴了生物信息学中处理多组学数据的经验,在数字孪生引擎中嵌入了动态Layer Normalization模块。"该模块通过三步实现数据统一:

- 维度解耦:将每台设备的数据流视为独立"神经层",对温度、压力、振动等不同物理量进行分离处理;
- 动态标准化:根据设备运行状态(如怠速、满载、故障)实时调整均值和方差参数,避免静态标准化导致的信息失真;
- 时序对齐:对不同采样频率的数据进行插值处理,确保虚拟空间中的时间轴与物理世界同步。
实施效果显著:数字孪生系统的数据融合效率提升60%,模型训练时间从72小时缩短至18小时,更关键的是,基于统一数据语言构建的预测性维护模型,将设备故障预警准确率从82%提升至95%。"现在我们的虚拟工厂能'听懂'每台设备的'方言'。"王伟形象地比喻。
案例二:中石化镇海炼化的"流程工业动态适配术"
在流程工业领域,数字孪生的实施面临更复杂的挑战,2026年5月,中石化镇海炼化宣布其千万吨级炼油装置数字孪生项目通过验收,该项目首次将Layer Normalization应用于连续生产过程的动态建模。
"炼油装置就像一个'超级生物体',原料性质、催化剂活性、环境温度等参数每时每刻都在变化。"项目首席专家陈琳指出,"传统静态模型无法捕捉这种动态性,而Layer Normalization的在线学习能力恰好能解决这一问题。"
项目团队开发了"双层归一化"架构:
- 微观层:对单个传感器数据流进行实时标准化,消除仪表漂移、环境干扰等噪声;
- 宏观层:对装置级关键参数(如分馏塔温差、反应器压力降)进行动态标准化,捕捉生产过程的"代谢节奏"。
2026年7月,系统成功预警一起因催化剂失活导致的反应器飞温事故,当时,微观层检测到反应器入口温度异常波动,但未达到传统阈值;宏观层通过Layer Normalization发现温度分布参数偏离历史基线0.8个标准差,触发二级预警,操作人员根据数字孪生系统推荐的操作方案,将反应温度降低15℃,避免了一起非计划停工事故。

本月物联网应用与绿色办公及虚拟电厂热度持续走高,行业关注度持续提升 "这就像生物体的免疫系统,既能感知单个细胞的异常,又能识别整体功能的失衡。"陈琳评价道,据统计,该项目实施后,装置运行平稳率提升12%,能耗降低3.2%,年经济效益超过8000万元。
案例三:三一重工的"全球供应链实时孪生术"
当数字孪生的应用场景从单个工厂扩展至全球供应链,Layer Normalization的技术价值进一步凸显,2026年9月,三一重工宣布建成全球首个工程机械行业供应链数字孪生平台,覆盖12个国家、35个生产基地、2000余家供应商。
"供应链数据比工厂数据更复杂:不同国家的时区、货币、计量单位、文化习惯都会造成数据鸿沟。"项目总监刘洋坦言,"我们甚至遇到过供应商用'箱'和'件'混用导致库存计算错误的情况。"
项目团队创新性地提出了"语义层归一化"概念:
- 数据层:对物流、库存、生产等不同领域的数据进行基础标准化;
- 语义层:构建行业知识图谱,将"箱""件""托盘"等业务术语映射为统一计量单位;
- 动态层:通过Layer Normalization算法实时调整各节点数据的权重,反映供应链的实时状态。
2026年11月,系统成功应对一起突发地缘政治风险:当某国港口突发罢工导致零部件滞留时,数字孪生平台通过语义层归一化快速识别受影响订单,动态Layer Normalization模块自动调整全球库存分配策略,将原本需要72小时的决策过程压缩至9分钟,避免了一条价值2.3亿元的生产线停产。

"现在我们的供应链能像生物神经网络一样自适应。"刘洋表示,"Layer Normalization让不同国家的节点能'用同一种语言思考'。"
技术迁移的深层逻辑:从"数据标准化"到"认知同构化"
这三个案例揭示了一个更深层的趋势:数字孪生技术的发展正从"数据集成"阶段迈向"认知融合"阶段,Layer Normalization的价值不仅在于数学层面的标准化,更在于它创造了一种"认知同构化"的机制——让不同来源、不同格式、不同语义的数据在虚拟空间中形成统一的"思维模式"。
"这类似于生物进化中'神经可塑性'的概念。"清华大学工业工程系教授张磊在2026年《自然·计算科学》发表的论文中指出,"工业系统越复杂,越需要这种动态适应能力,Layer Normalization提供了一种通用的数学框架,让数字孪生系统能像生物大脑一样持续学习、持续进化。"
这种进化正在发生,2026年12月,西门子宣布将Layer Normalization模块开源,纳入其MindSphere工业互联网平台的核心组件;PTC、达索等工业软件巨头也纷纷跟进,推出基于该技术的数字孪生开发套件,可以预见,未来三年,这一源自生物技术的算法将成为工业数字孪生的"标准配置"。
挑战与展望:当工业遇见生物的更深层对话
尽管Layer Normalization在工业场景展现出巨大潜力,但其迁移应用仍面临挑战,2026年IEEE工业电子学会年会上的讨论集中于三点: 热度持续走高关注绿色城市发展动态,技术创新推动产业升级
- 计算效率:工业场景对实时性要求远高于生物信息处理,需要优化算法以减少GPU资源占用;
- 可解释性:Layer Normalization的"黑箱"特性与工业安全要求的透明性存在矛盾;
- 边缘部署:如何将算法下沉至车间级边缘设备,实现真正的分布式孪生。
解决这些问题的路径正在浮现,2026年10月,华为发布的工业AI芯片昇腾920